Introduction au génie informatique
Ce cours est une introduction au génie informatique axé sur les outils, les pratiques et les connaissances de base en génie informatique.
Ce cours utilise Java comme langage d’étude pour sa clarté conceptuelle.
Types d’apprentissage
🛠️ Compétences en génie informatique
Dans chaque unité, vous développerez un savoir-faire en lien avec le génie informatique. Ces compétences sont évaluées au moyen de projets concrets.
Les leçons sur une compétence sont dénotées par le symbole : 🛠️
📚 Concepts
Dans chaque unité, vous apprendrez aussi des nouveaux concepts. Le plus de concepts que vous maîtrisez, le plus que vous alimenter vos compétences pour produire des choses intéressantes. Les concepts sont évalués au moyen de quiz sur papier et d’entrevues
Les leçons sur un concept sont dénotées par le symbole : 📚
Unités
Partie A : Fonctionnement de l’ordinateur
Définitions fondamentales pour le reste du cours
Comment les machines exécutent des algorithmes
Comment les utilisateurs et les applications utilisent le matériel informatique
Partie B : Programmation
Préparer l’environnement de développement
Installer, configurer et tester les logiciels pour la programmation
Les éléments de base du langage Java
Découper un problème en sous-problèmes et comment l’implémenter dans un programme
Comment contrôler l’exécution d’un programme - le rendre intelligent et puissant
Mieux gérer et manipuler les données dans un programme
Se familiariser avec les technologies utilisées pour programmer des applications dans une variété de domaines
Accueil >
Partie A - Fonctionnement de l’ordinateur
Légende : 🛠️ 📚
-
🛠️Compétences en génie informatique
Savoir-faire en lien avec le génie informatique. Les compétences sont évaluées au moyen de projets concrets.
Développez ces compétences avec les exercices pratiques dans chaque leçon.
-
📚 Concepts
Nouveau concept. Le plus de concepts que vous maîtrisez, le plus que vous alimenter vos compétences pour produire des choses intéressantes. Les concepts sont évalués au moyen de quiz sur papier et d’entrevues.
Validez votre compréhension avec les mini quiz dans chaque leçon.
Algorithmes
Sommaire
Comment dire à une machine comment afficher une image et l’animer, comme dans une vidéo ou un jeu? Est-ce qu’il y a une façon de communiquer qui est assez simple et claire que même une machine à base de 1 et de 0 est en mesure de le comprendre?
La réponse est “oui” : c’est le domaine des algorithmes et du génie informatique. C’est la première étape à maîtriser : un nouveau niveau et type de communication formelle.
Lien avec l’éthique, la société ou les carrières
💭 Quelques pistes de réflexion :
- Quel pourcentage des informations que vous consommez de façon volontaire (vidéos, annonces, articles, etc.) sont suggérées par un algorithme? Savez-vous comment ces algorithmes prennent leurs décisions?
- Durant le développement d’un produit ou service technologique, qui a la chance de décider des valeurs et des priorités qui sont incorporées dans le produit? Comment est-ce que ces décisions affectent les utilisateurs?
Leçons
Matériel
Sommaire
L’unité précédente a introduit un langage formel pour décrire une série d’étapes : l’algorithme. Dans cette unité, nous allons voir comment ces algorithmes sont exécutés par un ordinateur. Vous ne deviendrez pas experte en électronique mais vous saurez comment un simple état binaire (haute/basse tension) peut-être manipulé une couche de complexité à la fois dans des circuits pour donner toute la logique et la mémoire nécessaire pour exécuter n’importe quel algorithme valide.
Du côté plus pratique et concret, vous apprendrez comment ces circuits se traduisent en composants communs, comme le processeur et la mémoire, et comment ces composants sont assemblés pour former un ordinateur. Vous apprendrez comment la performance de ces composants et celle de divers périphériques se mesure et comment ces informations sont utilisées pour comparer les ordinateurs entre eux.
Lien avec l’éthique, la société ou les carrières
💭 Quelques pistes de réflexion :
- Combien d’énergie est nécessaire pour exécuter des algorithmes importants dans la société moderne, comme une recherche sur Google ou pour développer et utiliser un modèle comme ChatGPT?
- Comment est-ce que les matériaux utilisés dans les composants électroniques sont extraits et traités? Quels sont les impacts environnementaux de ces activités? Comment est-ce que les gens qui travaillent dans ces industries sont traités?
Leçons
Logiciels du système
Sommaire
Les deux premières unités traitent de la nature d’un algorithme et de la circuiterie physique utilisée pour créer une machine qui peut exécuter ces algorithmes.
Cette unité fait le pont entre l’ordinateur et les utilisateurs. D’un côté du pont, il y a la machine, l’ordinateur. Ici, nous voyons comment le système binaire (1/0) est utilisé pour représenter différents types de données et pour représenter des instructions. Cela devient la première communication humain-machine possible : le langage machine. Sachant que c’est possible d’encoder des instructions et des informations dans un langage machine, on peut imaginer l’encodage d’algorithmes complets, et même de logiciels complets. De l’autre côté du pont, nous voici, des utilisateur humains réguliers qui veulent utiliser l’ordinateur pour faire des choses utiles. Nous avons besoin d’un moyen convivial de communiquer avec l’ordinateur, et c’est là que les systèmes d’exploitation et les interfaces utilisateur entrent en jeu. Ces logiciels du système traduisent des gestes humains en langage machine sans qu’on le remarque. Il nous suffit de savoir comment utiliser les logiciels qui sont disponibles pour faire ce qu’on veut faire.
Comme ingénieurs informatiques en herbe, vous aurez à explorer les deux côtés du pont et d’aller plus loin dans le type de logiciel que vous utilisez. Vous apprendrez comment installer des logiciels, comment les utiliser, et comment les configurer pour vos besoins.
Lien avec l’éthique, la société ou les carrières
💭 Quelques pistes de réflexion :
- La plupart des systèmes d’exploitation associent des applications critiques, comme les navigateurs web et la messagerie, au système d’exploitation lui-même. Quels sont les avantages et les inconvénients de cette approche pour l’utilisateur? Qui profite de ces inconvenients?
- Plusieurs logiciels sont développés selon le modèle de logiciel libre et open source. Quels sont les avantages et les inconvénients de ce modèle :
- pour les utilisateurs?
- pour les développeurs?
- pour les entreprises?
Leçons
Accueil > 1-Algorithmes >
📚 Algorithmes
Survol et attentes
Est-ce que vous parlez de la même façon à vos amis, à un très jeune membre de votre famille, à vos parents ou grands-parents quand vous leur demandez quelque chose? Probablement pas, entre autres, parce que le vocabulaire et les connaissances de chacun sont différents. La même chose s’applique pour demander quelque chose à un ordinateur.
Définitions
Algorithme : En informatique, un algorithme est un processus qui décrit ou qui transforme de l’information. Les algorithmes valides sont des collections bien ordonnées d’étapes réalisables et sans ambiguïté et qui produisent un résultat dans un temps fini.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure :
- de décrire les différents domaines associés aux études informatiques;
- d’identifier les critères d’un algorithme valide.
Critères de succès
- Je peux écrire un algorithme valide en langage naturel (aussi appelé “pseudocode”).
- Je peux juger si une séquence d’étapes est un algorothme valide ou non.
Notes
Introduction aux études informatiques
Définition d’un algorithme
Exercices
📚 Tester la compréhension
aucun quiz de vérification des concepts ici encore
🛠️ Pratique
- Selon les listes des domaines d’études informatiques et des domaines associés, faites une courte recherche sur deux domaines que vous n’avez pas considérez jusqu’à présent mais qui vous semblent intéressants. Une courte recherche inclut, p. ex. :
- Une brève description
- Si on peut commencer les études/le travail dans le domaine spécifique directement après le secondaire ou si on fait des études dans un programme général avant de se spécialiser dans ce domaine
- Des exemples récents d’innovations dans le domaine
- Écrivez un algorithme pour laver la vaisselle qui correspond entièrement à la définition d’un algorithme (bien ordonnée, sans ambiguïté, réalisable, produit un résultat, s’arrête).
Accueil > Algorithmes >
🛠️ Abstraction
Survol et attentes
Définitions
Selon ce qui est important pour notre analyse, on tend juste à regarder un niveau de détail, le niveau le plus superficiel possible, et d’ignorer tous les détails internes. Le niveau de détail observé s’appelle un niveau d’abstraction. Chaque fois qu’on cache des détails en formant un modèle simplifié, on a ajouté une couche d’abstraction.
Abstraction : Une abstraction est une simplification d’un concept ou d’un objet. L’abstraction devient un modèle emballant et masquant les détails complexes du fonctionnement interne. En informatique, il y a plusieurs couches d’abstraction, tant pour les programmes (les algorithmes) que pour le matériel qui implémentent les algorithmes.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Définir le terme abstraction
- Relativiser deux niveaux d’abstraction d’un concept : identifier le plus bas niveau et le plus haut niveau
Critères de succès
- Je peux décrire le niveau d’abstraction directement inférieur au mécanisme que j’étudie, p. ex.: les transistors si j’étudie les portes logiques ou le système d’exploitation si j’écris un programme Java.
Notes
Les couches d’abstraction sont fondamentale pour permettre aux gens de travailler efficacement sur différents problèmes.
Un exemple sont les domaines de la science : la physique qui traite des interactions un-à-un entre les particules, la chimie qui traite des interactions entre les atomes et les molécules et la biologie qui traite des interactions entre les cellules et les organismes. Si on veut étudier le comportement des chauves-souris, la physique n’est pas le bon niveau d’abstraction : l’analyse des particules serait trop complexe, sans nous donner facilement de l’information utile. La biologie est le bon niveau d’abstraction car elle s’intréresse aux systèmes directement.
Voici les couches d’abstraction que nous aborderons en lien avec la structure d’un ordinateur dans ce cours.
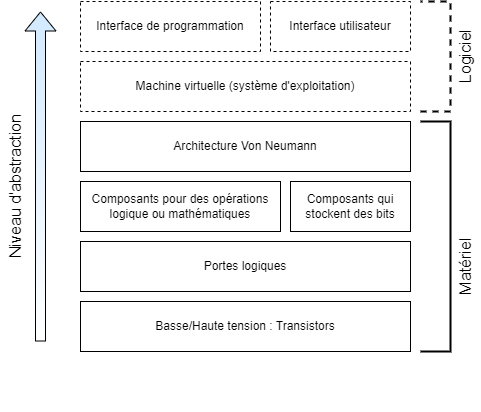
Voici les couches d’abstraction que nous aborderons en lien avec les structures algorithmiques dans ce cours.
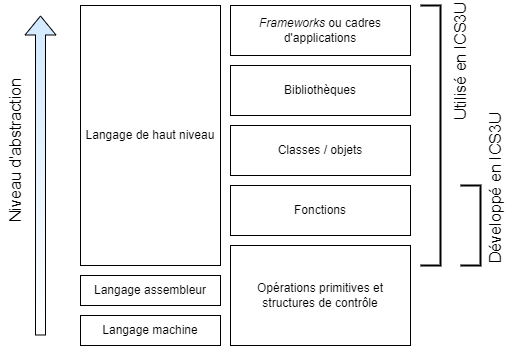
Exercices
📚 Tester la compréhension
aucun quiz de vérification des concepts ici encore
🛠️ Pratique
- En développant une habilité - par exemple, en sports, en arts ou en artisanat - vous devez souvent passer par des cycles d’abstraction : découper l’habilité en morceaux, intégrer les éléments de base pour arriver à une technique fluide, puis intégrer la nouvelle technique dans un contexte ou séquence plus grand. Ultimement vous êtes en mesure de réaliser la technique sans réfléchir aux détails, ce qui correspond à notre concept d’abstraction. Décrivez un exemple de ce processus d’abstraction dans votre vie.
Accueil > 1-Algorithmes >
🛠️ Cas d’utilisation
Survol et attentes
Définitions
Cas d’usage : Un cas d’usage est un document qui analyse comment un produit ou un service sera utilisé. Ce type de document doit être compréhensible par toutes les parties prenantes. Il sert alors de point de connexion entre les différentes parties prenantes et guide le développement technique du produit ou service.
Partie prenante / Acteur : Une personne qui est affectée par le développement du produit ou service. Les parties prenantes peuvent être des utilisateurs, des gérants, des développeurs, des investisseurs, etc.
Public cible : Les personnes qui utiliseront le produit ou service. Le public cible est souvent divisé en plusieurs groupes, chacun ayant des besoins spécifiques.
Flux : séquence d’événements
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- énumerer les éléments d’un cas d’usage, notamment le public cible, les acteurs, les objectifs, les conditions préalables, les flux et les conditions de sortie;
- distinguer les flux de base, alternatifs et exceptionnels d’un cas d’usage
Critères de succès
- Je peux rédiger un cas d’usage pour une technologie ou un processus que je développe.
- Je peux adapter les flux aux besoins des acteurs.
But des cas d’usage
Les cas d’usage se concentrent sur les utilisateurs du système plutôt que sur le système lui-même. Un cas d’usage doit être compréhensible par toutes les parties prenantes, pas seulement les développeurs et les testeurs. Cela inclut les clients, les utilisateurs et les dirigeants. Ainsi le texte d’un cas d’usage est plutôt narratif que technique.
Une des meilleures justifications pour la création de cas d’utilisation est qu’ils servent de véritables points de connexion. Si bien rédigés, ils peuvent être compris par toutes les parties prenantes qui peuvent alors ajouter leurs commentaires et suggestions avant que le développement ne commence. Cela permet de s’assurer que le produit ou service répondra aux besoins de tous les utilisateurs.
Comment rédiger un cas d’usage
Pour rédiger un cas d’usage, procédez comme suit :
- Déterminer le public cible du produit et le décrire en détail
- Nommer toutes les parties prenantes et sélectionnez un membre de cette liste comme acteur principal. Pour des projets d’informatique du point de vue des développeurs, l’acteur principal est souvent un utilisateur du système.
- Déterminez exactement ce que l’utilisateur souhaite faire avec le produit (son objectif). On devrait créer un cas d’usage pour chaque objectif.
- Décrivez les conditions préalables à l’utilisation du produit ou du service. Par exemple, est-ce qu’un équipement spécial est nécessaire? Est-ce que l’utilisateur doit être connecté à Internet?
- Déterminer le flux typique d’événements pour une session ou l’acteur principal atteint son objectif. Cela ressemble généralement, pour les produits informatiques, à plusieurs cycles d’une action de l’utilisateur suivie par une réponse du système.
- Envisager d’autres usages normaux possibles et les décrire comme flux alternatifs.
- Envisager également des situations anormales (p. ex.: des bris ou des erreurs) et les décrire comme flux exceptionnels.
- Finalement, décrivez les conditions de sortie qui suivent l’usage normal par l’utilisateur, p. ex.: l’enregistrement des données.
Idéalement, après la rédaction d’un cas d’usage, on aurait une discussion avec les parties prenantes pour obtenir des commentaires et des suggestions pour ajuster d’avantage les flux et les conditions afin de mieux répondre aux besoins de chacun.
Exemples
Exemple d'un cas d'usage non informatique
Le but de ce cas d’usage est de vérifier si un service de buanderie externe a la capacité requise pour nettoyer et remplacer, au besoin, le linge d’un restaurant une fois par semaine.
Public cible
Employés et clients d’un restaurant (qui utilisent le linge propre)
Acteurs
Employés de cuisine, serveurs, gérants, clients, service de buanderie
Acteur principal — service de buanderie
Objectif
Nettoyer les uniformes et le linge divers du restaurant chaque semaine
Conditions préalables
C’est un vendredi et il y a du linge sale dans le bac de la buanderie
Flux
Le flux de base pour cet exemple de cas d’usage est le suivant :
- Le service de buanderie vient au restaurant le vendredi et collecte le linge sale.
- De retour à la buanderie, le service trie le linge disponible.
- Le service nettoie et sèche chaque charge.
- Le service repasse les uniformes, les nappes et les serviettes de table.
- Le service plie les articles qui doivent être pliés et accroche les autres sur des cintres.
- Le service retourne le linge propre au restaurant le vendredi pour le service du soir.
Flux alternatifs :
- Basse inventaire : Si un gérant signale une basse inventaire d’un item spécifique lors de la collecte, le service de buanderie ajoute la quantité d’items manquante aux items propres avant de retourner le linge au restaurant.
- Vêtements encore sales : Le service de buanderie relave tout ce qu’elle trouve encore sale.
Flux exceptionnels :
Voici quelques exemples de flux exceptionnels :
- Vêtement abîmé : Le service de buanderie trouve un item déchiré. Il le signale à un gérant qui décide de le réparer ou de le remplacer.
- Machine en panne : La machine à laver est en panne. Le service de buanderie signale le bris (et le retard du service) au gérant du restaurant et initie la procédure de réparation.
- Manque de linge propre avant le vendredi : Le gérant tente d’organiser un service additionnel pour le linge sale un autre jour de la semaine.
Conditions de sortie :
- Le nombre d’items propres plus les nouveaux items est enregistré dans un registre avant que le linge quitte la buanderie.
- Le gérant du restaurant signe le registre pour confirmer la réception du linge propre.
Exemple d'un projet informatique (un jeu d'aventure textuel)
Le programme est un jeu d’aventure textuel dans lequel vous vous promenez à la découverte d’objets. Les descriptions de chaque zone du jeu sont légèrement humoristiques, tout comme celles des objets que vous ramassez. Vous pouvez sauvegarder votre progression afin de ne pas avoir à collecter tous les objets depuis le début à chaque fois que vous jouez.
Public cible
Ce jeu pourrait intéresser les personnes qui n’aiment pas les jeux violents ou qui sont anxieuses car il n’y a pas de conflit dans le jeu, juste de la découverte.
La tranche d’âge est probablement celle des préadolescents et plus car l’interface textuelle nécessite beaucoup de lecture.
L’intégration de texte en couleur pourrait contribuer à rendre le programme plus lisible.
La version initiale est conçue uniquement en français, mais des versions futures pourraient être développées dans d’autres langues, comme l’anglais, car la plupart des informations textuelles sont stockées dans des fichiers extérieurs à la logique qui seraient faciles à traduire.
L’humour est une chose très personnelle et est lié à nos références culturelles, il peut donc ne pas être aussi efficace avec tout le monde. Encore une fois, il est susceptible de fonctionner mieux avec les préadolescents et les adolescents. Il doit plaire aux utilisateurs masculins et féminins, donc ne pas avoir de styles d’humour qui ne soient offensants pour aucun sexe.
Acteurs
Ceci peut être un jeu indépendant, alors les acteurs impliqués pour le réaliser sont juste le(s) développeur(s)/entrepreneur(s) et les utilisateurs.
Notre acteur principal est un adolescent de la 10e à la 12e année qui s’intéresse aux ordinateurs.
Objectif
L’utilisateur joue à un nouveau jeu.
Conditions préalables
L’utilisateur devra avoir accès à un ordinateur et à un interpréteur Python, soit localement, soit en ligne.
Flux de base
L’utilisateur lance le jeu → Les fichiers de données du jeu sont lus dans les structures de données de la mémoire du programme → Un message de bienvenue s’affiche à l’utilisateur et lui demande de charger une partie, de démarrer une nouvelle partie ou de quitter → l’utilisateur choisit une nouvelle partie → le nom du premier emplacement, la description, la navigation et d’autres options s’affichent avec une invite de saisie → l’utilisateur tape son choix → le jeu analyse le choix pour déterminer la nature de l’option et met à jour l’état du jeu en conséquence → … cela continue jusqu’à ce que l’utilisateur atteigne la fin du jeu → un message de sortie s’affiche à l’utilisateur → le programme se termine.
Flux alternatifs : sauvegarde et sortie
Il existe un emplacement dans le jeu où l’utilisateur peut aller pour sauvegarder et quitter le jeu avant de terminer.
S’il y va et choisit cette option → le jeu enregistre son inventaire dans un fichier → il ajoute également ce fichier à une liste de parties sauvegardées dans un fichier journal.
L’utilisateur relance le jeu et choisit l’option de chargement → les fichiers de données du jeu sont lus dans les structures de données de la mémoire du programme → le fichier de données utilisateur est lu en mémoire et l’état du jeu est mis à jour en conséquence → le joueur commence plus loin dans le jeu.
Flux alternatifs : quitter
Il existe un emplacement dans le jeu où l’utilisateur peut se rendre pour quitter le jeu avant de le terminer.
Il s’y rend et choisit l’option quitter → le jeu affiche simplement l’écran de fin et se ferme.
Flux d’exception : saisie utilisateur non valide
L’utilisateur tape un choix incorrect ou incompréhensible → le programme revient en arrière et demande à nouveau une réponse valide → ce cycle continue jusqu’à ce que l’utilisateur donne une réponse reconnaissable.
Flux d’exception : données de jeu non valides
Le fichier de données du jeu peut contenir des séquences de navigation incompatibles qui n’ont pas été découvertes lors des tests → l’utilisateur choisit l’une de ces options de navigation → le jeu génère une erreur et se ferme.
Conditions de sortie
Les données utilisateur sont enregistrées dans un fichier, si l’utilisateur le souhaite, et son fichier est ajouté à un fichier journal de jeu.
Références additionnelles
- Blog sur le sujet du point de vue des gestionnaires de produit
- Bridging the Gap : un site qui explique les cas d’usage en détail
Exercices
📚 Tester la compréhension
aucun quiz de vérification des concepts ici encore
🛠️ Pratique
- Il y a un projet formatif en lien avec cette leçon. Voir les instructions dans le Classroom.
📚 Portes logiques
Survol et attentes
Les algorithmes sont une séquence d’étapes ou d’instructions pour résoudre un problème spécifique. Il nous faut maintenant une machine pour exécuter ces instructions afin de rendre l’exécution des algorithmes plus automatique et rapide. Le mécanisme de base utilisé pour implémenter les données, la logique et les opérations s’appelle une porte logique.
Définitions
- Binaire
- système où il existe seulement deux valeurs, comme haute/basse tension, 0/1, vrai/faux.
- Logique booléenne
- branche de la mathématique (nommée pour son inventeur Georges Boole) qui traite les équations de vérité, donnant toujours un résultat binaire : vrai ou faux.
- Transistor
- composant électronique qui agit comme un interrupteur actionné par un courant de contrôle. Les transistors sont maintenant fabriqués à l’échelle de quelques centaines d’atomes de large, plaçant plusieurs milliards de transistors sur une même puce électronique.
- Bit
- chiffre binaire (“binary digit” en anglais), soit 1, soit 0. Les chiffres utilisés pour représenter l’état d’un circuit avec les correspondances 1 = haute tension et 0 = basse tension.
- Tableau de vérité
- tableau indiquant l’état vrai/faux (ou 1/0) pour chaque combinaison possible des valeurs d’entrée. Les opérations booléennes, comme et, ou et non, sont définies dans des tableaux de vérité.
- Porte logique
- composant électronique qui combine des transistors de manière à effectuer des opérations booléennes sur les bits d’entrée.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- décrire le lien entre le système binaire implémenté dans les appareils électroniques et la logique booléenne;
- reconnaître les symboles des portes logiques de base et déterminer leur sortie.
Critères de succès
- Je peux décrire pourquoi les ordinateurs utilisent la logique booléenne comme principe fondamental.
- Je peux analyser des circuits de portes logiques et déterminer leur sortie en fonction d’une entrée spécifique.
Notes
Ressources additionnelles
La liste de lecture Youtube Crash Course : Computer Science par PBS Digital Studios présente d’excellents survols visuels de ces concepts. Notamment, en lien avec cette leçon, les épisodes 2 à 6 sont pertinentes:
Exercices
📚 Tester la compréhension
Quiz de vérification sur les portes logiques
🛠️ Pratique
📚 Architecture von Neumann
Survol et attentes
La logique, les données, les instructions et la gestion des entrées et sorties d’un ordinateur sont organisées de manière assez uniforme dans la plupart des cas, peu importe le type d’ordinateur : portables, tablettes, cellulaires, serveurs, systèmes embarqués, etc. Cette organisation est appelée l’architecture von Neumann.
Définitions
La structure von Neumann est composée de quatres systèmes principaux. Les systèmes sont la mémoire (qui stockent les données), l’unité de contrôle (qui gère la prochaine commande à exécuter), l’unité arithmétique et logique (qui fait les opérations sur les données) et les entrées/sorties (E/S) (qui reçoivent et envoient des informations de/vers l’unité de contrôle). Les quatre systèmes sont liés par un bus de communication.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Reconnaître et de nommer les quatres systèmes de l’architecture von Neumann
- Classer différents composants matériels dans le système approprié
Critères de succès
- Je peux nommer et décrire la fonction de la mémoire, de l’unité de contrôle, de l’unité arithmétique et logique et des entrées/sorties
- Je peux classer des composants matériels communs dans l’un des quatre catégories de l’architecture von Neumann
Notes
Présentation rapide des composants d’un ordinateur
| Composants d’un ordinateur | Parties de la carte mère |
|---|---|
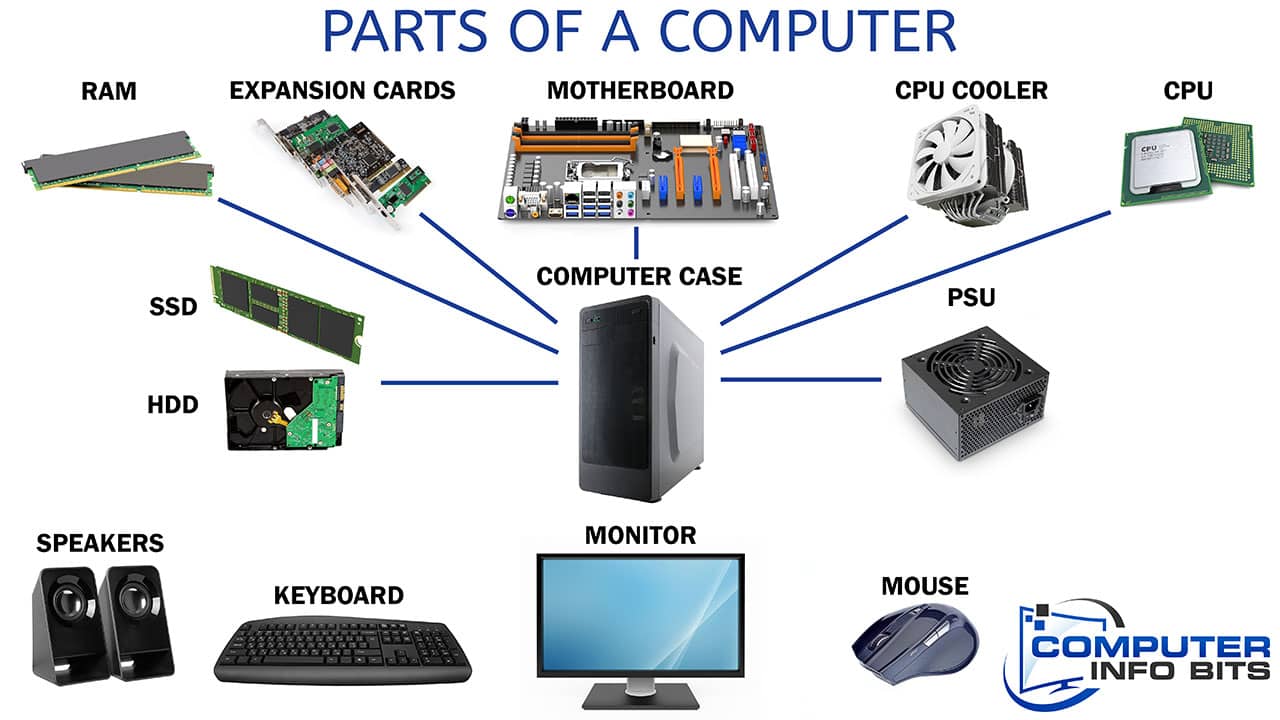 | 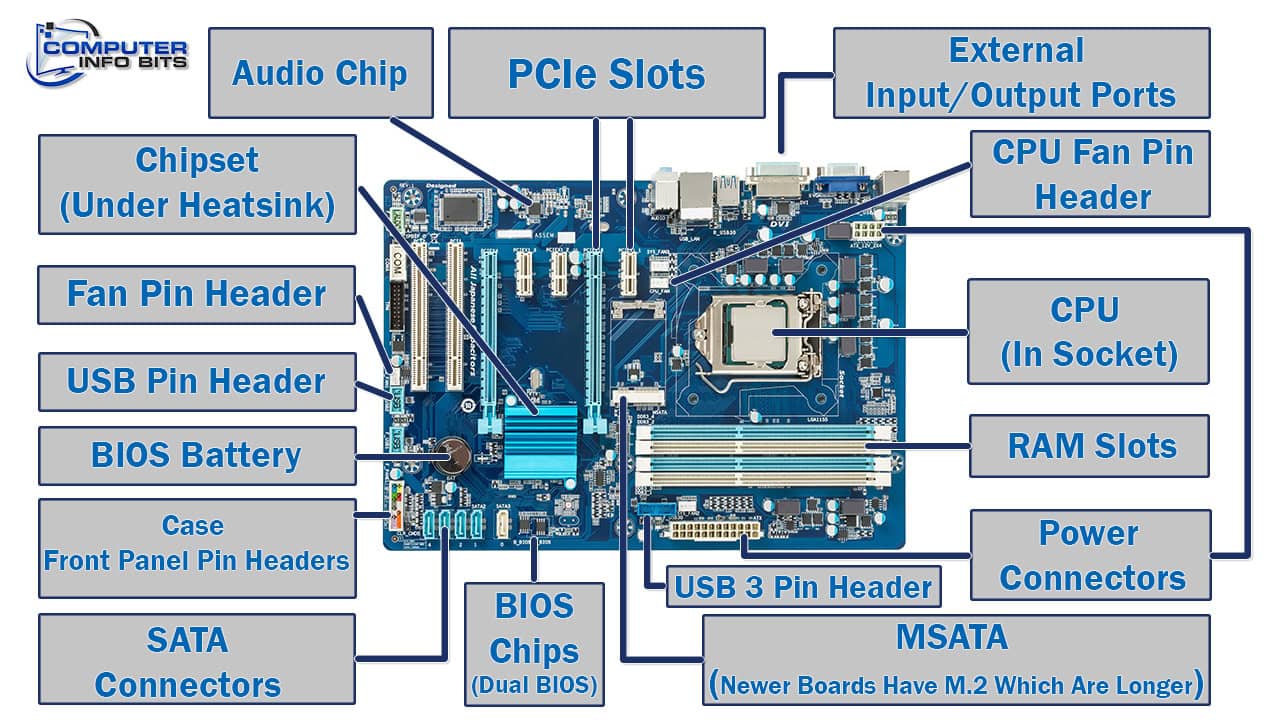 |
Les images ci-dessus présentent un portrait assez complet de la structure d’un ordinateur.
Du point de vue d’un programmeur, par contre, les composants principaux à considérer sont les suivants car ils influencent la performance des logiciels (mémoire, stockage, processeur) et la communication avec l’utilisateur (périphériques d’entrée et de sortie).
- Mémoire : stocke les données et les instructions en cours d’utilisation
- Processeur : exécute les instructions et coordonne les opérations des autres composants; il y a généralement un processeur tout usage (CPU) qui délègue certaines tâches à un processeur graphique (GPU) dans les ordinateurs modernes.
Les processeurs sont composés de plusieurs unités, notamment :
- Unité de contrôle : coordonne les opérations des autres unités
- Unité arithmétique et logique : effectue les opérations mathématiques et logiques
- Mémoire cache : stocke temporairement les données et les instructions les plus utilisées pour réduire le temps d’attente de lecture de la mémoire principale
- Stockage : stocke les données et les instructions de façon permanente (p. ex. disque dur, carte SD, clé USB). Le stockage est considéré comme un périphérique d’entrée/sortie même si le disque dur est souvent intégré plus étroitement à la carte mère.
Une bonne illustration du fait que le stockage est un périphérique est le Raspberry Pi qui utilise une carte SD amovible comme disque principal.
- Périphériques d’entrée et de sortie : matériel qui envoie ou reçoit de l’information du processeur (comme le stockage, mais aussi les écrans, souris, et les routeurs de réseau). Ils permettent à l’utilisateur (ou d’autres ordinateurs) de communiquer avec l’ordinateur.
Explication de la coordination de ce composants dans l’architecture von Neumann
Exemple de traçage du flux (de la séquence) d’opérations matérielles dans un ordinateur
Plusieurs détails liés aux logiciels du système d’exploitation ne sont pas inclus dans cette séquence. Ils font partie de la prochaine leçon.
Qu’est-ce qui se passe quand on lance une application?
- L’utilisateur envoie l’instruction de lancer l’application avec un périphérique d’entrée comme un clavier ou une souris.
- Le contrôleur des entrées/sorties reçoit ce signal d’interruption et passe l’instruction au contrôleur de l’UTC.
- Plusieurs logiciels du système chargés en mémoire s’occupe de l’instruction - toute une danse de communication entre la mémoire, et l’UTC (mémoire cache, unité arithmétique et logique, contrôleur) - pour finalement arriver à l’instruction de charger l’application en mémoire.
- L’unité de contrôle demande au contrôleur des entrées/sorties de lire le disque dur et charger l’application dans la mémoire.
- Le contrôleur des entrées/sorties envoie une instruction à l’UTC quand la lecture est terminée.
- L’UTC commence alors à exécuter l’application - une autre danse entre la mémoire et l’UTC incluant la gestion des signaux vers les périphériques de sortie (écran, haut-parleurs, imprimante, Internet, etc.) et reçus des périphériques d’entrée (souris, clavier, microphone, Internet, etc.).
Exercices
📚 Tester la compréhension
aucun quiz de vérification des concepts ici encore
🛠️ Pratique
📚 Périphériques externes
Survol et attentes
En bref
Vous n’avez pas besoin de comprendre la structure interne d’un ordinateur pour commencer à programmer, mais vous avez besoin d’un ordinateur fonctionnel qui répond à vos besoins! On regarde quelques options réelles pour différents composants matériels et on apprend comment comparer leurs performances.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Reconnaître des termes et des unités communs pour décrire la performance ou la capacité des composants, comme GHz, MHz, Go et ips.
- Déterminer quel composant entre deux options possède la meilleure performance.
Critères de succès
- Je peux trouver les données de performance du matériel installé sur son ordinateur et sur des périphériques
- Je peux identifier le composant avec la meilleure performance en se servant des données disponibles.
Notes
Exemple
Vous trouvez deux annonces pour des ordinateurs portables à 600$, les suivantes :
Option A
Portable de 15,6 po Vivobook 15 d’ASUS - Bleu calme (Core i5-1235U d’Intel/SSD 512 Go/RAM 8 Go/Windows 11) voir l’offre)
Option B
Portable de 15,6 po de HP - Argenté naturel (Core i5-1135G7 d’Intel/SSD 512 Go/RAM 16 Go/Windows 11 Home) voir l’offre)
Quels sont les avantages de A comparé à B?
Solution
C’est dur de le savoir en regardant simplement le nom et les spécifications succinctes du produit qui sont presque identiques.
À première vue, l’option B semble plus intéréssante car elle a le double de la mémoire vive (16Go de RAM contre 8Go). Mais en lisant les spécifications détaillées et en faisant un peu de recherche on trouve que le processeur de l’option A a 10 coeurs ou lieu de 4 et un mémoire cache de 12Mo au lieu de 8Mo. Donc A a le meilleur processeur.
Finalement, il y a aussi des différences sur le nombre et le type de ports, la vie de la batterie et la qualité de l’écran. Bref, ce sont des produits semblables et le meilleur dépend de ce qui est le plus important pour vous.
Exercices
📚 Tester la compréhension
Quiz de vérification sur les unités de performance des périphériques
Accueil > Logiciels du système >
📚 Représentation interne des données : les encodages binaires
Survol et attentes
Imaginez que tous les caractères dans votre livre, magazine ou blogue préféré sont remplacés par des codes numériques, un code unique par caractère. Ce serait assez dur à lire!
Imaginez maintenant que peut-être ces codes ne représentent PAS des lettres mais peut-être les données de couleur pour un pixel ou peut-être une valeur numérique ou peut-être une adresse en mémoire pour un fichier. C’est encore pire!
Comment faire sens de tout ça?
La mémoire et le stockage d’un ordinateur contiennent juste ces types de codes, mais les codes sont - en plus - en binaire! Plusieurs standards sont mis en place pour structurer ces informations et pour offrir des formats d’information communs. Il y a des opérations intégrées dans l’UAL ou disponibles comme algorithmes dans le système d’exploitation pour décoder ces informations correctement.
Définitions
- Encodage
- La conversion d’une valeur d’un type de données à un autre, p. ex. d’un caractère à un nombre ou d’un nombre à une couleur. Plusieurs encodages sont utilisés pour interpréter du binaire en données significatives.
- ASCII
- Acronyme pour American Standard Code for Information Interchange, un standard pour représenter des caractères en binaire avec un code de 7 bits (128 caractères). Au-delà du standard ASCII, il y a des encodages plus larges pour représenter des caractères de plusieurs langues, divers symboles et des émoticônes. Le standard Unicode est le plus universel, mais les standards ANSI et ISO sont aussi utilisés, notamment sur les systèmes Windows.
- Nombre à virgule flottante
- Un standard pour représenter des nombres décimaux en binaire, avec un bit pour le signe, un nombre de bits pour l’exposant et un nombre de bits pour la mantisse. Le standard IEEE 754 est le plus commun. Ce standard est implémenté directement dans l’unité d’arithmétique du processeur.
- Hexadécimal
- Une base numérique qui utilise 16 symboles (0-9 et a-f) pour représenter des valeurs en binaire de manière plus compacte et plus lisible pour les humains. Chaque symbole hexadécimal représente 4 bits. L’hexadécimal est souvent utilisé pour représenter des adresses mémoire, des couleurs RVB et des valeurs de configuration.
- RVB
- Acronyme pour Rouge, Vert, Bleu, un standard pour représenter des couleurs en binaire avec 3 octets (24 bits) pour chaque pixel. Chaque octet représente un niveau de couleur (0 à 255) pour chaque couleur primaire. Les couleurs RVB sont utilisées dans les écrans, les images et les vidéos.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- reconnaître des valeurs en différentes bases numériques : binaire, décimal et hexadécimal
- décrire la structure interne de types de données comme les nombres entiers et les caractères
Critères de succès
- Je peux identifier si une valeur est binaire ou hexadécimal connaissant la valeur décimal représentée.
- Je peux décrire la représentation interne de différents types de données comme les nombres entiers, les caractères et les couleurs RVB
Les bases numériques
D’abord il faut réaliser que les valeurs dans un ordinateur sont toutes représentées en base 2 (avec seulement les nombres 0 et 1).
Toutes les bases numériques - décimal, binaire, hexadécimal, etc. - sont des systèmes de numération positionnels, où chaque position représente une puissance de la base.
- La première position (à la droite) est la puissance 0, donnant toujours les unités.
- La valeur à chaque position est un facteur à multiplier par la puissance de la base pour obtenir la valeur de la position. Par exemple, en décimal, la valeur 23 est décomposée comme suit :
23
= 2 * 10^1 + 3 * 10^0
= 2 * 10 + 3 * 1
= 20 + 3
Comme les valeurs à base 10 (où chaque position représente la prochaine puissance de 10), les positions des bits dans les valeurs à base 2 représentent la prochaine puissance de 2.
Une autre base utile, rendant le binaire plus facile à digérer pour les humains, est l’hexadécimal, la base 16, où chaque position représente une puissance de 16. L’hexadécimal utilise un seul nombre pour chaque 4 bits. Par exemple, la valeur 1101 en binaire est équivalente à d (13) en hexadécimal.
Décimal (base 10)
Chiffres
0123456789
Préfixe conventionnel
Aucun. L’absence de préfixe indique que la valeur est en base 10.
Structure
| Positions | … | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|
| Puissance | … | 103 | 102 | 101 | 100 |
| Valeur | … | 1000 | 100 | 10 | 1 |
| Nom | … | Milliers | Centaines | Dizaines | Unités |
Exemple
4628 =
- 4 milles + 6 cents + 2 dizaines + 8 unités
- 4000 + 600 + 20 + 8
Binaire (base 2)
Chiffres
01
Préfixe conventionnel
0b ou 0B devant la valeur pour indiquer que la valeur est en base 2.
On peut aussi placer le souscript 2 après le chiffre sans préfixe, p. ex. 11012 est équivalent à 0b1101
Structure
| Positions | … | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|
| Puissance | … | 23 | 22 | 21 | 20 |
| Valeur | … | 8 | 4 | 2 | 1 |
| Nom | … | Huits | Quatres | Deux | Unités |
Exemple
0b1101 =
- 1 huit + 1 quatre + 0 deux + 1 unité
- 8 + 4 + 0 + 1
- 1310
Hexadécimal (base 16)
Chiffres
0123456789abcdef
Préfixe conventionnel
0xou0X#devant les couleurs RVB en hexadécimal- souscript 16, p. ex. 10016 est équivalent à 0x100 (et représente la valeur décimale 25610).
Structure
| Positions | … | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|
| Puissance | … | 163 | 162 | 161 | 160 |
| Valeur | … | 4096 | 256 | 16 | 1 |
| Nom | … | Seize cube | Seize carré | Seizes | Unités |
Exemple
0x1f =
- 1 seize + 15 unités
- 16 + 15
- 3110
Encodage binaire pour différents types de données
| Type de donnée | Exemple | Représentation interne (Encodage) |
|---|---|---|
| Nombre entier | 32, -12, 1000000 | Base 2 : 8 à 32 bits (1 à 4 octets) pour la valeur numérique en binaire |
| Caractères | 97 (‘a’), 50 (‘2’) | ASCII : 7 bits faisant référence au caractère dans le tableau ASCII qui sont identifiés de 0 à 127; Unicode : plus universellement, un code de 8 à 32 bits (1 à 4 octets) pour représenter les caractères dans le tableau Unicode. Différents encodages sont possibles : UTF-8 (1 à 4 octets), UTF-16 (2 à 4 octets), UTF-32 (4 octets) |
| Nombres décimaux | 3.14, 2.5, -45900.1134 | IEEE 754 : 32 ou 64 bits pour spécifier un nombre à virgule flottante, avec 1 bit représentant le signe (-/+), 8 ou 11 bits représentant l’exposant et 23 ou 52 bits représentant la mantisse |
| Couleurs 24 bits RVB) | rgb(255, 0, 0), #00ff00 | RVB : 1 octet (8 bits) représentant 256 niveaux de rouge, 1 octet pour l’intensité du vert et 1 octet pour l’intensité du bleu. Avec 8 bits, la gamme d’intensités est de 0 à 255 en décimal ou de #00 à #ff en hexadécimal; RVBA : en ajoutant un quatrième octet (nommé “alpha”), on peut spécifier la transparence d’une couleur. |
Exercices
📚 Tester la compréhension
Quiz de vérification sur la représentation interne des données
🛠️ Pratique
Encodages de base
Enrichissement - algorithmes pour convertir les bases
Accueil > Logiciels du système >
📚 Langages de bas niveau
Survol et attentes
On sait qu’on peut créer des circuits et composants pour performer diverses opérations logiques et arithmétiques. On sait aussi que les bits peuvent être interprétés de différentes façons pour représenter différents types d’informations (p. ex. nombres, texte, couleurs).
Maintenant on va combiner les deux, fusionner le matériel et les données, pour savoir comment on peut programmer nos propres algorithmes.
Définitions
Ceci est une vue de très bas niveau et nous ne ferons pas de programmation comme ça… on va utiliser des abstractions puissantes - les langages de haut niveau - pour rendre la tâche plus facile. Mais si vous comprenez comment ça marche “sur le métal nu” vous comprendrez mieux pourquoi certains éléments du langage de haut niveau existent.
- Langage de bas niveau
- Langage de programmation où les instructions (codes d’opératipn) correspondent directement aux opérations des circuits de l’ordinateur et les données sont des références directes à des registres du CPU ou des adresses en mémoire vive. Le langage machine (binaire) et le langage assembleur (codes machines en mots/nombres lisibles par les humains) sont des exemples de langages de bas niveau. Le langage machine peut-être envoyé directement au processeur. Le langage assembleur a simplement besoin d’être traduit en langage machine (substituant les codes humains pour les codes binaires associés) avant d’être exécuté.
- Langage de haut niveau
- Langage de programmation qui doit d’abord être interprété ou compilé en langage machine par un logiciel spécialisé. Cette étape intermédiaire d’analyse du programme permet aux langages de haut niveau d’être plus naturels pour les humains, d’inclure des instructions puissantes (fonctions, boucles, lecture/écriture de fichiers, etc.) et des abstractions pour les données (objets, variables). Python, Java, C++, et JavaScript sont des exemples de langages de haut niveau.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Nommer deux langages de bas niveau, le langage machine et le langage assembleur, et décrire leurs différences.
- Décrire si les instructions de bas niveau font référence à la valeur ou à l’adresse des données
Critères de succès
- Je peux donner une définition et deux exemples de langage de bas niveau.
- Je peux décrire la structure des instructions de bas niveau et le rôle du compteur du programme.
Comment les langages de programmation fonctionnent à bas niveau
Démonstration (vidéo - du début à 3:30)
Une excellente explication des bases du fonctionnement se trouve dans la vidéo de Computerphile, notamment les trois premières minutes et demi.
Explication des instructions de bas niveau
Quelques points clés :
- chaque donnée, incluant les instructions, se trouve à une adresse spécifique en mémoire vive
- les instructions font toujours référence à l’adresse en mémoire et non à la valeur qu’elle contient; certaines instructions demandent de lire la valeur à cet endroit et d’autres demandent d’écrire une nouvelle valeur à cet endroit
- il y a des adresses spécialisées sur le processeur pour stocker des valeurs à court terme durant les opérations - les registres de l’unité d’arithmétique et de logique
- il y a un registre spécial qui stocke toujours l’adresse de la prochaine instruction à exécuter - le compteur du programme; certaines opérations modifient directement cette valeur, sinon l’adresse avance par un nombre de bits spécifique correspondant à la largeur des cellules en mémoire.
Ce qui n’est pas mentionné dans la vidéo mais qui est également important :
- S’il y a des données que vous voulez utilisez en référence durant le programme ou conserver par la suite, il doit avoir des adresses en mémoire pour ces valeurs au delà des registres de l’UAL (qui seront réutilisés pour d’autres opérations)
- On montre les instructions utilisant des mots qu’on peut lire et des nombres décimaux : Cela correspond au langage assembleur ou à un autre langage de bas niveau. Ces instructions seraient traduits en binaire (langage machine) pour l’exécution :
- un code unique par mot-clé, chaque code correspondant à un circuit qui existe dans le processeur
- toutes les valeurs sont en binaire
- un format standard pour l’instruction, p. ex. 1 octet pour le code d’instruction et, selon l’instruction, des nombres spécifiques d’octets pour la 1e opérande et pour la 2e opérande.
Langages de bas niveau
Quand tout est en binaire (les codes d’opération et les opérandes), le code s’appelle le langage machine. Les 1 et 0 opèrent directement sur les circuits de l’ordinateur (les portes logiques et composants vus précédement).
Quand on remplace le code d’opération avec un mot-clé et on écrit les adresses avec des caractères (p.ex.: r1, 0x0004), le code s’appelle un langage assembleur. Il est équivalent au langage machine, mais lisible par les humains.
Ce sont les deux langages de bas niveau. Les opérations sont contraintes à représenter directement les circuits de la machine. Les langages de haut niveau n’ont pas cette contrainte.
Langages de haut niveau
Avec les langagages de haut niveau, on peut se permettre d’utiliser des mots-clés et des structures plus naturelles pour les humains sachant que ces instructions seront analysés par un logiciel (l’interpréteur ou le compilateur) qui les traduira en langage machine (ou produira des messages d’erreur si les instructions ne sont pas valides).
On trouve dans la plupart des langages de haut niveau des mot-clés comme : if-else (si, sinon), for (pour les éléments ou valeurs suivants), while (tant que la condition suivante est vraie), etc. Chacun de ces mots-clés seraient remplacé par toute une série de codes d’opération en langage machine.
Comparaison des différents types de programmes
Voici une comparaison de programmes écrites en trois version présumant les informations suivantes :
- le code
0b0001=0x1= 1 est l’opération d’enregistrement d’une valeur en mémoire dans le registrer1 - le code
0b0010=0x2= 2 est l’opération d’ajout d’une valeur à celle déjà dans le registrer1 - le code
0b0011=0x3= 3 est l’opération de stockage d’une valeur à une adresse en mémoire vive - la valeur
0b00011011=0x1b= 27 est une adresse en mémoire vive qui contient la valeur 2 (0b10=0x2) - la valeur
0b00011100=0x1c= 28 est une adresse en mémoire vive qui contient la valeur 3 (0b11=0x3)
Le but du programme est d’ajouter les valeurs 2 et 3 et le stocker en mémoire à l’adresse 0x1d.
Langage machine
Codes d’opération en binaire Adresses mémoire en binaire
0b0001 0b00011011
0b0010 0b00011100
0b0011 0b00011101
Langage assembleur
Mêmes codes d’opération en mots Mêmes adresses en hexadécimal
Load r1, 0x1b
Add r1, 0x1c
Store r1, 0x1d
Langage de haut niveau (Python)
nest une abstraction pour un endroit en mémoire L’addition de valeurs est représentée naturellement L’interpréteur de Python traduit le tout en langage machine.
n = 2 + 3
Accueil > Logiciels du système >
📚 Machines virtuelles
Survol et attentes
À part les périphériques comme le clavier, la souris, le microphone, etc. vous n’avez jamais manipuler directement les composants d’un ordinateur pour traiter les valeurs binaires.
Définitions
Entre vous et la machine réelle se trouve une ou plusieurs couches qui s’appellent la machine virtuelle. Elle est plus intuitive à utiliser. C’est sa tâche de traduire toutes vos interactions avec l’ordinateur en binaire pour la machine réelle.
Les parties de la machine virtuelle que vous manipulez s’appellent l’interface utilisateur. Il y a d’autres parties de la machine virtuelle qui sont utilisées par les logiciels afin qu’elles aient accès aux ressources de l’ordinateur. Cette partie s’appelle l’interface de programmation.
Un autre nom pour la machine virtuelle principale sur un appareil est le système d’exploitation, comme Windows, macOS, iOS, Android, Ubuntu.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- décrire le système d’exploitation et les grandes catégories de logiciels du système;
- différencier la machine réelle de la machine virtuelle et l’interface utilisateur de l’interface de programmation;
- différencier les types d’interfaces utilisateurs : ligne de commande, graphique et réalité virtuelle.
Critères de succès
- Je peux identifier les types de logiciels du système et décrire ce que chacun fait.
- Je peux décrire les différences entre une machine virtuelle et réelle et entre une interface utilisateur et une interface de programmation.
- Je peux identifier le type d’interface utilisateur à partir d’une description ou d’une image.
Notes
On ne manipule pas des bits ni des octets en travaillant avec un ordinateur. On utilise un clavier, une souris, etc. On travaille alors avec une machine virtuelle qui traduit nos gestes en informations et instructions binaires pour la machine réelle. C’est encore un niveau d’abstraction plus élevée, comme les portes logiques, les composants et les systèmes de l’architecture von Neumann : les détails du fonctionnement de la machine réelle sont cachés.
Pour rendre un ordinateur pratique pour un utilisateur du grand public qui n’est pas nécessairement expert en informatique, les systèmes d’exploitation ont été développés, p. ex. MS-DOS, Apple DOS (des “Disk Operating Systems”), Unix, Windows, macOS, iOS, Android, Linux/GNU, ChromeOS. Un système d’exploitation est une suite de logiciels qui présente une interface entre l’utilisateur et le matériel physique. Cette interface est une machine virtuelle ou environnement virtuel.
La machine virtuelle fait les quatre choses suivantes :
- masquer les détails complexes du matériel physique de l’ordinateur en le gérant pour les utilisateurs et les applications;
- présenter l’information d’une façon naturelle (caractères, nombres décimaux, éléments graphiques, etc.) qui ne demande aucune connaissance de la structure interne des données;
- permettre un accès facile aux ressources disponibles sur l’ordinateur;
- prévenir les dommages accidentels ou intentionnels du matériel, des programmes ou des données.
Interface utilisateur, interface de programmation et interface interne
Les utilisateurs ne manipulent pas directement le matériel de l’ordinateur. Ils utilisent une interface utilisateur pour demander des ressources ou des services. Par exemple, un utilisateur peut cliquer sur une icône pour ouvrir un fichier. L’interface utilisateur, au moyen d’une suite de logiciels du système, traduit ce geste en une série d’instructions binaires pour la machine réelle.
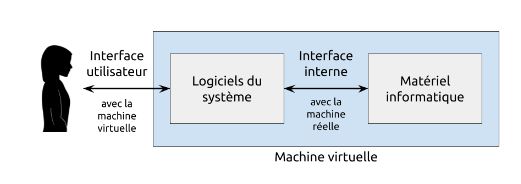
De même, toutes les applications installées sur un système d’exploitation n’accède pas directement au matériel. Elles utilisent une interface de programmation pour demander des ressources ou des services au système d’exploitation. Par exemple, une application de traitement de texte n’écrit pas directement sur le disque dur. Elle demande au système d’exploitation de le faire pour elle.
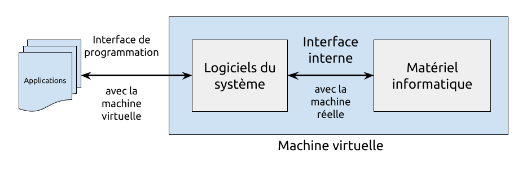
Dans les deux cas, les interfaces font le pont entre des demandes externes (d’une personne ou d’un programme) en les passant à une interface interne - aussi appelé le noyau - qui est en mesure d’exploiter les ressources matérielles directement via des données et des instructions en format binaire correspondant directement à l’architecture matérielle installée.
Services du système
Le noyau (interface interne) : pour gérer le matériel directement
- Gestion de la mémoire : allouer et libérer de l’espace mémoire pour les applications;
- Gestion des processus ou Programmateur : démarrer, arrêter, suspendre et reprendre des applications; bref, gérer la prochaine instruction à exécuter;
- Pilotes de périphériques : traduire les signaux des périphériques d’entrée en instructions utilisables par le système d’exploitation et les autres applications et vice versa pour les périphériques de sortie;
- Gestion des fichiers : organiser les fichiers sur le disque dur, les lire, les écrire, les effacer, etc.
- Gestion des autorisations : déterminer qui a le droit de faire quoi sur l’ordinateur; p. ex. si un utilisateur ou une application a le droit de faire certaines opérations normalement réservées au système d’exploitation.
Le shell (interface utilisateur)
- Interface en ligne de commande : une fenêtre de texte où l’utilisateur tape des commandes pour demander des services;
- Interface graphique : une fenêtre avec des icônes, des menus et des boutons pour demander des services;
- Utilitaires : des applications qui offrent des services spécifiques, comme un explorateur de fichiers, un éditeur de texte, un gestionnaire des tâches/performances, un navigateur web, un gestionnaire d’installation/désinstallation d’applications, etc. Ces utilitaires peuvent exister à la fois en versions ligne de commande et graphique, comme les gestionnaires de fichiers.
- Services de langages : des applications qui offrent des services de programmation, comme un assembleur, un compilateur, un débogueur, un éditeur de code, etc.
L’interface de programmation d’applications (API)
Les fonctions, structures de données et protocoles qui permettent aux applications de tous les niveaux (interne/noyau, utilisateur/shell) de demander des services aux autres applications. Par exemple, une application de traitement de texte peut demander à une application de navigateur web de lui afficher une page web via l’API de l’application de navigateur web.
Exercices
📚 Tester la compréhension
aucun quiz de vérification des concepts ici encore
🛠️ Pratique
- Énumérez les systèmes d’exploitation que vous avez déjà utilisés ou que vous utilisez encore.
- Identifiez 3 utilitaires que vous avez déjà utilisés sur un cellulaire ou un ordinateur. Pour chacun indiquez :
- son nom et sa fonction;
- s’il est un interface graphique ou en ligne de commande;
- s’il est directement lié à un service du noyau (oui/non - si oui, lequel).
- Énumérer 2 à 5 applications que vous avez installées sur votre cellulaire ou ordinateur.
- Activez vos connaissances existantes de l’architecture matérielle de l’ordinateur et les joindre aux nouvelles connaissances sur les services du système pour décrire une séquence d’opérations raisonnable1 pour :
- ouvrir un fichier;
- lancer le navigateur web;
Vous devrez faire le geste pour voir au moins les étapes visibles de l’interface utilisateur (les différentes vues/fenêtres et interactions que vous faites). Ensuite, tentez d’associer vos gestes aux réponses du système via la machine virtuelle (services du système) et la machine réelle (architecture Von Neumann).
-
Raisonnable signifie que la séquence devrait être cohérente avec les différents services du système et les différents composants matériels mais pas nécessairement complète ou exacte (ce qui nécessite plus de connaissances et plus de détails sur le contexte… ce sera un sujet pour un cours spécialisé sur les systèmes d’exploitation à l’université). ↩
Accueil > Logiciels du système >
🛠️ Organisation des fichiers dans un système d’exploitation
Survol et attentes
Comment est-ce que votre système d’exploitation sait où trouver vos fichiers? ses propres logiciels du système? vos applications?
Définitions
Le système garde un fichier spécial dans les premières positions de tout disque qui est un tableau avec les adresses mémoire du début de tous les dossiers et fichiers sur le disque.
Les fichiers sont organisés dans une hiérarchie qui s’appelle une arborescence. Chaque dossier sur un disque représente une branche de l’arborescence et chaque fichier dans un dossier représente les feuilles sur cette branche.
Pour identifier un fichier ou un dossier précis, on écrit son chemin. Le chemin est une séquence de noms de dossiers séparés par des barres obliques (/ ou \) qui indique la route à suivre à partir de la racine du disque pour trouver le fichier ou le dossier.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Lire et interpréter les chemins sur un système Windows ou Linux
- Savoir comment naviguer à travers le système de fichiers avec un interface graphique (l’explorateur de fichiers) ou en ligne de commande (avec les commandes
cd,ls,tree)
Critères de succès
- Je suis capable d’écrire le chemin pour un dossier ou un fichier spécifique sur mon ordinateur.
- Je suis capable de trouver des dossiers et des fichiers spécifiques sur mon ordinateur.
Structure hiérarchique (arborescence) des fichiers et dossiers
Comment sont organisés les fichiers dans votre dossier utilisateur? Il y a plusieurs façons de le voir avec les logiciels du système. On va en utiliser deux ici.
 |  |
| Tâche | Explorateur de fichiers (clics) | Terminal (commandes) |
|---|---|---|
| Ce qui se trouve à la base de votre dossier utilisateur | Explorateur de fichiers > Ce PC > Disque local (C:) > Utilisateurs > votre compte image ↗ | cd ~ ensuite ls image ↗ |
| L’arborescence de votre dossier utilisateur | Ouvrir tous les sous dossiers manuellement en cliquant les flèches image ↗ | tree image ↗ |
| Obtenir le chemin | Cliquer sur la barre de navigation image ↗ | pwd image ↗ |
Chemin d’accès (path) d’un fichier ou d’un dossier
L’adresse d’un fichier ou d’un dossier en format lisible par un humain s’appelle un chemin. Le chemin représente la séquence d’embranchements (dossiers) à suivre à partir de la racine du disque pour se rendre au dossier ou au fichier voulu.
Exercices
📚 Tester la compréhension
aucun quiz de vérification des concepts ici encore
🛠️ Pratique
Accueil >
Partie B - Programmation
Légende : 🛠️ 📚
-
🛠️Compétences en génie informatique
Savoir-faire en lien avec le génie informatique. Les compétences sont évaluées au moyen de projets concrets.
Développez ces compétences avec les exercices pratiques dans chaque leçon.
-
📚 Concepts
Nouveau concept. Le plus de concepts que vous maîtrisez, le plus que vous alimenter vos compétences pour produire des choses intéressantes. Les concepts sont évalués au moyen de quiz sur papier et d’entrevues.
Validez votre compréhension avec les mini quiz dans chaque leçon.
Sommaire
Les unités précédentes vous donnent un grand portrait de comment un ordinateur fonctionne, tant du point de vue formel (algorithmes) que du point de vue matériel (circuits) et logiciel (la machine virtuelle).
Cette unité vous donne une première expérience pratique de la programmation, soit du développement de vos propres logiciels. Vous apprendrez un langage de programmation, Java, et vous apprendrez comment utiliser un environnement de développement intégré (EDI) pour unifier plusieurs des logiciels du système nécessaires pour écrire, compiler et exécuter un programme à partir du code source. Vous apprendrez aussi comment partager votre code avec d’autres personnes en utilisant Git et GitHub.
À la fin de cette unité, vous aurez une base suffisante en programmation pour :
- implémenter n’importe quel algorithme;
- apprendre n’importe quel autre langage de programmation selon vos besoins et vos intérêts.
Lien avec l’éthique, la société ou les carrières
💭 Quelques pistes de réflexion :
- Dans le milieu du travail, les gens ne sont pas tous traités de façon équitable. Cela va pour la relation employeur-employé, pour les relations entre les employés et même pour la relation entre les utilisateurs et les fournisseurs de logiciels. Énumérez des exemples de situations où les gens ne sont pas traités de façon équitable pour chacune de ces relations.
- Il existe des codes d’éthique pour les ingénieurs logiciels qui tentent de décrire un standard acceptable de comportement pour un professionnel dans le domaine. Parcourez le code d’éthique de l’IEEE-CS ou celui de l’ACM et notez quelques points que vous trouvez particulièrement frappants.
- Sachant comment ça peut être difficile de produire même un simple projet logiciel complet, fonctionnel et à la hauteur de vos standards, discutez de l’importance de la propriété intellectuelle, des droits d’auteur et des licences dans le domaine du logiciel. Notamment, si l’auteur attend une compensation pour son travail (en lui attribuant une licence commerciale, p. ex.), est-ce que c’est acceptable de copier - pirater - son travail sans sa permission et sans le rémunérer?
- Dans quelles situations est-ce qu’une licence commerciale peut-être considérée abusive?
Les bases de Java
- 📚 Structure d’un projet Java
- 🛠️ Communication interne (identifiants et commentaires)
- 📚 Afficher des messages à la console - partie 1
- 📚 Données (
int,double,boolean,char,String) - 📚 Afficher des messages à la console - partie 2
- 📚 Utiliser des méthodes
- 📚 Importer des classes
- 📚 Entrées via la console
- 📚 Opérations numériques
- 📚 Diagrammes de flux
Domaines d’application
Sommaire
Cette section, lorsqu’on a le temps de la faire, vous donne la chance d’explorer les possibitilités du génie informatique. L’unité précédente vous a donné une base en programmation, mais aucun travail ou projet qui ressemble aux logiciels que vous utilisez quotidiennement comme simple utilisateur.
Cette unité vous montre différents domaines d’application pour les solutions logicielles, vous permet d’explorer les piles technologies utilisées pour créer ces solutions, et vous donne la chance de créer un projet concret pour démontrer vos compétences.
À la fin de cette unité, vous serez capable de :
- Inclure des bibliothèques et des frameworks dans vos projets Java afin d’incorporer des fonctionnalités avancées dans votre propre code;
- Connaître quelles piles technologiques sont généralement utilisées pour différents types d’applications afin de mieux cibler un langage de programmation et des outils de développement pour un projet donné.
Lien avec l'éthique la société ou les carrières
💭 Quelques pistes de réflexion :
- Explorez deux ou trois cheminements professionnels considérablement différents si votre objectif était de devenir :
- développeur web;
- développeur de jeux vidéo;
- développeur de solutions de sécurité informatique
- À l’école, votre rendement est plus étroitement lié à votre mérite qu’il le sera pour le reste de votre vie. Malheuruesement, le monde n’est pas juste ni méritocratique. Heureusement, il y a beaucoup de variété dans la qualité des situations. Quels sont des signes clairs que vous êtes dans une situation injuste? Que feriez-vous dans une telle situation? Quels sont des indicateurs fiables qu’une sitation est plus équitable?
- Deux ressources importantes pour les communautés sous-représentées dans divers domaines technologoqiues sont le mentorat et les groupes de soutien. Trouvez un groupe de soutien ou un service de mentorat pour professionnels en informatique qui vise spécifiquement votre communauté. Notez comment y avoir accès et la nature des services offerts.
Ces leçons restent à développer… les sujets sont actuellement traités via des démonstrations et des projets concrets en classe.
- 🛠️ Diverses piles technologiques - des langages et des outils adaptés à la tâche
- 🛠️ Gérer des projets Java de groupe ou de plus grande taille avec Maven
- 🛠️ Utiliser le framework JavaFX pour créer des interfaces graphiques dans Java
Accueil > Programmer avec Java > Préprarer l’environnement de développement >
🛠️ Installation de logiciels
Survol et attentes
Définitions
- Éditeur de texte
- Un logiciel qui modifie des fichiers au format texte, soit qui ne contiennent que des caractères imprimables (comme les lettres, chiffres, ponctuation, espaces, etc.). Tout système d’exploitation vient avec un éditeur de texte simple, comme le Bloc-notes de Windows ou TextEdit de macOS. Les logiciels comme Word ou Docs ne sont pas des éditeurs de texte mais des traitements de texte, car ils ajoutent des informations de mise en forme dans le fichier qui ne peuvent pas être interprétées comme des caractères imprimables.
- Langage de programmation
- Une suite de logiciels qui traduisent des fichiers de texte (code source) en instructions pour l’ordinateur. Certains langages interprètent le code directement en binaire (p. ex. python) et d’autres compilent d’abord le code source (texte) en code objet (binaire) (p. ex. C++). Java est un langage compilé, mais le code objet n’est pas en binaire spécifique à un système d’exploitation, mais en bytecode. Ces fichiers .class sont ensuite interprétés par la machine virtuelle Java selon la machine spécifique.
- Console ou terminal
- Une interface en ligne de commande qui permet (entre autres) de lancer l’interpréteur ou le compilateur de votre langage de programmation sur votre code source, code objet ou bytecode. C’est ici qu’on lance les programmes pour les tester.
- Éditeur de code
- Pour la programmation, les éditeurs de code sont des éditeurs de texte qui viennent aussi avec des fonctionnalités supplémentaires pour faciliter la programmation, comme la coloration syntaxique, l’auto-complétion, la vérification de syntaxe, etc. Visual Studio Code, Sublime Text et Vim sont des exemples d’éditeurs de code. Comme les éditeurs de texte, les éditeurs de code sont flexibles et peuvent servir pour la programmation dans une variété de langages.
- Environnement de développement intégré (EDI)
- Un logiciel qui combine un éditeur de texte, un compilateur ou interpréteur (selon le langage), un débogueur et d’autres outils pour faciliter la programmation. Chaque EDI est conçu pour un langage de programmation spécifique contrairement aux éditeurs de code qui sont plus polyvalents. IntelliJ IDEA, Eclipse et NetBeans sont des exemples d’EDI pour Java.
- Gestion du code source
- Un système qui permet de suivre les modifications apportées à un projet de programmation. Git est le logiciel le plus commun pour ceci et vous permet de sychroniser votre code source avec un serveur distant (comme GitHub) pour le partager avec d’autres développeurs (incluant vous-même sur un autre ordinateur et votre enseignant).
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Installer vos logiciels de développement avec un installateur fourni par le développeur ou manuellement en extrayant les fichiers et en mettant à jour la variable
Pathde votre compte. - Configurer les applications via leur interfaces graphiques ou en ligne de commande
Critères de succès
- Les programmes installés se lancent correctement.
Une des compétences le plus fondamentales pour un développeur est la capacité à installer ses outils de travail et à configurer son système pour le rendre fonctionnel.
Instructions d’installation
Liste des logiciels à installer localement (sur votre compte) et à configurer pour ce cours :
Langage de programmation
Trousse de développement Java (JDK) avec JavaFX -> par extraction d’un .zip et modification de la variable Path
Éditeur de code
Visual Studio Code -> installation avec une interface graphique + ajout d’extensions spécifiques à Java
Gestion des versions
Logiciel : Git pour Windows -> installation avec une interface graphique + configuration initiale au console
Serveur distant : GitHub -> création d’un compte + intégration avec VS Code
Accueil > Programmer avec Java > Préprarer l’environnement de développement >
🛠️ Environnements de développement intégrés (IDE) - VS Code et Codespaces
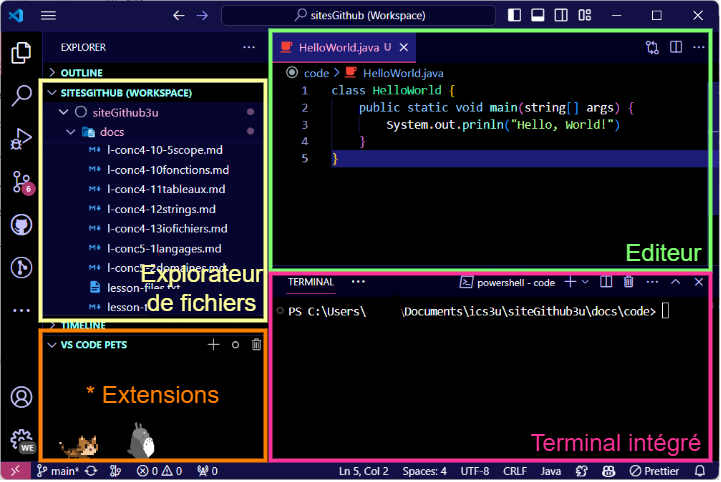
Survol et attentes
Définitions
- Palette de commandes
- façon le plus efficace de lancer des commandes dans VS Code. Tapez
Ctrl + Shift + Ppour ouvrir la palette de commandes et ensuite tapez le début d’une commande pour la trouver. Les commandes utilisées récemment sont affichées en premier. - Projet
- Dans VS Code, un projet est un dossier. VS Code tout seul peut ouvrir des fichiers de nombreux dossiers à la fois, mais les outils de gestion de projet, p. ex. ceux de Java, seront confus : ils présument que le dossier ouvert est la racine du projet et peuvent se comporter de façon inattendue si vous ne respectez pas cette convention.
- Explorateur de fichiers
- permet de naviguer dans les fichiers et dossiers de votre projet. Cliquez sur un fichier pour l’ouvrir dans l’éditeur. L’explorateur s’affiche à gauche de l’éditeur et montre uniquement le dossier ouvert. Vous pouvez sauter directement à l’explorateur en tapant
Ctrl + Shift + E. - Terminal intégré
- permet d’exécuter des commandes dans le terminal sans quitter VS Code. Tapez
Ctrl + `pour ouvrir le terminal intégré ou naviguer dans le menu “Terminal” puis choisir “New Terminal”. - Paramètres
- permet de configurer VS Code. Tapez
Ctrl + ,pour ouvrir les paramètres ou naviguer dans le menu “File” puis choisir “Preferences” puis “Settings”. - Extensions
- ajoutent des fonctionnalités à VS Code, le transformant d’éditeur de code en environnement de développement intégré. Tapez
Ctrl + Shift + Xpour ouvrir la vue des extensions ou cliquez sur l’icône dans la barre latérale gauche.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Savoir ouvrir un projet dans VS Code
- Savoir comment configurer les paramètres de VS Code
- Savoir comment ajouter les extensions à VS Code pour le développement Java
Critères de succès
- Je peux utiliser VS Code comme un environnement de développement intégré pour Java et passer d’un projet à un autre avec aisance.
Ouvrir un projet
Pour ouvrir un projet, il faut ouvrir un dossier dans VS Code. Voici comment faire :
- Ouvrez VS Code.
- Cliquez sur “File” dans la barre de menu.
- Cliquez sur “Open Folder…”.
- Trouvez le dossier que vous voulez ouvrir et cliquez sur “Select Folder”.
Vous pouvez aussi ouvrir un dossier à partir de votre Explorateur de fichiers Windows :
- Naviguer au dossier voulu
- Faites un clic droit sur le dossier, choisissez “Plus d’options” et choisissez “Ouvrir avec Code”.
Le nom du dossier que vous avez ouvert devient une section de la barre latérale gauche de VS Code. Cliquez sur le nom du dossier pour voir le contenu de ce dossier ou tapez
Ctrl + Shift + E(le “E” est pour “Explorateur de fichiers”) pour le même effet.
Testez votre compréhension
Dans VS Code, ouvrez le dossier qui contient le fichier Demo.java que vous avez créé dans une leçon précédente. Si vous n’avez pas encore créé de fichier Java, simplement ouvrir le dossier ~/Documents dans VS Code.
Créer un fichier Java dans votre projet
Pour ajouter un fichier Java à votre projet, il suffit de créer un fichier avec l’extension .java dans le dossier de votre projet. Voici comment faire :
-
Cliquez sur le bouton “New File” dans l’Explorateur de fichiers de VS Code.
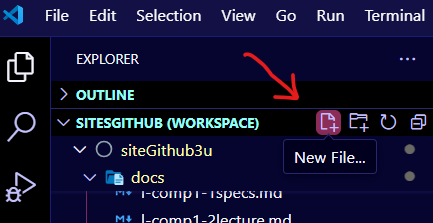
-
Tapez le nom du fichier suivi de l’extension
.java, p. ex.HelloWorld.java. -
Le fichier sera créé et ouvert dans l’éditeur de code.
C’est TRÈS IMPORTANT d’ajouter l’extension
.javaau nom du fichier, sinon les outils de Java ne fonctionneront pas correctement (même si VS Code peut reconnaître le code Java sans l’extension).
Testez votre compréhension
Créez le fichier HelloWorld.java dans votre projet.
Ajouter le code Java brisé suivant1. Ne le réparez pas pour l’instant. On verra très bientôt comment les outils Java nous aident à trouver les erreurs.
void main() {
system.out.prinln("Hello, World!")
}
Enregistrement automatique - un paramètre utile
Avec les outils de travail dans le nuage, comme la suite Google ou la suite Microsoft Office, nous sommes habitués à ce que nos documents soient enregistrés automatiquements pour nous, mais ce n’est pas le comportement par défaut dans VS Code.
Pour activer l’enregistrement automatique, la façon la plus simple est :
- d’ouvrir la palette de commandes avec
Ctrl + Shift + P - taper
Auto Savepour trouver la commandeFiles: Toggle Auto Save. S’il n’était pas activé, il le sera maintenant. S’il était activé, il ne le sera plus.
Vous pouvez savoir si l’enregistrement automatique n’est pas activé si le
Xà côté du nom du fichier dans l’éditeur n’est plus unXmais un cercle●. Cela signale que les derniers changements dans l’éditeur n’ont pas été enregistrés sur le disque.
Attention : si vous tentez de lancer un programme à partir d’un fichier qui n’a pas été enregistré, c’est la dernière version enregistrée qui se lance, pas ce que vous voyez dans l’éditeur. Croyez-moi, vous pouvez perdre beaucoup de temps à chercher une erreur qui n’existe plus simplement parce qu’il y a cet écart entre ce que vous voyez et ce qui est enregistré.
Testez votre compréhension
- Regardez le nom du fichier
HelloWorld.javadans l’éditeur. Est-ce que leXest unXou un cercle? Le●indique un fichier qui n’est pas enregistré. - Basculer l’activation de l’enregistrement automatique et vérifier si le cercle devient un
X. - Ajoutez une ligne vide à la fin du code. Est-ce que le
Xdevient un cercle ou reste unX? - Répétez les deux dernières étapes une autre fois et notez la différence.
- Si l’enregistrement automatique n’est pas activé en ce moment, l’activer avant de continuer.
Extensions utiles pour programmer avec Java
C’est important d’avoir un peu d’équilibre dans la vie. Je vous suggère d’installer l’extension
VS Code Petsen plus de l’extension de productivité ci-dessous. Choisissez un animal (ou un autre entité) de compagnie pour vous tenir compagnie pendant que vous travaillez.
On peut rendre VS Code plus puissant pour la programmation dans le langage de notre choix en ajoutant des extensions adaptées. Pour Java, ces extensions sont emballés dans le Java Extension Pack.
Ces outils vous aident à :
- Trouver des erreurs dans votre code avant de l’exécuter
- Exécuter votre code avec un bouton au lieu d’une commande
- Trouver des suggestions pour améliorer votre code
- Trouver des informations sur les classes et les méthodes que vous utilisez (si vous leur ajouter des commentaires de documentation)
- Passer à travers le code pas-à-pas avec un débogueur pour voir comment il fonctionne ou pour trouver des erreurs de logique
Installez et configurer le Java Extension Pack
- Ouvrez la vue des extensions en tapant
Ctrl + Shift + X(“X” pour “eXtensions”) ou en cliquant sur l’icône dans la barre latérale gauche. - Tapez
Java Extension Packdans la barre de recherche. - Trouvez la version de Microsoft et cliquez sur le bouton “Install”.
Si vous avez une erreur indiquant qu’il faut installer un JDK, votre installation de Java est incomplète. Voir la leçon sur l’installation de Java pour résoudre ce problème (notamment la section sur les variables d’environnement).
- Attendre que l’installation soit complète… vous le saurez quand l’indicateur Java dans la barre d’état en bas de l’écran arrête son animation.
- Ouvrez les paramètres de VS Code avec
Ctrl + ,. - Changez le paramètre “inlay hints” :
- Tapez
java inlaydans la barre de recherche. - Trouvez le paramètre “Java: Inlay Hints”.
- Changez la valeur de “literal” -> “none”. Cela élimine des notations dans le code qui n’existent pas dans le texte que vous avez écrit.
- Tapez
- Changez le paramètre du “mode de lancement” :
- Tapez
java launchdans la barre de recherche. - Trouvez le paramètre “Java: Server Launch Mode”.
- Changez la valeur de “hybrid” -> “standard”. Cela assure que les outils d’analyse du code démarrent immédiatement quand vous ouvrez vos projets.
- Tapez
- Redémarrez VS Code.
Testez votre compréhension
Ouvrez le fichier HelloWorld.java dans VS Code. Vous devriez voir des lignes rouges apparaître dans le code. Ces lignes indiquent des erreurs dans le code. Cliquez sur une ligne rouge pour voir le message d’erreur.
Cliquez sur le bouton “Run” en haut à droite de l’éditeur pour exécuter le code. Vous devriez voir les mêmes messages d’erreur dans la console que ceux que vous avez vus en passant votre curseur sur les lignes rouges.
Si vous parvenez à décoder ces messages d’erreur (ils ne sont pas toujours très clairs), vous pouvez essayer de corriger le code et le lancer de nouveau. Comment interpréter ces messages est un art qui se développe avec l’expérience et la pratique.
Terminal intégré
En lançant votre programme Java avec le bouton “Run” dans l’éditeur, vous avez déjà utilisé le terminal intégré : c’est là que la commande derrière le bouton “Run” est exécutée et c’est aussi là que la sortie de votre programme est affichée.
Vous pouvez utiliser le terminal intégré dans VS Code exactement comme vous utilisez le programme Terminal. Les deux utilisent le même shell (bash, PowerShell, etc.) et les mêmes commandes.
Pour ouvrir le terminal intégré, tapez Ctrl + ` (le ` est la touche à gauche de Entrée sur un clavier francophone et à la gauche du 1 sur un clavier anglophone) ou naviguer dans le menu “Terminal” puis choisir “New Terminal”.
Testez votre compréhension
- Ouvrez le terminal intégré.
- Tapez
lspour voir la liste des fichiers dans le dossier de votre projet. Assurez-vous queHelloWorld.javaest dans la liste. - Tapez
java HelloWorld.javapour lancer le programme dans le code sourceHelloWorld.java. - Tapez
clearpour effacer la console. - Utilisez la flèche du haut pour charger la commande
java HelloWorld.java(les flèches du haut et du bas permettent de naviguer dans l’historique des commandes). TapezEnterpour lancer le programme une autre fois. - Tapez
exitpour fermer le terminal.
-
Le code Java publié sur ce site applique le JEP 463 (mise à jour aux fonctionnalités de Java - notamment déclaration de classe explicite et méthode
maind’instance au lieu de l’idiomepsvm) qui est en deuxième révision depuis Java22 mais pleinement intégré dans l’extension Java de VS Code pour ce même Java22. Si vous utilisez un autre IDE, vous pourriez rencontrer des erreurs de compilation. Le but ultime est d’incorporer le JEP 477 dès que Java23 soit incorporé aux outils Java. Cette 3e révision inclut aussi l’importation automatique de méthodes statiques de la nouvelle classejava.io.IOet l’utiliation deprintetreadlnsimilaire à Python (print/input) ou C++ (cout/cin). ↩
Accueil > Programmer avec Java > Préprarer l’environnement de développement >
📚 Utiliser Java
Survol et attentes
Définitions
- REPL
- une interface de ligne de commande pour un langage de programmation qui attend une entrée tapée par l’utilisateur (Read), évalue l’expression tapée (Evaluate), affiche le résultat (Print) et recommence (Loop). Le REPL Java s’appelle
jshell. Les REPL sont des moyens efficaces d’exécuter des petits morceaux de code pour voir comment ils fonctionnent. - Compilateur
- un programme qui traduit le code source (texte) en code objet (binaire) et l’enregistre dans un fichier. Pour exécuter le programme, il faut utiliser le code objet. Le compilateur Java s’appelle
javac- dit “Java C” - mais il ne produit pas de code objet. Il produit plutôt du bytecode Java et des fichiers.class. L’avantage du bytecode est qu’il peut être exécuté sur n’importe quelle machine où la machine virtuelle Java (JVM) est installée tandis que le code objet est spécifique à une machine. - Interpréteur
- un programme qui traduit le code source en code objet et l’exécute directement. L’interpréteur Java - le Java Virtual Machine (JVM) - s’appelle
javamais il ne prend généralement pas le code source en entrée. Il prend plutôt le bytecode Java produit par son compilateur. Par contre, depuis Java 11 le JVM peut interpréter directement un programme qui se tient à un seul fichier de code source.java.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Distinguer un compilateur et un interpréteur.
- Associer des extensions de fichiers (
.java,.class,.exe) au type de code qu’ils contiennent : code source, code objet ou bytecode. - Décrire la fonction des commandes Java suivantes :
javac,java, etjshell.
Critères de succès
- Je peux utiliser les outils Java pour tester les exemples de code dans les notes de cours et pour lancer les programmes dans mon code source.
Travailler avec des extraits de code
Pour tester des extraits de code avec Java 9 ou plus récent, on peut utiliser un REPL Java.
Le REPL Java s’appelle jshell. Pour lancer jshell, tapez simplement jshell au terminal. Vous devriez voir un prompt jshell> qui attend votre entrée.
PS ~\Documents> jshell
| Welcome to JShell -- Version 20.0.1
| For an introduction type: /help intro
jshell>
Cela signifie que le terminal attend des instructions Java qu’il peut évaluer. Essayez d’entrer une expression simple comme 2 + 2 et appuyez sur Enter. Vous devriez voir le résultat de l’expression affiché à l’écran.
jshell> 2 + 2
$1 ==> 4
Le $1 est un numéro de référence pour le résultat de l’expression. Si vous entrez une autre expression, elle sera référencée par $2, et ainsi de suite. Vous pouvez utiler ces références plus tard pour accéder à la valeur.
jshell> $1
$1 ==> 4
Pour quitter jshell, tapez la commande /exit.
jshell> /exit
| Goodbye
Travailler avec le code source
Le code source Java se trouve dans des fichiers avec l’extension .java. Il y a trois façons de lancer un programme Java à partir de son code source :
- l’interpréter directement via une commande au terminal
- compiler le code source en bytecode Java et interpréter le bytecode avec des commandes au terminal
- avec les outils d’un EDI qui compilent et interprètent le code source pour vous
L’interpréter directement avec java
Pour interpréter votre code source directement, vous avez besoin de la version Java 11 ou plus récent. Au terminal, tapez la commande suivante :
java chemin/au/fichier/MonProgramme.java
où vous remplacez chemin/au/fichier/MonProgramme.java par le chemin complet vers votre fichier .java. Notez que vous devez inclure l’extension .java dans le nom du fichier pour l’interpréter directement.
Note : avec Windows, le séparateur de dossiers est le
\. La commandejavapeut reconnaître les/mais si vous tentez d’utiliser la fonction de complétion automatique de Powershell, il remplacera les/par des\.
Quelques points importants :
-
Si vous êtes dans le dossier du fichier au terminal, le chemin complet est simplement le nom du fichier. Si vous avez ouvert le dossier du projet dans votre EDI, ce sera le comportement par défaut : l’EDI ouvre le terminal dans le dossier du projet.
java MonProgramme.java -
Si vous êtes dans un dossier différent au terminal, vous devez spécifier le chemin complet ou vous diriger dans le bon dossier au terminal avec la commande
cdsuivi par le chemin du dossier.java .\Documents\MonProgramme.javacd Documents java MonProgramme.java
Compiler et interpréter avec javac et java
Ici la même approche générale s’applique sauf qu’on lance le programme en deux étapes. L’avantage est que si le code source ne change plus, lancer le programme est plus rapide : le temps pour la compilation est déjà fait et on peut en profiter en utilisant le fichier .class déjà compilé.
Aussi, dans des programmes plus complexes qu’un seul fichier de code source, cette démarche est nécessaire pour lier les fichiers ensemble.
Vous êtes dans le bon dossier
Première fois :
javac MonProgramme.java
java MonProgramme
Après la première fois : on lance le bytecode déjà compilé
java MonProgramme
Notez que la commande java prend le nom de la classe, pas le nom du fichier .java.
Vous êtes dans un dossier différent
Première fois :
javac .\Documents\MonProgramme.java
java -cp .\Documents MonProgramme
Comme avec l’interprétation direct, il faut spécifier le chemin complet pour la première commande, dans ce cas javac. Pour la deuxième commande - java, on utilise l’option -cp (pour classpath) pour spécifier le dossier où se trouve le fichier .class. Finalement, on donne le nom de la classe.
Après la première fois : on lance le bytecode déjà compilé
java -cp .\Documents MonProgramme
Avec le bouton Run de l’EDI
Le bouton Run fait les mêmes choses que la section suivante mais le fait automatiquement en tentant de suivre votre structure de dossier.
Ces outils s’attendent à ce que vos programmes se trouvent directement à la racine du dossier du projet. Si vous avez des sous-dossiers pour organiser vos fichiers, le bouton Run peut ne pas fonctionner correctement et d’autres outils de l’EDI peuvent vous donner des avertissements ou des messages d’erreur. C’est le problème avec un outil qui tente d’automatiser : il ne peut pas toujours deviner ce que vous voulez faire.
Exercices
📚 Tester la compréhension
Quiz de vérification sur les outils Java
🛠️ Pratique
Ces instructions présument que vous avez fait le travail précédent (dans la leçon sur l’EDI) : le dossier “Documents” est ouvert dans VS Code et il contient le programme HelloWorld.java.
- Lancez le programme
HelloWorld.javaavec la commandejava HelloWorld.javadans le terminal intégré de votre EDI. - Compilez le programme
HelloWorld.javaavec la commandejavac HelloWorld.javadans le terminal intégré de votre EDI. Rien ne devrait se produire sauf la création du fichierHelloWorld.class. - Lancez le programme
HelloWorld.classavec la commandejava HelloWorlddans le terminal intégré de votre EDI. Notez que c’est seulement le nom de la classe qui est donné à la commandejavapour utiliser le bytecode déjà compilé. - Lancez le programme avec le bouton
Runde votre EDI. Regardez attentivement la commande complète qui s’affiche à la console. Cette commande commence par la version longue dejava, inclut quelques options que nous n’utilisons pas quand on lance la commande manuellement et se termine avec quoi : le nom d’un fichier ou le nom de la classe? Selon votre observation, est-ce que cette commande interprète directement le code source ou le compile d’abord avant de lancer le bytecode? - Modifier et enregistrez le code dans HelloWorld.java, p.ex. pour afficher un message différent.
- Interprétez directement le programme modifié avec la commande
java HelloWorld.java. - Lancez la version compilée manuellement avec la commande
java HelloWorld. Est-ce que la version compilée a changé? Si oui, qu’avez-vous fait pour que ça change? Si non, pourquoi pas? - Lancez le programme avec le bouton
Run. Est-ce que le programme a changé? Les outils de l’EDI s’occupent de compiler automatiquement les fichiers de vos projets.
- Interprétez directement le programme modifié avec la commande
Accueil > Programmer avec Java > Préprarer l’environnement de développement >
🛠️ Partager le code avec Git et GitHub
Survol et attentes
Définitions
- Dépôts
- (“repos” en anglais) Les projets gérés avec Git sont appelés dépôts. Un dépôt est un dossier qui contient tous les fichiers de votre projet, y compris les fichiers de configuration de Git. Les dépôts sont stockés sur votre ordinateur et peuvent être partagés avec d’autres personnes sur GitHub. Les dépôts sur votre ordinateur s’appellent des dépôts locaux, tandis que ceux sur GitHub sont des dépôts distants.
- Clôner
- Pour copier un dépôt distant sur votre ordinateur, vous devez le clôner. Cela crée une copie locale du dépôt sur votre ordinateur. Vous pouvez ensuite travailler sur le projet localement et synchroniser les changements avec le dépôt distant.
- Modifier
- selon Git un fichier modifié a été soit édité, ajouté ou supprimé depuis la dernière version validée. Ces modifications existent sur votre disque dur, mais ne sont pas encore enregistrées dans Git. Git vous permet de supprimer les modifications depuis la dernière validation, au besoin, ce qui affectent les fichiers sur votre disque dur.
- Indexer
- (“stage” en anglais) indexer les modifications est comme un photographe qui choisit son sujet. Vous sélectionnez les fichiers modifiés que vous voulez inclure dans votre prochain instantané. Vous ne pouvez pas prendre une photo sans un sujet, et vous ne pouvez pas faire une validation sans avoir indexé au moins une modification.
- Valider
- (“commit” en anglais) toujours dans le contexte de la photographie, valider est comme prendre une photo. Vous créez un instantané de votre projet à un moment donné. Vous pouvez revenir à cet instantané à tout moment pour voir ce à quoi ressemblait votre projet à ce moment-là.
Il faut toujours identifier un commit avec un court message; il n’est pas possible de compléter l’opération sans ce message.
- Synchroniser
- (“sync” en anglais) synchroniser un dépôt veut dire combiner et mettre à jour les validations du dépôt local et du dépôt distant. Toutes les validations qui ne sont pas communes seront partagées. Ainsi, une synchronisation poussera les validations locales vers le dépôt distant et tirera les validations distantes dans votre dépôt local.
Cette opération peut générer des conflits de fusion des validations. Si cela se produit, demandez de l’aide à votre enseignant.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Clôner un projet partagé via GitHub
- Modifier, indexer et valider des fichiers dans un dépôt local
- Synchroniser les changements avec le dépôt distant
Critères de succès
- Je suis capable d’utiliser Git (dans VS Code) et GitHub (dans un navigateur web) pour archiver mon code et le partager avec mes enseignants.
Clôner un projet partagé via GitHub
Votre enseignant vous prépare des gabarits de projets, parfois juste des dossiers vides, pour organiser vos programmes dans le cours. Pour les utiliser, vous devez les clôner dans votre ordinateur. Voici comment faire :
-
Acceptez d’abord la tâche dans GitHub Classroom, ce qui vous créera une copie personnelle du projet sur GitHub.
-
Ouvrez VS Code.
-
Ouvrez la palette de commandes avec
Ctrl + Shift + P. -
Tapez “clone” pour trouver la commande
Git: Cloneet cliquez dessus. Si vous l’avez déjà utilisée, elle apparaîtra dans la liste des commandes récentes sans avoir à la chercher.Si c’est la première connexion, VS Code vous demandera de vous connecter à GitHub. Suivez ATTENTIVEMENT les instructions pour vous connecter. Si on vous propose une option “toujours…”, cochez-la pour éviter des problèmes de connexion à l’avenir.
À SURVEILLER : Parfois la fenêtre pour une des étapes d’authentification apparaît en arrière-plan, bloquant la connexion. Regarder la barre des tâches pour voir s’il y a des nouvelles fenêtres ouvertes.
-
Cliquez ensuite sur
Clone from GitHubet attendre que la liste des dépôts apparaisse. Puisque vous n’en avez pas beaucoup, votre dépôt sera facile à trouver dans la liste. -
Cliquez sur le dépôt que vous voulez clôner et choisissez un dossier où le clôner dans la fenêtre qui s’ouvre. Je suggère fortement d’utiliser votre dossier “Documents” pour tous les projets.
-
VS Code créera un dossier avec le nom du dépôt à cet endroit et copiera le projet dedans.
-
VS Code vous proposera d’ouvrir le dossier clôné avec les options suivantes :
- Open : ferme le projet ouvert actuellement et ouvre le projet clôné
- Open in New Window : ouvre le projet clôné dans une nouvelle fenêtre de VS Code (gardant le projet actuellement ouvert dans la fenêtre originale)
- Add to Workspace : ajoute le projet clôné à la liste des dossiers actuellement ouverts dans VS Code (utile si vous avez plusieurs projets ouverts en même temps)
En général, les options Open ou Open in New Window sont les plus simples à gérer.
Clônez une seule fois, synchronisez par la suite
Si vous avez déjà clôné un projet, vous n’avez pas besoin de le clôner à nouveau pour continuez à travailler dedans. Vous pouvez simplement ouvrir le dossier du projet dans VS Code. Il y a même une section “Open Recent” dans le menu “File” pour vous aider à retrouver les projets que vous avez ouverts récemment.
Testez votre compréhension
Clônez le projet “pratique” dans votre dossier “Documents” et ouvrez-le dans VS Code. Le lien pour le gabarit de ce projet est partagé avec vous dans Classroom.
Modifier, indexer et valider des fichiers dans un dépôt local
Cette section vous montre comment apporter des changements dans votre dépôt local, les conserver avec Git et les partager avec le dépôt distant, sur GitHub.
Modifier
Cette étape est la partie normale de la production de code : vous créez, modifiez et supprimez des fichiers en faisant vos exercices ou en développant vos programmes. Assurez-vous de travailler dans un dossier de projet et non sur des fichiers isolés. Seulement les fichiers dans un dépôt local - comme ceux que vous clônés de GitHub - peuvent être indexés et validés. Les dépôts locaux sont tous des dossiers.
Vous savez que vous faites des modifications dans un dépôt local si vous voyez un “M” à côté des noms des fichiers modifiés ou un “U” (pour “Untracked”) pour les fichiers que vous venez de créer. Si vous faites des modifications et vous ne voyez pas ces indicateurs, il y a deux possibilités : vous n’avez pas enregistré les fichiers sur le disque (activez l’enregistrement automatique) ou les fichiers ne sont pas dans un dépôt (utiliser l’Explorateur de fichiers Windows pour les déplacer dans votre dépôt).
De plus, vous devrez utiliser les outils de travail (les extensions Java, le terminal intégré, etc.) pour vous aider à écrire du code Java valide et fonctionnel. La leçon précédente sur VS Code vous explique davantage ces outils. En d’autres mots, vous devrez tester votre code avant de passer aux prochaines étapes.
Indexer et valider
En plus des indicateurs de modification mentionnés plus haut, vous pouvez voir le nombre de fichiers modifiés sur l’icône de l’outil Git dans la barre latérale de VS Code. Vous pouvez seulement indexer et valider des fichiers modifiés, alors vous pouvez seulement passer à cette étape quand il y a un nombre affiché.
Ces étapes peuvent se faire au terminal - et vous avez beaucoup plus de possibilités au terminal - mais VS Code vous offre une interface graphique pour les faire, ce qui est plus convivial. Voici comment l’utiliser :
- Cliquez sur l’icône “Source Control” dans la barre latérale de VS Code ou en tapant
Ctrl + Shift + G(“G” pour “Git”). - Les fichiers modifiés apparaîtront dans la liste “Changes”. Ce sont tout les fichiers qu’il est possible d’indexer.
Vous pouvez cliquer sur un fichier pour voir les modifications qu’il contient. Les lignes en vert sont les ajouts, les lignes en rouge sont les suppressions.
- Pour indexer un fichier, cliquez sur le
+à côté du nom du fichier. Cela ajoutera le fichier à la liste des fichiers indexés. Vous pouvez indexer tous les fichiers en cliquant sur le+en haut de la liste (à côté de “Changes”). Les fichiers indexés sont les sujets de l’instantané que vous allez prendre en validant les modifications. - Écrire un message qui décrit les modifications indexées. Il est impossible de compléter la validation sans ce message. Il y a une zone de texte en haut du panneau de contrôle pour taper ce message. Voici quelques exemples de messages courts et descriptif :
- Salut.java et capture pour l’exercice 1
- ajout de commentaires pour l’exercice 2
- progession sur Projet.java
- correction d’erreurs dans Main.java
- Valider les modifications indexées en cliquant sur le bouton “Commit” (le bouton avec la coche). Cela prend un instantané des modifications indexées. Ces modifications sont maintenant enregistrées dans Git, mais seulement sur votre ordinateur dans le dépôt local.
Si vous oubliez d’écrire un message, VS Code bloque l’opération et ouvre un éditeur de message à la droite. Écrivez votre message sur une ligne qui ne commence pas par
#(qui est un commentaire) et fermez l’éditeur (en l’enregistrant au besoin). La validation se complétera automatiquement.
Testez votre compréhension
Modifiez le fichier “README.md” dans le projet “pratique” : ajouter une ligne vide ou supprimez quelque chose. Indexez et validez le fichier avec un message descriptif.
Visitez votre dépôt sur GitHub pour voir que les modification n’ont pas été partagées. Rafraîchissez la page pour être certain. Ces étapes ont seulement créé une version qui peut être partagée avec un dépôt distant. Il faut faire la synchronisation pour partager cette version.
Synchroniser les changements avec le dépôt distant
Valider et synchroniser du code est comme la photographie. Un cliché se trouve d’abord juste sur l’appareil du photographe. Pour les partager avec le monde, le photographe doit les téléverser sur une plateforme de partage, comme un réseau social.
Partager des instantanés de code est pareil. La validation enregistre l’instantané sur votre ordinateur mais vous devez encore le téléverser sur le dépôt distant (GitHub), soit le synchroniser avec ce dépôt. Voici comment faire :
- Après la validation, le bouton “Commit” devient “Sync Changes” avec le nombre de validations à pousser. S’il y a aussi des validations sur le dépôt distant qui ne sont pas sur votre ordinateur, le bouton affichera le nombre de validations à tirer.
- Pour synchroniser, il suffit de cliquer sur le bouton.
Bonnes habitudes pour éviter les conflits de fusion
Pour éviter d’avoir à fusionner les validations à tirer avec les validations à pousser, vous devrez suivre ces règles d’or : toujours synchroniser (tirer) avant de commencer à travailler sur un projet et toujours synchroniser avant de fermer l’ordinateur. De cette façon, tout ce qui est à tirer arrive seul au début d’une session de travail, laissant seulement les modifications à pousser à la fin de la session de travail. De plus, vous commencerez toujours votre session avec la version la plus à jour du projet.
Après votre première synchronisation, VS Code vous demandera si vous voulez tirer périodiquement les modifications distantes. Je vous recommande de le faire (ce qui inclut une synchronisation chaque fois que vous ouvrez le projet), mais vous pouvez choisir de le faire manuellement si vous préférez afin de développer la discipline de synchroniser avant de travailler.
Vous devrez tout de même développer la discipline de synchroniser à la fin des périodes de travail.
Quand vous travaillerez en équipes (l’année prochaine), il y a des stratégies plus avancées pour éviter les conflits de fusion - notamment l’utilisation de branches, mais pour vos projets personnels, cette règle est suffisante et efficace.
Testez votre compréhension
Synchronisez les modifications du projet “pratique” avec le dépôt distant. Visitez votre dépôt sur GitHub pour voir que les modifications ont été partagées. Rafraîchissez la page au besoin.
Accueil > Programmer avec Java > Les bases de Java >
📚 Structure d’un projet Java
Survol et attentes
Définitions
Dans les programmes que nous écrirons, nous verrons des éléments de structure entre ‘expression’ et ‘méthode main’ de façon régulière. Occasionnellement nous aurons à utiliser une classe, un package ou un framework plus explicitement. Mais cette liste couvre les éléments d’un programme Java de la plus petite à la plus grande structure possible.
- Expression
- combinaison minimale de texte dans le code source qui respecte la syntaxe du langage de programmation. D’autre texte produit des erreurs de syntaxe. Les expressions Java peuvent être des valeurs littérales, des variables, des opérations sur les données, des appels de méthodes, etc.
- Instruction
- une expression ou combinaison d’expressions qui effectue une action. Les instructions Java se terminent toujours avec un point-virgule
;. Ils peuvent être des déclarations de variables, des appels de méthodes ou des opérations sur les données. - Bloc de code
- un ensemble d’instructions associé à la même partie d’un programme. En Java, les blocs de code sont délimités par des accolades
{}. Pour améliorer la lisibilité du code, les blocs de code sont souvent indentés. Les outils de votre éditeur de code peuvent vous aider à indenter automatiquement le code. - Méthode
- un bloc de code nommé qui a un type (comme les variables) et qui peut recevoir des informations affectant son résultat. En programmation plus généralement, cette structure s’appelle une fonction. Dans Java, toutes les fonctions sont définies dans des classes et le nom officielle pour ce type de fonction est une méthode.
- Méthode
main - le point d’entrée du programme1 et le seul bloc de code qui doit absolument être déclaré dans tout programme Java. C’est la méthode que Java exécute automatiquement lorsqu’on lance le programme. Au plus simple2, elle a la signature
void main()- ce que nous utiliserons dans nos programmes, mais cette signature peut se développer jusqu’à la signature complète, traditionnellepublic static void main(String[] args). Ce cours n’expliquera pas tous les détails de la signature traditionnelle.
- Classe
-
Une structure qui définit un objet, soit une unité de programmation qui a des données (nommées attributs) et des comportements (nommés méthodes). Java étant un langage orienté-objet, la classe est la plus petite structure autonome possible. Tous les programmes Java se tiennent à l’intérieur d’une ou de plusieurs classes.
Dans nos programmes, la classe unique sera déclarée automatiquement2 la plupart du temps, nous laissant définir les méthodes et attributs directement dans le fichier
.java. Parfois, et de manière plus commune dans les grands projets Java, les classes sont des blocs de code déclarées avec le mot-cléclass.
- Package
- un conteneur pour des classes Java, associé à un dossier sur le disque dur. Les packages sont utilisés pour organiser les classes en groupes logiques et gérer l’accès aux classes. Dans tous nos programmes, le package de notre code est implicite et ne sera pas déclaré dans le code source.
- Module
- un conteneur pour des packages Java (depuis Java9) associé à un fichier
module-info.java. Les modules sont utilisés pour organiser les packages en groupes logiques pour créer des applications modulaires, n’utilisant que les packages nécessaires pour l’application. Dans tous nos programmes, le module de notre code est implicite et ne sera pas déclaré dans le code source. - Framework
- une collection de modules Java qui fournissent des fonctionnalités prêtes à l’emploi pour des applications spécifiques. Les frameworks Java les plus connus sont JUnit (pour les tests unitaires), Spring (pour le développement web), Hibernate (pour la persistance des données) et JavaFX (pour les interfaces graphiques).
- Application
- une collection de modules Java - ceux du langage, ceux que vous avez écrits et ceux de divers frameworks - qui forment un programme complet.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Nommer la structure essentielle à tout programme Java.
- Comprendre le rôle des accolades et des points-virgules pour séparer les parties d’un programme Java.
- Expliquer l’utilité d’une bonne indentation.
Critères de succès
- Je peux créer un fichier .java et écrire le code de base pour un programme Java.
- Je peux lancer un programme Java au terminal et résoudre des erreurs de syntaxe, au besoin, pour le faire fonctionner.
Exemple - un programme qui affiche “Bonjour” à la console
Voici les étapes pour produire ce programme :
- Créer un fichier qui s’appelle
Bonjour.java- l’extension.javaest important. D’autres éléments du nom seront expliqués dans la prochaine leçon.C’est possible que les outils de votre EDI suggèrent l’insertion d’une classe du même nom, p. ex.
public class Bonjour { }, dès que le fichier s’ouvre dans l’éditeur. Vous devrez effacer ce code afin de maintenir la structure minimale pour ce programme.2 - Définir une méthode
main. Les deux accolades{}représentent les limites du contenu de la méthode.void main() {}Si vos outils Java sont activés, vous devrez voir deux liens :
Run | Debugapparaître au-dessus de la méthodemain. Cela signifie que le compilateur Java a reconnu la méthodemaincomme le point d’entrée du programme. - C’est utile de taper
Entréeentre les deux accolades pour créer un espace pour les instructions. Vous verrez que l’accolade fermante est placée directement sous le début de la lignevoid main()tandis que le curseur est indenté vers la droite. Cela est une convention de format pour nous aider à voir que les accolades sont bien fermées pour les différents blocs de code.void main() { } - Ajouter des instructions à l’intérieur de la méthode
main, soit entre ces deux accolades. Dans ce cas-ci, on inclut une seule instruction qui affiche le texte “Bonjour!” à la sortie du système (la console)void main() { System.out.println("Bonjour!"); }Notez que l’instruction se termine avec un point-virgule
;. C’est nécessaire pour toutes les instructions Java. - Lancez le programme avec le bouton
Run- soit celui au-dessus de la méthodemaindans l’éditeur, soit le boutonPlayen haut à droite de VS Code.Normalement, je préfère lancer les programmes au terminal avec ma propre commande soit
java NomDuFichier.java(ici ce seraitjava Bonjour.java) mais la structure simplifiée présentée ici exige une commande un peu plus complexe en date de Java23java --enable-preview NomDuFichier.java. - Vous devriez voir le message “Bonjour!” affiché à la console, sinon un message d’erreur s’il y a un problème avec le code. Les messages d’erreur incluent plusieurs informations pour vous aider à trouver le problème, notamment le numéro de ligne où le programme a planté.
Indentation
L’indentation dans l’exemple ci-dessus est très important pour la lisibilité du code et pour vérifier que les accolades sont bien fermées. Notez que l’accolade fermante est visible directement en dessous de la définition de la structure qu’elle ferme (ici la méthode, mais il y en aura d’autres). C’est une convention de style très utile parce que c’est facile d’oublier ou d’effacer une accolade par accident.
VS Code devrait créer cette indentation automatiquement, mais c’est facile de le briser en modifiant ou en déplaçant du code. Utiliser régulièrement la commande “Mettre le document en forme” (dans VS Code : Alt+Shift+F ou clic droit > “Mettre le document en forme”) pour maintenir une indentation correcte. Voici des moments quand vous devriez utiliser cette commande :
- après avoir copié-collé un exemple de code
- après avoir déplacé des instructions ou un bloc de code que vous avez écrit
- si vous ne voyez plus les accolades fermantes sous la signature du bloc de code (comme
void main()) parce qu’il y a d’autre code dans le chemin - si toutes vos instructions dans un même bloc de code ne sont pas alignées verticalement
- avant de rendre un programme lors d’une évaluation
Erreurs de syntaxe communes
Notez que “Mettre le document en forme” ne fonctionne pas s’il y a des erreurs de syntaxe, soit du code qui n’est pas compris par le compilateur Java. Si les outils Java sont activés, ces erreurs seront signalés pendant que vous tapez votre code : l’endroit de l’erreur est souligné en rouge. Si vous passez votre curseur sur cet endroit, vous pouvez lire dans une info-bulle un message décrivant l’erreur. Si les outils Java ne sont pas activés, vous verrez le même message d’erreur et des informations sur son endroit dans le code quand vous tentez de lancer le programme.
Voici quelques exemples d’erreurs communes :
- des
{,(,;ou des"manquants ou de surplus dans le code - mauvaise capitalisation d’un mot, p. ex.
stringau lieu deString - mot mal écrit, p. ex.
print1n(le chiffre 1) au lieu deprintln(la lettre L minuscule) - du texte qui n’est pas emballé dans des guillemets (
") -> ce texte est alors interprété comme le nom de quelque chose qui devrait exister dans le code mais qu’on ne trouve pas.
Exercices
📚 Tester la compréhension
Quiz de vérification sur la structure d’un programme Java
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices
- Créez un fichier
Salut.javaet écrivez le code pour afficher le message “Salut gang!” à la console. Assurez-vous que le code fonctionne. - Créez un dossier
capturesdans votre répertoire de travail. - Prenez une capture d’écran du lancement réussi de votre programme au terminal et l’enregistrez dans “captures”. Nommez le fichier
4-1-Structure.png.Sur Windows, l’outil de capture d’écran se lance avec la touche
Windows+Shift+S. Une fois l’image capturé, cliquez sur l’icône de notification pour ouvrir l’éditeur des captures. Enregistrez l’image dans le dossier “captures” de ce dossier. - Faites un commit et synchronisez vos changements avec GitHub.
À la fin de cet exercice, votre répertoire devrait avoir la structure et le contenu suivants :
pratique-[votre nom]
|---captures
| `---4-1-Structure.png
|---README.md
`---Salut.java
-
mainn’est pas juste le point d’entrée pour les programmes Java. C’est une convention qui se trouve implicitement ou explicitement dans un grand nombre de langages, comme Python, C++, C#, Go, etc. ↩ -
La déclaration implicite d’une classe (ne pas avoir à déclarer une classe dans le code source) est une simplification permise pour les petits projets depuis Java22 et le JEP463. Cette simplification permet aussi une méthode
void main()comme point de départ pour le programme. ↩ ↩2 ↩3
Accueil > Programmer avec Java >
🛠️ Communication pour les développeurs
Cette page est une référence, même une liste de vérification, pour l’ensemble de vos travaux. Vous pouvez revenir à cette page pour vous assurer que vous avez tout ce qu’il vous faut en termes de communication à l’intérieur de vos programmes.
Notez qu’il y a souvent des éléments de communication externes (comme le nom des fichiers, le format de divers documents de planification ou preuves, la façon de rendre vos travaux, etc.) qui ne sont pas inclus ici.
- Identifiants - Règles
- Identifiants - Conventions
- Identifiants - Qualité descriptive
- Explications - Commentaires de ligne, de bloc
- Description du contenu - Javadoc
Survol et attentes
Créer des algorithmes est difficile. Combiner un paquet d’algorithmes faits par différentes personnes ou par la même personne à différents moments est encore plus difficile!
C’est donc important de rendre le code le plus clair possible en choisissant des noms appropriés et en laissant des commentaires descriptifs et explicatifs dans le code là ou nécessaire.
Définitions
- Identifiant
-
un identifiant est un mot avec une syntaxe valide en Java qui représente une classe, une méthode, une variable ou une constante. Les caractéristiques principales d’un identifiant sont qu’il doit être unique dans son contexte et qu’il doit être descriptif.
La leçon précédente a déjà introduit les classes et les méthode, mais nous verrons dans des leçons ultérieures exactement c’est quoi une variable et une constante.
- Convention de nommage
-
pratiques communes qui rendent le code plus lisible et plus facile à comprendre. Si ces règles ne sont pas respectées mais la syntaxe est encore valide, le code fonctionnera mais sera difficile à lire et à maintenir.
- Commentaires de ligne ou de bloc
-
des annotations dans le code qui expliquent le code, notamment la logique des algorithmes, mais qui sont ignorées lors de la conversion du code en langage machine. Les commentaires de ligne débutent par
//et les commentaires de bloc sont emballés entre/*et*/. - Documentation interne
-
commentaires descriptifs qui aident les autres développeurs à comprendre le code. Avec Java, cette documentation se fait avec le javadoc. Les outils de votre EDI reconnaissent généralement le javadoc et présentent des info-bulles avec le contenu du javadoc quand votre curseur se trouve sur le nom d’un élément documenté. Le javadoc précède immédiatement la déclaration (méthode ou variable globale) qu’il documente; il est emballé entre
/**et*/(notez le deuxième astérisque au début).
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Reconnaître si un identifiant respecte ou non les règles strictes de Java.
- Distinguer les classes, les méthodes, les variables et les constantes en appliquant les conventions de nommage de Java.
- Distinguer les trois types de commentaires en Java et décrire la fonction de chacun.
Critères de succès
- Je peux nommer descriptivement les classes, les méthodes et les variables dans le code en applicant les règles et les conventions de Java.
- Je peux ajouter des commentaires explicatifs dans le code, notamment pour la déclaration de variables et pour les structures de contrôle (sélection, itération).
- Je peux écrire le javadoc pour la classe et ses méthodes.
Règles Java pour les identifiants
Les règles suivantes s’appliquent quand vous choisissiez des noms pour les classes, les méthodes, les variables et les constantes dans Java. Le programme plantera si ces règles ne sont pas respectées:
- Caractères permis : L’identifiant est composé uniquement des caractères
a-z,A-Z,0-9,_et$. Notez qu’il n’y a pas d’espaces dans cette liste. Les lettres avec accents sont aussi acceptés, mais à cause de la complexité des différents encodages de caractères, il est préférable de les éviter. - Les majuscules et les minuscules font une différence : Les identifiants sont sensibles à la casse. Le même mot écrit avec des majuscules ou des minuscules fait référence à deux identifiants distincts.
- Aucun chiffre au début : Les identifiants ne peuvent pas commencer par un chiffre.
- Pas un mot clé : Les identifiants ne peuvent pas être des mots-clés Java, p. ex.
public,class,void,int,for,if, etc. Ces mots sont déjà définis par Java et ne peuvent pas être utilisés pour autre chose.
Conventions Java pour les identifiants
Différents langages encouragent différents styles de noms pour les identifiants pour les différents élements du programme. Cela aide les développeurs à associer une fonction à un identifiant simplement en observant sa forme.
Voici les conventions de Java.
Casse chameau pour les méthodes et les variables
Tous les noms de variables et de méthodes respectent la casse chameau (“camel case” en anglais) : toutes les lettres sont minuscules et chaque mot suivant commence par une majuscule. Par exemple : nomDeVariable, nomDeMethode().
Pourquoi le nom chameau? Parce que les majuscules au milieu des mots ressemblent aux bosses sur le dos d’un chameau.
Casse pascal pour les classes et les noms de fichiers
La casse pascal et comme la casse chameau, mais la première lettre est aussi une majuscule. Par exemple : NomDeClasse.
C’est vraiment important d’écrire les noms de classe avec une majuscule initiale pour les distinguer des variables et des méthodes. C’est une convention de nommage très répandue même au-delà de Java.
Pourquoi le nom pascal? C’est un hommage à Pascal, un langage de programmation historiquement important qui utilisait cette convention.
En Java, le nom du fichier doit avoir le même nom que la classe qu’il contient. Si la classe s’appelle NomDeClasse, le fichier doit s’appeler NomDeClasse.java. Ainsi, tous les noms de fichiers seront également en casse pascal. Dans notre cas, où la déclaration de la classe sera implicite, il faut tout de même nommer le fichier avec la casse pascal parce que le fichier et la classe sont liés.
Casse serpent avec majuscules pour les constantes
Pour indiquer qu’une variable ne change jamais de valeur, soit qu’elle est constante, on utilise une casse spéciale. Les constantes sont écrites en majuscules avec des soulignements pour séparer les mots. Par exemple : NOM_DE_CONSTANTE.
Pourquoi le nom serpent? Possiblement parce qu’en chaînant les mots avec des soulignements, on imagine les segments du corps d’un serpent. Possiblement parce que les soulignement ressemblent à des serpents au sol. Le nom n’est pas officiel, mais il est communément utilisé depuis au moins 2004.
Résumé des conventions
| Élément | Convention | Exemple |
|---|---|---|
| Classe, Fichier | Casse pascal | String, System |
| Méthode | Casse chameau | main(), calculateAge(), testMainWithInvalidData() |
| Variable | Casse chameau | age, totalAmount, userInput |
| Constante | Casse serpent | MAX_VALUE, PI, DEFAULT_NAME |
Identifiants descriptifs
Si les conventions aident les développeurs à reconnaître la fonction générale d’un identifiant, les mots utilisés dans l’identifiant les aident à comprendre plus spécifiquement ce que l’identifiant représente dans le programme.
C’est extrêmement important de choisir des noms descriptifs pour tous les identifiants tant pour vous aider à comprendre le sens de ce que vous tentez d’accomplir que pour communiquer ce sens aux autres développeurs.
Cela s’applique pour tous les langages de programmation.
Exemple
Que veux dire l’expression suivante?
a = b * c;
À part savoir qu’on assigne le produit de deux valeurs à une troisième valeur, c’est impossible de le savoir.
Maintenant, que veux dire l’expression suivante?
areaOfRectangle = length * width;
ou
weeklyPay = hoursWorked * hourlyRate;
Ces deux expressions on exactement la même forme que le premier exemple, mais on peut savoir pourquoi on l’a utilisé dans chaque cas. C’est parce que les identifiants ont été nommés de manière descriptive.
Note : même si on travaille en français, il est préférable d’utiliser l’anglais pour les identifiants parce que les mots-clés du langage sont en anglais. Ainsi, le code est plus facile à lire et on évite les problèmes de caractères spéciaux (p. ex.
é,ç,à, etc.).
Commentaires explicatifs - commentaires de ligne ou de bloc
Parfois simplement respecter les conventions de nommage et la pratique de noms descriptifs, il ne reste pas grande chose à expliquer dans le code. Mais il y a des moments où un commentaire est nécessaire pour expliquer un choix de variable ou un algorithme particulier. C’est là que les commentaires explicatifs ont leur place.
Les commentaires sont ignorés par le compilateur, donc ils n’ont pas d’impact sur le fonctionnement du programme. Ainsi, on devrait les écrire en français dans un langage naturel qui nous convient.
C’est un art de trouver à quel point les commentaires explicatifs passent d’utile à redondant. Lorsqu’il y a trop de commentaires ou les commentaires dupliquent l’information dans les identifiants descriptifs, ils nuisent à la clarté du code. En contrepartie, s’il n’y a pas assez de commentaires, la logique de certaines parties du code peut être difficile à suivre. EN CAS DE DOUTE, surtout comme novice, il vaut mieux en mettre un peu trop que pas assez.
Syntaxe des commentaires
Il y a deux façons de laisser des commentaires dans le code Java :
- Les commentaires de ligne suivent deux barres obliques
//et se limitent à la ligne sur laquelle ils sont écrits. - Les commentaires de bloc s’étendent entre les délimiteurs
/*et*/ce qui leur permet de couvrir plusieurs lignes, au besoin.
Exemple de commentaire de ligne
On suit souvent la déclaration d’une variable avec un commentaire de ligne pour expliquer pourquoi on a choisi une valeur initiale particulière ou pour indiquer comment il sera utilisé plus loin, si ce n’est pas déjà assez clair par le nom de la variable.
int age; // conservera l'âge fourni par l'utilisateur
Si on arrive à une structure de contrôle (comme une sélection ou une boucle), on précède souvent la structure avec un commentaire pour expliquer le but de la structure. Si l’explication est courte, ce commentaire peut-être un commentaire de ligne.
// Décider si l'utilisateur peut voter
if (age > 18) {
System.out.println("Vous pouvez voter!");
} else {
System.out.println("Vous ne pouvez pas voter.");
}
Finalement, certaines opérations complexes peuvent être expliquées avec un commentaire de ligne.
// La distance entre deux points (x1, y1) et (x2, y2)
int dx = x2 - x1;
int dy = y2 - y1;
double distance = Math.sqrt(dx * dx + dy * dy);
Exemple de commentaire de bloc
Le commentaire de bloc est utilisé comme en-tête d’un fichier, pour présenter des informations comme la description, comment l’utiliser, qui l’a fait, s’il y a une licence spécifique attachée au code, etc.
/*
Nom de la classe : Salut
Description : Un programme simple qui affiche un message de salutation.
Auteur : David Crowley
Date de création : 2023-09-01
*/
On utilise aussi un commentaire de bloc si la logique d’un algorithme ne peut pas s’expliquer sur une seule ligne.
/*
On gagne si on atteint 100 points ou plus.
On perd si on atteint 20 tentatives.
On quitte en milieu du jeu si l'utilisateur a tapé "q".
*/
if (points >= 100) {
System.out.println("Vous avez gagné!");
} else if (attempts >= 20) {
System.out.println("Vous avez perdu.");
} else if (userInput.equals("q")) {
System.out.println("Vous avez quitté le jeu.");
}
Notez que vous pouvez aussi utiliser plusieurs commentaires de ligne une après l’autre au lieu d’utiliser un commentaire de bloc. C’est ce qui arrive souvent, parce qu’on ne réalise pas la longueur du commentaire avant de l’écrire.
Documentation interne - Javadoc
Ceci est un sujet qui est plus avancé. Nous l’utiliserons pas dès le début, contrairement aux autres sujets de cette leçon. La section demeure ici pour référence future.
Les commentaires explicatifs sont utiles pour présenter notre logique lorsqu’un développeur lit les détails internes de notre code. Mais c’est aussi pratique de connaître le contenu d’une classe ou la structure d’une méthode même sans lire le code. C’est là que la documentation interne entre en jeu.
La documentation interne, appelé javadoc en Java, est un format de commentaire spécial qui est reconnu par les outils Java pour générer de la documentation officielle. Les outils Java vous affichent le contenu de ces commentaires dans l’auto-complétion (lorsque vous tapez votre code) et dans les info-bulles (lorsque votre souris passe sur un identifiant).
Pour créer un commentaire javadoc :
- on utilise un commentaire de bloc avec un
*supplémentaire au début. Le bloc commence alors par/**(deux astérisques) et se termine par*/. - Le javadoc doit être placé immédiatement devant la déclaration de la classe ou de la méthode qu’il documente. Sinon, les outils Java ne sauront pas à quoi il se réfère : il sera considéré comme un simple commentaire de bloc.
- C’est mieux d’écrire le javadoc après avoir écrit le code. Les outils de votre EDI peuvent alors ajouter plusieurs détails automatiquement avec le bon format, vous laissant juste la tâche d’ajouter les descriptions.
- Votre EDI ajoutera probablement des
*supplémentaires pour chaque ligne du javadoc. C’est une convention pour rendre le commentaire plus lisible, mais ces astérisques internes ne sont pas nécessaires pour que le javadoc fonctionne.
Format général pour le javadoc d’une méthode
Les paramètres (les
@param) et la valeur de retour (le@return) sont des sujets plus avancés qui seront traités plus tard dans le cours. Pour l’instant, si on demande le javadoc d’une méthode, on s’attend à voir juste sa description.
/**
* Description de la méthode.
*
* @param nomParamètre Description du paramètre
* @param nomAutreParamètre Description de l'autre paramètre
* @return Description de la valeur de retour
*/
Exercices
📚 Tester la compréhension
Quiz de vérification sur les identifiants et les commentaires
🛠️ Pratique
Travaillez dans le dépôt “pratique” partagé par votre enseignant. Si vous l’avez déjà clôné, simplement l’ouvrir dans VS Code.
Votre répertoire devrait avoir la structure et le contenu suivants avant de commencer les exercices :
pratique-[votre nom]
|---captures
| `---4-1-Structure.png
|---README.md
`---Salut.java
Dans le programme Salut.java que vous avez fait précédemment :
- Ajouter un commentaire de bloc comme en-tête du fichier pour expliquer ce que le programme fait.
- Ajoutez le javadoc sur la méthode
main. Notez dans la description quelles parties du commentaire ont été ajoutées automatiquement par votre EDI. - Ajoutez un commentaire de ligne pour expliquer ce que l’instruction
System.out.println("Salut gang!");fait. - Prendre une capture d’écran du code quand votre curseur est sur le nom de la méthode
main(et l’info-bulle est affiché) et l’enregistrer dans “captures”. Nommez le fichier4-3-Communication.png.
Accueil > Programmer avec Java > Les bases de Java >
Afficher des messages à la console - partie 1
Survol et attentes
Tout programme doit communiquer avec l’utilisateur. Les programmes lancés via la console affichent des messages texte. Cette leçon vous montre comment le faire de différentes façons en Java.
Définitions
- System.out
- objet Java qui représente la sortie par défaut de l’ordinateur, soit où les messages de votre programme seront affichées. Par défaut, c’est la console (comme le terminal PowerShell).
- print()
- méthode de l’objet
System.outqui affiche un message sans passer à la ligne suivante. Elle prend un seul argument, le message à afficher. - println()
- méthode de l’objet
System.outqui affiche un message et passe à la ligne suivante. On peut aussi l’utiliser sans message juste pour passer à la ligne suivante à la console. - caractère d’échappement
- caractère spécial dans un message texte qui indique à l’ordinateur de faire quelque chose de spécial, comme un retour à la ligne (
\n) ou insérer une double guillemet (\").
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Distinguer les deux méthodes d’affichage de base dans Java :
printetprintln - Reconnaître le caractère d’échappement
\nl’utiliser dans des Strings pour gérer l’affichage.
Critères de succès
- Je peux utiliser les méthodes
printetprintlnpour afficher des messages texte efficacement à la console.
print et println
Voici le contenu d’un fichier nommé SimplePrinting.java :
void main() {
System.out.print("Bonjour ");
System.out.println("tout le monde!");
System.out.println("Comment ça va?");
}
Et voici sa sortie :
Bonjour tout le monde!
Comment ça va?
Notez que la première instruction, System.out.print("Bonjour ");, n’a pas de retour à la ligne parce qu’on a utilisé la méthode print(). Alors le texte de la deuxième instruction, System.out.println("tout le monde!");, continue sur la même ligne. Puisque cette instruction utilise la méthode println() le texte à afficher avec la troisième instruction, System.out.println("Comment ça va?"); est sur une nouvelle ligne. Cette dernière instruction utilise aussi la méthode println(), alors le curseur se trouve à la ligne suivante après l’affichage du message.
Insérer un retour de ligne manuellement : les caractères d’échappement
On peut insérer des retours de ligne manuellement dans les messages à afficher en utilisant le caractère d’échappement \n. Voici un exemple dans le fichier LineReturns.java :
void main() {
System.out.println("Bonjour\n tout\n le\n monde!");
}
Et voici sa sortie :
Bonjour
tout
le
monde!
Notez que le caractère \n est remplacé par un retour à la ligne dans le message affiché, alors chaque mot dans le message est sur une ligne séparée. Les mots sont aussi décalés de plus en plus vers la droite parce qu’on a inclut plus d’espaces après chaque caractère \n.
Il y a d’autres caractères d’échappement comme
\"pour insérer une double guillemet dans un message entre guillemets. Voir cette page pour une liste complète.
Exercices
📚 Tester la compréhension
Quiz de vérification sur print, println et \n
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices
But : produire la sortie suivante à la console :
MESSAGE 1
Ceci est une phrase simple
MESSAGE 2
Ceci
est
une phrase
simple
MESSAGE 3
Ceci est une
phrase simple
- Créez un fichier
Print1.javaet y ajouter la structure de base (méthodemain). Utilisez trois fois la méthodeprintlnpour afficher ces trois lignes : “MESSAGE 1”, “MESSAGE 2” et “MESSAGE 3”. - En dessous de “MESSAGE 1”, afficher le message “Ceci est une phrase simple” en utilisant une fois la méthode
printet une fois la méthodeprintln. - En dessous de “MESSAGE 2”, afficher le message “Ceci est une phrase simple” sur quatre lignes une utilisant une seule fois la méthode
printlnet en utilisant le caractère d’échappement\n. - En dessous de “MESSAGE 3”, afficher le message “Ceci est une phrase simple” sur deux lignes en utilisant une seule fois la méthode
printet en utilisant le caractère d’échappement\n. - Assurez-vous de laisser une ligne vide après chaque message pour séparer les messages. Pour y arriver, utilisez un
printlnvide ou un caractère d’échappement\nadditionnel à la fin de chaque message. - Prenez une capture d’écran du terminal incluant les commandes pour lancer le programme et la sortie complète. Nommez la capture “4-1-3-print.png” et ajoutez-la au dossier “captures” de votre projet.
Accueil > Programmer avec Java > Les bases de Java >
📚 Données (int, double, boolean, char, String)
Survol et attentes
Les programmes informatiques sont créés pour manipuler et gérer des données. On connaît la représentation interne de différents types de données, mais les langages de haut niveau ont leurs propres représentations.
Définitions
- type
- format de donnée spécifique, représenté par un mot-clé ou le nom d’une classe en Java. Les types de base sont :
int,double,boolean,charetString. Les types sont directement liés à la leçon sur la représentation interne des données. - valeur littérale
- une valeur écrite directement dans le code, comme
0,3.14159,true,'A',"David". En Java, on doit entourer une valeur littérale de typecharavec des apostrophes'et une valeur littérale de typeStringavec des guillemets". - variable
- nom représentant une adresse en mémoire qui stocke une donnée. En Java, les variables sont fortement typées elles doivent être déclarées avec un type spécifique et ne peuvent pas changer de type dans le code. En Java, les variables sont aussi statiquement typées : le type de chaque variable est déterminé à la compilation du code et ne peut pas changer durant l’exécution du programme. Ces restrictions réduisent énormément les erreurs dans le code liées aux types de données.
- déclaration de variable
- indiquer le type de donnée et le nom de la variable. Par exemple :
int count;,double pi;,boolean isRaining;,char letter;,String name;. Les noms doivent respecter les règles et la convention de nommage des identifiants. - assignation de valeur
- donner une valeur à une variable. L’opérateur d’assignation dans Java est le
=. Par exemple :count = 0;,pi = 3.14159;,isRaining = true;,letter = 'A';,name = "David";. - initialisation d’une variable
- L’assignation d’une première valeur à une variable.
- réassignation
- donner une nouvelle valeur à une variable déjà initialisée, remplaçant la valeur précédente. Par exemple :
count = 1;,pi = 3.14;,isRaining = false;,letter = 'B';,name = "Alice";. - référence
- utiliser le nom de la variable (sans guillemets) pour accéder à sa valeur. Par exemple :
System.out.println(name);. Le nom doit être sans guillemets pour que Java le cherche parmis les variables déclarées dans votre programme. La variable doit être initialisée avant d’y faire référence dans le code.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Identifier les types de données les plus communs en Java.
- Reconnaître les valeurs littérales pour les types de données les plus communs.
- Reconnaître le format de déclaration et d’initialisation d’une variable.
Critères de succès
- Déclarer et initialiser des variables de type
int,double,boolean,charetString. - Assigner de nouvelles valeurs aux variables déclarées et faire référence à ces variables dans le code.
Types de données de base
Les types Java de base sont :
| Type | Description | Valeurs littérales | Exemples de déclarations |
|---|---|---|---|
int | nombre entier | 0, 1, -1, 2, -2, … | int count; int age = 16; |
double | nombre décimal | 0.0, 1.0, -1.0, 2.0, -2.0, … | double pi; double temperature = 20.5; |
boolean | valeur logique | true ou false | boolean isRaining; boolean isSunny = true; |
char | caractère unique | ‘a’, ‘b’, ‘c’, … | char letter; char grade = 'A'; |
String | texte (aussi appelé une “chaîne de caractères” d’où le nom en anglais) | “Bonjour”, “Au revoir”, “A”, “B”, … | String name; String message = "Bonjour"; |
Déclaration de variables
Le format pour la déclaration d’une variable est le suivant :
type nom;
par exemple :
int count;
double pi;
boolean isRaining;
char letter;
String name;
Initialisation de variables
Pour initialiser une variable, on doit lui assigner une première valeur. Le symbole = est utilisé en Java pour signifier que la variable à la gauche stocke maintenant la valeur à la droite.
Si la variable est déjà déclarée on utilise seulement son nom du côté gauche :
nom = valeur; // initialiser ou assigner une valeur à une variable qui existe déjà
On peut aussi donner une valeur initiale lors de la déclaration de variable, donc la déclaration complète serait du côté gauche :
type nom = valeur; // déclaration et initialisation en une seule ligne
Voici quelques exemples :
// ces variables ont été déclarées dans l'exemple précédent
count = 0;
pi = 3.14159;
isRaining = true;
letter = 'A';
name = "David";
// ces nouvelles variables sont initialisées durant la déclaration
double sum = 2.0 + 3.1; // assigner la somme de deux nombres
String answer = ""; // assigner le texte vide comme valeur initiale
int sum = 0;
Ordre des opérations dans une assignation de valeur
L’opération à droite du symbole = est effectuée avant l’assignation de la valeur à la variable à gauche. Par exemple, dans l’exemple double sum = 2.0 + 3.1;, la somme de 2.0 et 3.1 est calculée avant d’être assignée à la variable sum.
Ceci est très utile si on veut changer la valeur d’une variable par un montant fixe. Par exemple, count = count + 1; ajoute 1 à la valeur actuelle de count. Cette expression n’est pas une équation mathématique, mais plutôt une opération spécifique (l’assignation) qui est effectuée en deux étapes : d’abord, le côté droit est évalué, puis le résultat est assigné au côté gauche.
Exemple concret
Voici un court exemple dans le contexte d’un programme Java complet :
void main() {
int age = 16;
String name = "Myriam";
System.out.print(name);
System.out.print(" a ");
System.out.print(age);
System.out.println(" ans.");
}
et sa sortie serait :
Myriam a 16 ans.
Exercices
📚 Tester la compréhension
aucun quiz de vérification des concepts ici encore
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices
- Créer un fichier
Variables.javadans votre répertoire de travail. Assurez-vous d’y ajouter la structure de base (méthodemain). - Initialiser une variable de type approprié pour chacune des valeurs suivantes et affichez chacun individuellement avec
System.out.println().3-8.2true"texte"'@'
- Réassigner une nouvelle valeur à chaque variable du numéro précédent et affichez chacun de nouveau avec
System.out.println(). - Prenez une capture d’écran du lancement réussi de votre programme au terminal et l’enregistrez dans le dossier “captures” avec le nom
4-2data.png
Indice: N’entourez pas le nom de votre variable avec des guillemets
"dansSystem.out.println(). Ceci affichera le nom de la variable au lieu de sa valeur.
Accueil > Programmer avec Java > Les bases de Java >
Afficher des messages à la console - partie 2
Survol et attentes
Parfois on a besoin de plus de contrôle sur le format de messages ou simplement une façon plus efficace d’afficher plusieurs informations à la console. Cette leçon vous montre comment utiliser la méthode printf pour afficher des messages formatés en Java.
Définitions
- printf()
-
méthode de l’objet
System.outqui affiche un message formaté. Il prend un nombre variable d’arguments : le premier est le message formaté, les autres sont les valeurs à insérer dans le message :System.out.printf("message avec drapeaux pour les valeurs", valeur1, valeur2, ...); - drapeaux de formatage
-
caractères spéciaux dans un message formaté qui gardent une place pour une valeur de type spécifique. Par exemple,
%spour une valeur de typeString,%dpour une valeur de typeintet%fpour une valeur de typedouble. - concaténation
-
coller du texte ensemble. En Java, l’opérateur
+agit comme opérateur de concaténation si au moins un des opérandes est unString. L’autre opérande sera converti automatiquement enStringpour l’opération. La concaténation se propage de gauche à droite, alors l’expression"a" + 1 + 2donne"a12"; pour obtenir"a3", il faut utiliser des parenthèses autour de l’addition :"a" + (1 + 2).
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Comprendre la méthode
printfet ses arguments - Reconnaître les drapeaux de formatage les plus communs pour la méthode
printf, notamment%d,%fet%s.
Critères de succès
- Je peux utiliser la méthode
printfpour afficher des données efficacement à la console.
Messages formatés : printf
Vous pouvez utiliser la méthode printf() pour afficher des messages formatés. C’est utile quand vous :
- essayez de coller plusieurs valeurs ensemble dans une phrase.
- voulez contrôler le nombre de chiffres après la virgule pour un nombre décimal.
- voulez afficher des valeurs en colonnes de largeur fixe.
Vous verrez que pour la plupart des situations, vous pouvez utiliser des print, des println et de la concaténation pour afficher ces messages au lieu d’utiliser printf : dans ces cas, c’est une préférence personnelle. Par contre, pour l’affichage uniforme des valeurs décimales ou pour l’alignement du texte, printf est la seule solution raisonnable.
Exemple - Coller des valeurs dans une phrase
Reproduire cet exemple dans un fichier nommé PrintGlue.java et tester la sortie.
Rappel : c’est toujours mieux de taper les exemples vous-même (et découvrir ce que vos outils vous aident à compléter, où se trouvent les symboles sur le clavier, etc.) que de copier-coller l’exemple. Vous gagnerez plus de confiance avec votre capacité à produire du code. C’est la différence entre CRÉER (taper) et UTILISER (copier-coller) du code, même si le code final est le même.
void main() {
String name = "Malcolm";
int age = 16;
// AVEC PLUSIEURS PRINT ET PRINTLN (sans concaténation des valeurs)
System.out.print("Mon nom est ");
System.out.print(name);
System.out.print(" et j'ai ");
System.out.print(age);
System.out.println(" ans.");
// AVEC PRINTLN (et concaténation des valeurs)
System.out.println("Mon nom est " + name + " et j'ai " + age + " ans.");
// AVEC PRINTF
System.out.printf("Mon nom est %s et j'ai %d ans.\n", name, age);
}
et la sortie identique pour les trois approches :
Mon nom est Malcolm et j'ai 16 ans.
Mon nom est Malcolm et j'ai 16 ans.
Mon nom est Malcolm et j'ai 16 ans.
Structure de la méthode printf
La méthode printf accepte un nombre variable d’arguments. Le premier argument est toujours le String qui définit le format du message à afficher, incluant le texte de base et des drapeaux de formatage pour les valeurs à insérer dans le message. Les prochains arguments sont les valeurs à insérer dans le message, remplaçant chaque drapeau.
System.out.printf("message avec drapeaux pour les valeurs", valeur1, valeur2, ...);
Dans dans l’exemple System.out.printf("Mon nom est %s et j'ai %d ans.\n", name, age); :
- Le String de formatage est
"Mon nom est %s et j'ai %d ans.\n".- il y a deux drapeaux de formatage :
%spour une valeur de typeStringet%dpour une valeur de typeint. - Il y a aussi le caractère d’échappement pour le retour de ligne,
\n, parce queprintfne l’inclut pas; c’est commeprint.
- il y a deux drapeaux de formatage :
- Le prochain argument est
name(de type String qui s’évalue à “Malcolm”). Sa valeur remplacera le%s, le premier drapeau de formatage. - Le dernier argument est
age(de type int qui s’évalue à 16). Sa valeur remplacera le%d, soit le dernier drapeau de formatage.
Voici un tableau de quelques drapeaux de formatage communs :
| Drapeau | Type de valeur | Exemple |
|---|---|---|
%s | String | "Bonjour %s" |
%S | String en majuscules | "Bonjour %S" |
%d | int en décimal | "La valeur du rouge est %d" |
%x | int en hexadécimal | "La valeur du rouge est #%x" |
%f | double | "Le prix est de %f" |
Exemple - Contrôler le nombre de chiffres après la virgule pour un nombre décimal
Voici quelques exemples que vous pouvez tester dans une session jshell. Lancez la commande jshell dans un terminal pour ouvrir une session jshell. Quittez la sesssion avec la commande \exit.
double PI = 3.141592653589793; // constante pour la valeur de pi
System.out.printf("La valeur de pi est %f.\n", PI);
System.out.printf("La valeur de pi est %.2f.\n", PI);
sortie :
La valeur de pi est 3.141593.
La valeur de pi est 3.14.
Comme le premier exemple, le premier argument est le String qui définit le format du message. Dans ce cas on utilise le drapeau %f pour une valeur de type double. La valeur à insérer est 3.141592653589793. Par défaut, printf affiche 6 chiffres après la virgule pour les nombres décimaux. Pour contrôler le nombre de chiffres après la virgule, on peut ajouter un point et un nombre entre le % et le f.
Dans le deuxième exemple, on a ajouté .2 pour afficher seulement 2 chiffres après la virgule. Le .2 est un élément optionnel dans le drapeau de formatage pour les valeurs décimales. On peut remplacer 2 par n’importe quel nombre pour afficher ce nombre de chiffres après la virgule.
Voici un tableau présentant quelques options pour le formatage des valeurs décimales :
| Drapeau | Exemple | Sortie |
|---|---|---|
%f | "La valeur de pi est %f" | 3.141593 |
%.2f | "La valeur de pi est %.2f" | 3.14 |
%.0f | "La valeur de pi est %.0f" | 3 |
Exemple - Afficher des colonnes de valeurs alignées
// Afficher des valeurs en colonnes de largeur fixe
System.out.printf("%-10s %10s\n", "NOM", "ÂGE"); // en-têtes
System.out.printf("%-10s %10d\n", "Malcolm", 16);
System.out.printf("%-10s %10d\n", "Myriam", 17);
sortie :
NOM ÂGE
Malcolm 16
Myriam 17
Ici on a plusieurs instructions printf, une pour chaque ligne d’un tableau. La première instruction donne les en-têtes, donc les drapeaux de formatage dans le premier argument sont %s pour une valeur de type String. Pour spécifier la largeur de colonne, on peut ajouter des éléments optionnels entre % et le s. Dans ce cas :
- on a ajouté
-10pour spécifier une largeur de 10 caractères et un alignement à gauche. - on a ajouté
10pour spécifier une largeur de 10 caractères avec l’alignement par défaut (à droite). - comme avec les valeurs décimales, on peut remplacer
10par n’importe quel nombre pour spécifier la largeur de colonne voulue. - Notez que les valeurs substituées seront tronquées (coupées) si elles sont plus longues que la largeur de colonne spécifiée. Soit, le format spécifié est respecté même s’il faut couper le texte pour le faire.
Les arguments suivants sont les valeurs à insérer dans le message, dans l’ordre où ils apparaissent dans le message. Donc "NOM" est inséré à la place de %-10s et "ÂGE" est inséré à la place de %10s.
Pour les lignes suivantes, les valeurs pour “Âge” sont de type int, alors on utilise le drapeau %d au lieu de %s, mais on maintient les mêmes spécifications pour la largeur et l’alignement, donc %10d au lieu de %10s. Les valeurs à insérer sont 16 pour la première ligne et 17 pour la deuxième.
Voici un tableau présentant quelques options pour le formatage des colonnes :
| Drapeau | Exemple | Effet |
|---|---|---|
%-10s | "Le nom est %-10s" | colonne de 10 char de large, aligné à gauche |
%10d | "L'âge est %10d" | colonne de 10 char de large, aligné à droite |
%-10.2f | "Le prix est %-10.2f" | colonne de 10 char de large, aligné à gauche avec 2 places après la virgule |
Exercices
📚 Tester la compréhension
Quiz quiz de vérification sur printf
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices
- Créez le fichier
Print2.javaet y ajouter la structure de base (méthodemain). - Dans la méthode
main, reproduire les trois instructionsprintfci-dessus pour produire un tableau formaté pour les noms et les âges. - Changez la largeur de colonne pour les noms à 5 caractères.
- Lancez le programme et notez ce qui se passe à la sortie.
- Écrire un commentaire de bloc pour consigner vos observations.
- Changez la colonne “ÂGE” à une colonne “MOYENNE”.
- Ajouter des valeurs décimales raisonnables pour les moyennes de Malcolm et de Myriam et ajuster les drapeaux de formatage de façon appropriée.
- Lancez le programme et vérifiez qu’il fonctionne.
- Ajustez le drapeau de formatage pour les valeurs décimales pour afficher seulement 1 chiffre après la virgule. Lancez le programme de nouveau pour vérifier que ça fonctionne.
- Prenez une capture d’écran du terminal incluant les commandes pour lancer le programme et la sortie complète. Nommez la capture “4-1-5-print.png” et ajoutez-la au dossier “captures” de votre projet.
Accueil > Programmer avec Java > Les bases de Java >
Utiliser des méthodes
Survol et attentes
Définitions
- Fonction
-
un bloc de code nommé. Certaines fonctions sont définies afin de prendre des informations en entrée (appelées arguments) ou pour retourner une valeur en sortie.
- Méthode
-
une fonction liée à une classe ou un objet. On appelle les méthodes avec la notation pointée, soit
objet.methode(), où on suit le nom de l’objet par un point et ensuite le nom de la méthode. Des exemples simples sont les méthodesprintlnetprintde l’objetSystem.out: on l’appel avecSystem.out.println().Dans Java, parce que tout est défini dans une classe, toutes les fonctions sont des méthodes. Mêmes les programmes où on ne déclare pas une classe explicitement (comme les exemples dans ces notes de cours, Java déclare implicitement une classe pour nous qui emballe l’ensemble de notre code).
- Méthode d’instance
-
une méthode qui est appellée sur un objet. Les méthodes pour manipuler les
Stringsont des exemples communs, p. ex. :String s = "Bonjour"; s.length();où la méthode d’instancelengthest appellée sur l’objets. - Méthode statique
-
une méthode qui est appellée sur la classe directement, soit
Classe.methodeStatique(). Vous pouvez les repérez si les conventions de nommage sont respectées : le nom précédant le point commence avec une majuscule. Un exemple commun est la classeMathqui fournit plusieurs méthodes utilitaires commeMath.sqrt(9). - Appel
-
utiliser le nom d’une méthode pour exécuter son bloc de code. Si la méthode prend des arguments, il faut fournir ces informations séparées par des virgules entre les parenthèses de l’appel. Si la méthode retourne une valeur, on peut utiliser l’appel pour représenter cette valeur dans une expression, comme un calcul ou une assignation de valeur à une variable.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Expliquer les termes “appelle de méthode” et “argument”.
- Distinguer les appels de méthodes statiques (sur des classes) et d’instance (sur des objets).
Critères de succès
- Je peux utiliser des appels de méthodes statiques et d’instance, avec ou sans arguments et avec ou sans valeur de retour efficacement dans mes programmes Java.
Utilise jshell
C’est mieux de testez les exemples ici dans le REPL jshell parce que les résultats sont affichés immédiatement un-par-un. Tapez une seule ligne de code à la fois et appuyez sur Enter pour voir le résultat.
Méthodes d’instances de String
Voici quelques exemples de méthodes qu’on peut utiliser avec des variables de type String :
String name = "David";
name.length(); // le nombre de caractères
name.charAt(0); // le premier caractère
name.toUpperCase();
// conserver le résultat dans une variable
String lowerName = name.toLowerCase();
Méthodes statiques de la classe Math
Voici quelques exemples de méthodes statiques de la classe Math :
Math.sqrt(9); // racine carrée ("square root") -> sqrt
Math.abs(-5); // valeur absolue (ignore le signe)
Math.pow(10, 3); // puissance ("power") -> pow... 10^3
// conserver le résultat dans une variable
double chance = Math.random(); // aléatoire entre 0.0 et 0.9999999
chance * 100; // changer l'échelle (0.0 à 99.9)
25 + chance * 25 // changer l'échelle et la valeur initiale (25.0 à 49.9)
Un regard sur les méthodes print
Est-ce que println est une méthode d’instance ou une méthode statique?
System.out.println("Bonjour");
C’est une méthode d’instance! La variable out dans la classe System est un objet de type PrintStream (placez votre curseur sur le mot out dans un programme Java complet pour voir son info-bulle), et les PrintStream ont une méthode println().
On verra plusieurs autres types de données dans le cours, comme des
Random, desScanneret desFile, qui ont aussi des méthodes d’instance pour utiliser leurs objets.
Suggestions par votre EDI
Votre EDI devrait suggérer les méthodes d’instance ou les méthodes statique possibles dès que vous tapez le . après le nom de l’objet ou de la classe. Vous pouvez sélectionner une méthode dans la liste pour l’ajouter à votre code source. Quand les méthodes sont affichées dans la bulle de suggestion, vous voyez aussi le type des arguments et le type de retour.
Par contre, ce que vous faites au terminal - notamment les sessions jshell - ne bénificie pas de cette fonctionnalité.
Les outils Java prennent une minute ou plus pour s’activer pleinement après l’ouverture d’un projet dans VS Code. Ils ne s’activent jamais pleinement si vous n’avez pas configurez l’extension pour se lancer en mode Standard au lieu d’Hybrid. Si vous ne voyez rien ou vous voyez juste le message “Loading…” quand votre curseur est sur un nom comme
String, vous devrez attendre encore un peu.
Exercices
📚 Tester la compréhension
aucun quiz de vérification des concepts ici encore
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices
- Prenez une capture d’écran du terminal montrant les résultats de votre session jshell après avoir lancé les commandes pour les méthodes d’instance de
Stringdans les notes ci-dessus. Enregistrez l’image dans le dossier “captures” avec le nom4-3-String.png. - Prenez une capture d’écran du terminal montrant votre session jshell après avoir lancé les commandes pour les méthodes statiques de
Mathdans les notes ci-dessus. Enregistrez l’image dans le dossier “captures” avec le nom4-3-Math.png.
Utiliser les méthodes dans un programme
-
Créer un fichier
Methods.javadans votre dossier “pratique” et y ajouter le contenu suivant :void main() { String name = "David"; // Remplacez "David" par votre prénom name.length(); name.endsWith("d"); // remplacer "d" par la lettre à la fin de votre nom name.endsWith("s"); // cette lettre doit être différente à la précédente } /* Ajoutez vos commentaires sur le comportement ici : */ -
Lancez le programme et décrire ce qui s’est affiché dans le commentaire de bloc suivant
main. -
Parce qu’on n’est pas dans un REPL, pour voir le résultat des méthodes il faut les afficher explicitement :
- Placez votre curseur sur le nom de chaque méthode (
length,endsWith) et attendre que la bulle d’information apparaisse. Vous trouverez le type de retour de chaque méthode. - Au début de la ligne pour chaque méthode, ajouter la déclaration d’une variable du type approprié. P. ex.,
lengthretourne unint, donc vous pouvez ajouterint nameLength = name.length();. Faites la même chose pour lesendsWith(mais faites attention!endsWithretourne unboolean). - Ajoutez une ou plusieurs instructions
print,printlnouprintfpour afficher les valeurs des variables que vous avez déclarées à l’étape précédente.
- Placez votre curseur sur le nom de chaque méthode (
-
Tapez “name.” et choisissez une autre méthode que vous n’avez pas encore utilisée parmis celles qui sont suggérées. Le but est simplement l’exploration et le transfert de ce que vous avez appris à un contexte ouvert. Ajouter une valeur appropriée pour le ou les arguments requis, au besoin. Ajoutez une déclaration de variable pour le type de retour de cette méthode et affichez le résultat.
-
Prenez une capture d’écran montrant le code final et les résultats de votre programme au terminal. Enregistrez l’image dans le dossier “captures” avec le nom
4-3-Methods.png.
Accueil > Programmer avec Java > Les bases de Java >
📚 Importer des classes
Survol et attentes
Définitions
- Bibliothèque standard
-
un ensemble de code inclut avec tout langage de programmation qui fournit des outils pour accomplir des tâches communes. La bibliothèque standard de Java est composée de classes organisées en packages et inclut tout ce qui vient avec le JDK (Java Development Kit).
package-
structure dans Java qui correspond à un dossier dans le système de fichiers. Le mot-clé
packageest utilisé pour déclarer le package d’une classe et les outils de compilation de projet utilisent ces déclarations pour lier le code source correctement. Un projet simple dans un seul dossier n’a pas besoin de déclaration de package : Java place les classes automatiquement dans le package par défaut. Également par défaut, toutes les classes dans le même package peuvent se voir sans déclaration d’importation. import-
une déclaration qui permet d’utiliser des classes d’autres packages. La déclaration d’importation est placée au début du fichier, avant la déclaration de la classe. La structure de la déclaration est
import package.Class;. java.lang-
un package qui contient des classes de base pour Java, comme les classes
System,StringetMath. Ces classes sont inclus automatiquement dans tous les programmes Java. On peut voir le nom complet de ces classes en plaçant le curseur sur le nom de la classe dans le code et en observant l’info-bulle qui apparaît. java.util-
un package qui contient des classes utilitaires pour Java, comme
ScanneretRandomet aussi des classes pour les collections de données, commeArrayListetHashMap. On peut importer sur demande les classes de ce package avec la déclarationimport java.util.*;au début du fichier de code source. java.io-
un package qui contient des classes pour les entrées et les sorties, comme
FileetFileWriter. On peut importer sur demande les classes de ce package avec la déclarationimport java.io.*;. - Bibliothèque externe
-
code qui peut être ajouté à l’environnement de programmation mais qui n’est pas inclus par défaut et qui n’est souvent pas maintenu par les développeurs qui s’occupe de la bibliothèque standard. Ces bibliothèques sont souvent utilisées pour des tâches spécialisées. Parce que ces bibliothèques ne sont pas inclus dans le JDK, il faut configurer l’environnement de programmation pour les obtenir et les utiliser en plus de les importer explicitement.
On n’utilise pas de bibliothèques externes dans ce cours avant l’unité sur les applications. À ce moment, c’est possible qu’on explore une bibliothèque graphique (JavaFX ou Processing) ou une bibliothèque pour la computation physique (Phidgets).
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Expliquer la différence entre les classes dans le package
java.langet celles dans les autres packages de la bibliothèque standard de Java. - Décrire le format d’une déclaration d’importation.
- Expliquer la différence entre la bibliothèque standard de Java et une bibliothèque externe.
Critères de succès
- Vous pouvez importer des classes de la bibliothèque standard dans vos programmes.
Gabarit de programme avec importations standard
Voici un gabarit de structure de programme Java avec les importations nécessaires pour utiliser les classes dans les packages java.io et java.util. Vous pouvez copier ce gabarit pour commencer un nouveau programme.
/*
* En-tête de fichier
*/
import java.io.*; // importe sur demande les classes du package java.io
import java.util.*; // importe sur demande les classes du package java.util
void main() {
// code du programme
}
Note
Depuis JDK 25, les classes dans
java.utiletjava.iosont importés implictement (sans déclaration) comme si vous aviez déclaré leur importation. Bref, ces commandeimportne sont plus nécessaires depuis Java 25.
Exemples de déclarations de variables avec les types importés
import java.util.*;
void main() {
String myString; // pas besoin d'importation parce que String est dans java.lang
Scanner myScanner; // importation nécessaire pour utiliser java.util.Scanner
Random myRandom; // importation nécessaire pour utiliser java.util.Random
}
Si vous oubliez la déclaration d’importation, votre IDE peut généralement ajouter les importations nécessaires automatiquement. Dans VS Code, si vous tentez de déclarer un Scanner sans avoir ajouté la ligne pour l’importer, vous verrez une ligne ondulée rouge sous le nom de la classe indiquant une erreur. Si vous cliquez sur le nom souligné et tapez la commande Ctrl + . vous verrez une option pour ajouter l’importation nécessaire.
Les exemples ici n’initialisent pas les variables et ne les utilisent pas. On verra dans des leçons futures comment ces différents objets sont créés et utilisés.
Exercices
📚 Tester la compréhension
aucun quiz de vérification des concepts ici encore
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices.
- Créez un fichier nommé
Imports.javaet y ajouter les structures de base d’un programme Java. - Déclarez une variable de chaque type suivant :
StringScannerRandomFileLocale
- Lancez votre programme en vous assurant d’avoir inclut les lignes pour les importations. S’il n’y aucune erreur, aucune sortie du programme ne devrait s’afficher parce qu’il n’y pas d’instruction
printlnouprint. - Écrivez un en-tête de fichier pour votre programme. Inclure des sections “Description”, “Auteur” et “Date”.
- Prendre une capture d’écran pour les positions de curseur suivantes et enregistrez chacun dans le dossier “captures” :
- sur le mot
String(l’info-bulle affiche le nom complet de la classe) -> nom du fichier :4-4-String.png - sur le mot
Scanner(l’info-bulle affiche le nom complet de la classe) -> nom du fichier :4-4-Scanner.png
- sur le mot
- Créez un commit et un push pour synchroniser vos changements avec GitHub.
Accueil > Programmer avec Java > Les bases de Java >
Entrées et sorties à la console
Survol et attentes
Pour ajouter de l’interaction à un programme, il faut donner la chance à l’utilisateur de nous fournir une réponse. Dans le contexte d’un programme qui se lance à la console, cela veut dire capter les réponses tapées par l’utilisateur au clavier. Dans cette leçon, nous allons voir comment faire ça en Java.
Définitions
- Mot-clé
new - un mot-clé qui crée une nouvelle instance d’une classe (qui crée un objet). Ce mot-clé est suivi par une méthode spéciale de la classe appelée le constructeur. Chaque classe définit son propre constructeur, alors il faut connaître les détails de la classe pour créer des objets de cette classe. Votre EDI vous aide avec ces détails. La déclaration complète d’un nouvel objet est
Type nom = new Type(arguments, ...);. - Classe
Scanner - une classe qui nous permet de lire une source de texte comme la console, un String ou un fichier de texte. Un objet de type
Scannera accès à plusieurs méthodes d’instance pour retourner différents types de données. UnScannersaisie toujours du texte, donc les méthodes commenextInt()etnextDouble()convertissent le texte en nombre et peuvent planter si le format des caractères saisis ne correspond pas au type attendu. C’est pourquoi il y a aussi des méthodes commehasNextInt()ethasNextDouble()pour valider le format avant de tenter une conversion. - Classe
Locale - une classe qui permet de spécifier un ensemble de formats régionaux, notamment celui des nombres décimaux. Par défaut, le format dépend du système d’exploitation donc le programme se comportera différemment sur différents ordinateurs. Pour éviter des erreurs de conversion, on peut spécifier un
Localepour chaqueScanneren utilisant la méthodeuseLocale(). - Objet
System.in - un objet de type
InputStreamqui représente l’entrée standard du système d’exploitation, généralement la console. L’avantage est qu’il est toujours défini (ça fonctionne toujours). Le désavantage est que Windows gère les caractères Unicode différemment que le reste du monde, ce qui donne parfois des comportements inattendus et difficiles à résoudre. - Invite de réponse
- un message affiché à l’utilisateur pour lui indiquer ce qu’il doit saisir. C’est une bonne pratique de donner des invites de réponse claires et spécifiques pour éviter des erreurs de saisie. Des bonnes invites de réponse rendent toujours l’intéraction plus agréable pour l’utilisateur.
Liste des méthodes de Scanner les plus courantes :
next(): saisir le prochain mot (jusqu’à un espace, ignorant les espaces initiaux)nextInt(): saisir le prochain mot et le convertir enintnextDouble(): saisir le prochain mot et le convertir endoublehasNextInt(): vérifier si le prochain mot est uninthasNextDouble(): vérifier si le prochain mot est undoublenextLine(): saisir la prochaine ligne de texte (jusqu’à un retour à la ligne)… il y a des nuances avec cette méthode que nous explorerons en détail ci-dessous.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Savoir comment déclarer un Scanner pour la console et pour un String
- Savoir utiliser les méthodes d’instance d’un Scanner pour obtenir le type de réponse désiré.
- Expliquer l’importance d’une invite de réponse spécifique et claire avant l’instruction de saisie.
- Expliquer c’est quoi un
Localeet pourquoi il faut le spécifier si on veut saisir des valeurs décimales.
Critères de succès
- Je peux importer la classe
Scanner, déclarer un Scanner pour la console et utiliser ses méthodesnext,nextIntetnextDoublepour lire des données. - Je peux définir un
Localeapproprié pour le Scanner si j’ai besoin de saisir des valeurs décimales. - (enrichissement) Je peux valider les réponses fournies par l’utilisateur avec les méthodes
hasNextIntethasNextDoubleavant de tenter une conversion afin de réduire le nombre de plantages de mes programmes.
Structure générale d’un programme avec un Scanner
Les Scanner sont utilisés pour lire du texte à partir de différentes sources. Pour commencer, on utilisera un Scanner qui surveille System.in pour complémenter le PrintStream (System.out) qu’on utilise déjà pour afficher des messsages texte à la console. Bref, les Scanner vont nous permettre de lire des réponses de l’utilisateur à la console et d’avoir des programmes interactifs.
Si vous ne l’aviez pas deviné,
System.inetSystem.outsont les entrées et sorties standard de votre système d’exploitation, notamment la console.
La structure globale d’un programme qui utilise un Scanner est la suivante :
import java.util.*; // importer la définition de Scanner de java.util
void main() {
Scanner console = new Scanner(System.in); // déclarer un Scanner pour la console
// ... le reste du programme
}
Déclarer un Scanner
Le format de la déclaration d’un Scanner est le suivant :
Scanner nom = new Scanner(source);
où nom est le nom de la variable qui contiendra l’objet Scanner et source est la source de texte que le Scanner lira. Le nom est généralement un reflèt précis de la source.
Pour lire de la console
On utilise System.in, l’entrée standard, comme source.
Scanner console = new Scanner(System.in);
Pour lire un String
On utilise un String comme source.
String text = "Bonjour, le monde!";
Scanner textReader = new Scanner(text);
Fermer un Scanner
On ne ferme jamais le Scanner pour la console parce qu’on s’en sert généralement jusqu’à la fin du programme interactif. Ce Scanner sera fermé automatiquement en arrivant à la fin de la méthode main.
Par contre, c’est important de fermer les Scanner pour toutes les autres sources de texte, comme un fichier ou un String. On ferme un Scanner avec la méthode close() une fois qu’on a finit de le lire. Par exemple :
textReader.close();
Introduction aux méthodes de Scanner - extraire les données d’un String
Pour comprendre comment les méthodes de Scanner fonctionnent, on va les tester sur différents String. Les sections plus bas montrent le Scanner dans le contexte d’un programme interactif.
La méthode next() : lire le prochain mot
La méthode next() saisit le prochain mot - plus spécifiquement, le prochain ‘jeton’ - dans le texte. Un jeton est une séquence de caractères qui n’inclut pas d’espaces. Si la prochaine chose dans le texte commence par un ou plusieurs espaces, ces espaces seront ignorés en saisissant le jeton. La méthode next() retourne le jeton saisi.
String words = "\n \tBonjour le monde!";
Scanner wordsReader = new Scanner(words); // Scanner qui utilise le texte 'words' comme source
String word; // variable pour stocker le mot lu
word = wordsReader.next(); // ignore les espaces initiaux puis saisit tout jusqu'au prochain espace, soit "Bonjour"
System.out.println(word);
word = wordsReader.next(); // saisit "le"
System.out.println(word);
word = wordsReader.next(); // saisit "monde!"
System.out.println(word);
wordsReader.close();
Les méthodes nextInt() et nextDouble() : convertir le texte en nombre
Peut être que la ligne de texte suivante représente des informations sur une personne, comme son âge et sa moyenne scolaire. Connaissant le format du texte, on peut utiliser les méthodes appropriées pour lire les valeurs.
Les méthodes nextInt() et nextDouble() saisissent le prochain mot et tentent de le convertir en int ou double respectivement. Si le texte ne peut pas être converti en nombre, le programme plantera, alors il faut faire attention de :
- bien aviser l’utilisateur du format attendu dans un programme interactif
- bien observer les formats du texte dans des fichiers qu’on veut lire, comme un fichier qui contiendrait plusieurs lignes de données semblables à l’exemple suivant.
String info = "Marie 15 85.5";
Scanner infoReader = new Scanner(info);
String nom = infoReader.next(); // saisir le nom
int age = infoReader.nextInt(); // saisir le texte pour le nombre entier
double moyenne = infoReader.nextDouble(); // saisir le nombre décimal
infoReader.close();
System.out.printf("%s a %d ans et sa moyenne est %.1f\n", nom, age, moyenne);
Si le programme fonctionne correctement, il nous donnera cette sortie :
Marie a 15 ans et sa moyenne est 85.5
Dans notre contexte spécifique - travailler en français avec des machines configurées en français - il y a quand même un bon risque de plantage parce que le format pour le décimal est différent sur un système anglais (.) que sur un système français (,). À l’interne, Java utilise toujours le . comme décimal, mais il utilisera les formats du système dans ses Scanner pour interpréter les réponses de l’utilisateur à la console.
Donc c’est possible que Java présume que le format 85,5 est le bon et lance une erreur quand il voit plutôt 85.5. Ce n’est pas un bon système, mais il y a une façon de dire dans notre programme quel format on veut utiliser.
Spécifier le format des nombres décimaux
Quand on connaît le format des nombres décimaux dans le texte à lire, ou on dit à l’utilisateur quel format utiliser dans sa réponse interactive, on devrait spécifier ce format explicitement dans le code.
On le fait en utilisant la classe Locale (aussi dans java.util) et les valeurs qu’elle définit par défaut pour différents formats régionaux. Dans notre contexte, on utilise l’une au l’autre des options suivantes :
Locale.CANADA: pour utiliser le.comme séparateur décimalLocale.CANADA_FRENCH: pour utiliser la,comme séparateur décimal
Le code précédent devient alors :
String info = "Marie 15 85.5";
Scanner infoReader = new Scanner(info);
infoReader.useLocale(Locale.CANADA); // spécifie le format "."
String nom = infoReader.next();
int age = infoReader.nextInt();
double moyenne = infoReader.nextDouble();
infoReader.close();
System.out.printf("%s a %d ans et sa moyenne est %.1f\n", nom, age, moyenne);
Maintenant, le programme fonctionne correctement peu importe l’ordinateur utilisé pour le lancer.
Version interactive : lire la console
En interagissant à la console, c’est important de donner des invites de réponse claires et spécifiques à l’utilisateur afin qu’elle sache quoi taper et avec quel format, si nécessaire.
Voici un exemple en transformant le programme précédent en un programme interactif :
Scanner console = new Scanner(System.in); // source = entrée standard
console.useLocale(Locale.CANADA_FRENCH); // spécifie le format ","
System.out.print("Quel est votre prénom? "); // invite de réponse
String nom = console.next();
System.out.print("Quel est votre âge? "); // invite de réponse
int age = console.nextInt();
// invite de réponse qui reflète la déclaration du Locale plus haut dans le code
System.out.print("Quelle est votre moyenne? (utilisez le ',' comme décimal) ");
double moyenne = console.nextDouble();
System.out.printf("%s a %d ans et sa moyenne est %.1f\n", nom, age, moyenne);
// notez qu'on n'a pas fermé le Scanner pour la console
Enrichissement : valider la réponse avant de la saisir
Cette section est annotée comme “avancée” parce qu’elle incorpore des éléments de programmation que nous n’avons pas encore vus avec Java, notamment les opérations logiques et les boucles. Si vous ne comprenez pas tout de suite, ne vous inquiétez pas. Vous aurez l’occasion de revoir ces concepts plus tard dans le cours.
Si vous comprenez bien comment formuler une invite de réponse précise et comment assurer la cohérence entre votre invite et ce que vous avez écrit dans votre code, peut-être que vous ne serez pas satisfait de laisser une erreur de frappe par l’utilisateur faire planter votre programme. C’est là qu’on peut commencer à rendre le code plus tolérante aux erreurs en les gérant avant qu’elles ne causent des problèmes.
Pour valider une réponse avant de la saisir, on utilise les méthodes hasNextInt() et hasNextDouble() pour vérifier si le prochain mot est convertible en int ou double respectivement. Si la réponse est valide, on la saisit, la convertit et la conserve. Sinon, on doit vider le Scanner pour préparer la saisie suivante, alors on saisit la réponse comme texte sans la conserver. On peut également afficher un message d’erreur et inviter l’utilisateur à réessayer.

Scanner console = new Scanner(System.in);
System.out.print("Saisissez un nombre entier : ");
while (!console.hasNextInt()) {
console.next(); // vider le Scanner du jeton incorrect
System.out.println("Ce n'est pas un nombre entier valide.");
System.out.print("Saisissez un nombre entier : ");
}
int number = console.nextInt();
System.out.println("Vous avez saisi " + number);
L’opérateur
!est l’inverse logique (“not”). Il transformetrueenfalseetfalseentrue. Dans ce contexte,!console.hasNextInt()signifie “tant que le Scanner n’a pas un nombre entier valide comme prochain jeton”.
Exercices
📚 Tester la compréhension
aucun quiz de vérification des concepts ici encore
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices.
- Dupliquez tous les exemples dans le fichier
Scanning.java. - Prenez une capture d’écran de votre éditeur de code et du terminal pour les phases suivantes :
- l’exemple “Bonjour le monde!” -> nommez l’image
4-5-Scanner1.png. - l’exemple “Marie 15 85.5” avec l’ajustement pour inclure le bon Local -> nommez l’image
4-5-Scanner2.png.
- l’exemple “Bonjour le monde!” -> nommez l’image
- l’exemple interactif avec les invites de réponse; répondez comme vous le voulez -> nommez l’image
4-5-Scanner3.png. - l’exemple avec la validation de la réponse; donnez au moins une mauvaise réponse avant de donner une réponse valide -> nommez l’image
4-5-Scanner4.png.
Accueil > Programmer avec Java > Les bases de Java >
📚 Opérations mathématiques et concaténation
Survol et attentes
Les ordinateurs sont des calculatrices très puissantes. Dans cette leçon on apprend les opérations mathématiques les plus communes et une opération sur le texte.
Définitions
- Opération
- une action qui implique deux données pour produire un résultat. Par exemple, l’addition est une opération qui combine deux nombres pour donner la somme de ces nombres.
- Opérateur
- un symbole qui représente une opération sur des données. Par exemple,
-est l’opérateur de soustraction de nombres et=est l’opérateur d’assignation de valeurs à des variables. - Opérande
- les données de chaque côté d’un opérateur. Par exemple, dans
3 + 4,3et4sont les opérandes. Les opérandes peuvent être des valeurs littérales (comme3ou4) ou une expression qui s’évalue au type approprié. Des exemples d’expressions simples sont : une variable, un appel de méthode ou une autre opération. - Ordre des opérations
- les règles qui déterminent l’ordre dans lequel les opérations sont effectuées. Java utilisent la même ordre que les mathématiques : d’abord les parenthèses, ensuite la multiplication et la division, et finalement l’addition et la soustraction. Pour les opérations de même niveau, les opérations s’évaluent de gauche vers la droite. S’il y a un appel de méthode, on remplace l’appel avec sa valeur de retour avant de poursuivre les opérations. S’il y a une référence de variable, on remplace la variable avec sa valeur avant de poursuivre les opérations.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Comprendre et évaluer des opérations mathématiques et de concaténation.
- Comprendre le cas spécial de la division avec des
intet, de manière connexe, l’utilité de l’opérateur%.
Critères de succès
- Écrire des expressions incluant des opérations mathématiques et de concaténation.
jshell
C’est pratique d’explorer ces opérations dans une session interactive qui donne le résultat instruction par instruction (au lieu d’écrire un programme complet et l’exécuter). Pour le faire, simplement lancer la commande jshell au terminal. Ensuite tapez vos instructions une à la fois (le ; est optionnel dans jshell). Pour quitter, tapez la commande /exit ou fermez le terminal.
Opérations mathématiques
Voici la liste des opérateurs mathématiques qui fonctionnent sur deux valeurs numériques, soit de type int ou double :
+addition-soustraction/division*multiplication%modulo (restant)
Division entière
La division entre deux entiers (int) peut seulement donner un entier comme résultat parce qu’il n’y a pas de partie décimale pour un int.
Exemples à évaluer dans jshell :
7 / 2; // donne 3 (pas 3.5)
7 / 3; // donne 2 (pas 2.333...)
1 / 2; // donne 0 (pas 0.5)
Modulo (restant)
Le modulo (%) donne le reste de la division.
1 % 3; // restants de la division par 3
2 % 3;
3 % 3;
4 % 3;
7 % 2; // restant de la division par 2
113 % 10; // restant de la division par 10
C’est utile pour vérifier si un nombre est divisible par un autre utilisant la condition “egale 0?”, soit == 0 en Java. Par exemple :
if ((a % 17) == 0) {
// a est divisible par 17 parce qu'il n'y a pas de restant
// fait quelque chose ici avec a
}
Les prochaines leçons présententent les opérations logiques (comme
==) et les structures de contrôle (if,while,for, etc.) qui permettent d’utiliser des conditions comme celle-ci.
Incrémentation et décrémentation
Ces opérateurs simplifient des assignations où on modifie la valeur d’une variable de type int ou double par une quantité fixe.
| Opérateur | Description | Exemple | Équivalent |
|---|---|---|---|
++ | incrémenter (augmenter la valeur) par 1 | a++ | a = a + 1 |
+= | incrémenter par une valeur spécifique | a += 3 | a = a + 3 |
-- | décrémenter (diminuer la valeur) par 1 | a-- | a = a - 1 |
-= | décrémenter par une valeur spécifique | a -= 3 | a = a - 3 |
int a = 5;
a++; // a vaut maintenant 6
a--; // a vaut maintenant 5
a += 3; // a vaut maintenant 8
a -= 2; // a vaut maintenant 6
Concaténation de texte
L’opérateur + est surchargé en Java; il a différentes définitions selon le type des opérandes.
- Si les deux opérandes sont numériques,
+fait une addition - Si au moins une des opérandes est du texte,
+fait une concaténation. C’est-à-dire qu’il colle les deux représentations texte des valeurs pour donner un seul texte combiné.
Exemples :
"Bon" + "jour"donne"Bonjour""Trois = " + 3donne"Trois = 3"le int
3est converti en String"3"avant d’être collé au texte"4" + 3donne"43"Parce que
"4"est du texte, l’opérateur+colle les deux représentations texte des valeurs au lieu de faire une addition.
Classe Math
N’oubliez pas que la classe Math contient plusieurs méthodes pour faire des opérations mathématiques plus complexes. Par exemple : Math.pow(), Math.sqrt(), Math.abs(), Math.sin(), etc.
Exercices
📚 Tester la compréhension
aucun quiz de vérification des concepts ici encore
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices.
- Créer un fichier
Calculs.javadans votre répertoire de travail. Assurez-vous d’y ajouter la structure de base (méthodemain). - Déclarez et initialisez deux
intet faire les 5 opérations mathématiques des bases avec ces deux variables. Affichez le résultat de chaque opération, p. ex.System.out.println("a + b = " + (a + b)); - Ajouter un commentaire explicatif (
// ...ou/* ... */) pour un des calculs explicant ce qui est une concaténation et ce qui est une opération mathématique dans l’expression que vous affichez. - Déclarez et initialisez deux
doubleet faire les deux divisions possibles entre ces deux variables (a/b et b/a). Affichez le résultat de chaque opération. - Testez votre programme en le lançant au terminal. Corrigez les erreurs s’il y en a.
- Faites un commit et un push de votre travail dans GitHub.
Accueil > Programmer avec Java > Les bases de Java >
📚 Diagrammes de flux
Survol et attentes
Définitions
- Flux
- Synonyme de séquence dans le sens d’un écoulement des étapes
- Diagramme de flux
- Diagramme représentant la séquence des étapes d’un algorithme. Ces diagrammes utilisent des symboles standards, des étiquettes et des flèches pour représenter clairement le déroulement d’un algorithme, comme ceux implémentés dans les programmes Java.
- Début / Fin
- Un ovale
- Traitement / Opération mathématique
- Un rectangle
- Entrée / Sortie
- Un parallélogramme
- Flèche
- Indique que l’étape à la queue de la flèche est suivie par l’étape à la tête de la flèche.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Identifier la forme des symboles standards pour le début/fin d’un algorithme, pour les entrées et les sorties et pour les traitements de données.
- Tracer le diagramme dans l’ordre d’exécution des étapes.
Critères de succès
- Je peux lire et produire un diagramme de flux pour des algorithmes de base (traitement, entrée/sortie)
- Je peux évaluer la sortie d’un algorithme de base en traçant l’exécution illustrée.
Formes
| Début / fin | Traitement | Entrée / Sortie |
|---|---|---|
 |  |  |
Étiquettes
Dans chaque forme il y a du texte. À part les symboles pour le début et la fin, les étiquettes commencent par un verbe suivi par une description, p. ex.“ Assigner 3 à num“.
Traitements
- Assigner une valeur à une variable
- Modifier une variable
- Faire un calcul
- Combiner du texte (concaténation)
Entrées / sorties
Les entrées représentent de l’information qui n’est pas définie dans l’algorithme mais à laquelle on peut accéder :
- Réponses de l’utilisateur
- Contenu de fichiers
- Lecture d’instruments
Les sorties représentent de l’information qui est exportée de l’algorithme :
- Valeurs affichées à l’écran
- Valeurs envoyées à une imprimante
- Valeurs enregistrées dans un fichier
Exemple “Bonjour le monde”

Cet exemple utilise simplement une sortie entre les ovales de début et de fin.
Le code équivalent est :
void main() {
System.out.println("Bonjour, le monde!");
}
Exemple avec traitement
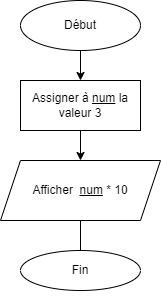
Dans cet exemple il y a deux traitements - un mis en évidence et un dans l’instruction de sortie.
Le code équivalent est :
void main() {
int num = 3;
System.out.println(num * 10);
}
Ce programme afficherait la valeur 30 parce que num est définie comme 3 et on affiche num * 10 soit 3 * 10.
Une version plus réaliste de ce programme serait le suivant, avec saisie de la valeur de l’utilisateur :
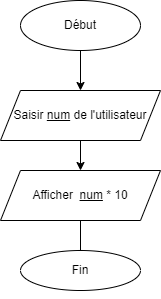
Le code équivalent est :
import java.util.*;
void main() {
Scanner in = new Scanner(System.in);
// saisir la valeur, incluant l'invite de commande
System.out.print("Entrez un nombre entier > ");
int num = in.nextInt();
// afficher le résultat
System.out.println(num * 10);
}
Produire ces diagrammes
On peut produire ces diagrammes avec toute sorte de logiciels de dessin, comme :
- Google Dessin (seul ou intégré dans Docs ou Slides)
- Lucidchart
Draw.io(drawio.com,app.diagrams.net)- etc.
Extension VS Code
Il y a une extension VS Code pour Draw.io qui nous permet de créer des diagrammes dans l’éditeur, alors c’est souvent le plus efficace dans ce cours. C’est Draw.io Integration par Henning Deitrichs (~2 million de téléchargements). Avec cette extension (ou son équivalent sur le web) :
- C’est bon de choisir le format
.drawio.pngqui produit une image affichable directement dans des documents mais également éditable dans le logiciel. - Toutes les formes utilisées pour le diagramme de flux se trouvent dans la section
Général: ovale, rectangle, parallélogramme. - On trace des flèches directement de la première forme à la deuxième. On a même le choix de commencer une flèche à partir d’une forme et choisir parmi quelques formes pour la destination sans passer par le menu.
- On clique sur un objet pour y ajouter du texte en tapant.
Séquence
La structure représentée par ces diagrammes est la structure fondamentale de tout programme qui s’exécute sur un ordinateur classique : une simple séquence. Dans cette structure, toutes les instructions se succèdent dans l’ordre du début jusqu’à la fin.
Exercices
📚 Tester la compréhension
aucun quiz de vérification des concepts ici encore
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices.
- Créez un nouveau dossier
diagrammesdans le dépôt de pratique pour stocker ces diagrammes. - Créer un nouveau fichier nommé
collation.drawio.png. Il s’ouvrira avec l’extensionDraw.iosi vous l’avez déjà ajoutée. Faire un diagramme de flux pour la séquence de préparation d’une collation, comme un sandwich ou du thé. - Reprendre 2 vos programmes de cette unité qui incorporent des traitements et/ou des entreés et des sorties. Produire leurs diagrammes de flux. Nommez les fichiers
[NomDuProgramme].drawio.png. - Faire un diagramme de flux pour la réalisation d’un projet de recherche dans
recherche.drawio.png. Utilisez les grandes étapes du projet comme traitements.
Accueil > Programmer avec Java >
🛠️ Décomposition des problèmes
Survol et attentes
Même sans connaissances en programmation, vous êtes capable de décomposer des grands problèmes en plus petits problèmes. C’est une compétence essentielle pour la programmation et pour la résolution de problèmes en général. En particulier, à l’ère de l’intelligence artificielle, votre capacité à décrire les morceaux individuels d’un problème complexe vous permettra de tirer le plus grand profit des outils de rédaction de code, surtout si vous commencez par la rédaction des méthodes au bas de chaque chaîne d’appels.
Définitions
- Modulaire
- Un programme est dit modulaire quand il est divisé en parties indépendantes qui peuvent être réutilisées. Les méthodes sont les “modules” les plus simples dans un programme Java.
- Décomposition / Approche descendante
- Stratégie de résolution de problèmes qui consiste à diviser un problème complexe en plus petits problèmes plus faciles à résoudre. L’approche de partir du problème global et de le diviser en plus petits problèmes est appelée approche descendante. En programmation, on peut utiliser des commentaires de ligne pour créer des sections dans la méthode
mainpour chaque partie de la solution mais on utilise généralement une méthode séparée pour chacun de ces sous-problèmes. - Déclarer
- Définir de façon plus ou moins formelle les éléments (étapes/méthodes) à inclure dans un plan pour la réalisation d’un projet, la structure d’un programme, etc. Une déclaration informelle est souvent juste un titre ou une courte description. Quand le plan est basé sur la décomposition, les éléments sont les différents “modules” (étapes / méthodes) de la solution complète.
- Diagramme de dépendances
- Diagramme indiquant la relation entre les étapes/modules/méthodes de la solution à un problème . Les méthodes sont des blocs nommés. Si une méthode a une flèche sortante vers une autre méthode, elle dépend de cette autre méthode. Si une méthode n’a aucune flèche sortante, elle est indépendante.
- Chaîne d’appels
- Une suite de flèches dans le diagramme de dépendances, du début (souvent la méthode
main) jusqu’à la fin (un bloc qui n’a pas de flèche sortante). - Refactoriser
- En programmation, ce terme veut dire restructurer le code pour le rendre plus lisible, plus efficace ou plus facile à maintenir. Séparer un morceau de code plus long et complexe en méthodes distinctes (le décomposer) après l’avoir écrit est un exemple de refactorisation qui rend le code plus facile à lire, à tester, à réutiliser et à modifier.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Décrire un programme modulaire.
- Décire la décomposition d’un problème avec une approche descendante.
- Représenter les étapes d’un problème décomposé avec un diagramme de dépendances.
- Identifier les dépendances entre les modules selon les chaînes d’appels.
Critères de succès
- Je suis capable d’utiliser une approche descendante pour planifier les étapes de mon projet.
- Je peux créer un diagramme de dépendances pour un programme décomposé.
- Je peux refactoriser un programme en modules appropriés pour le rendre plus facile à lire, tester et maintenir.
Un programme modulaire
Au début d’une tâche de programmation, on peut penser à notre solution comme un seul programme :

Par contre, on a souvent à faire au moins les trois étapes suivantes dans chaque programme qui interagit avec un utilisateur :
Si on connaît les détails de la tâche, on peut probablement diviser l’étape “Actions” encore selon les différentes tâches à réaliser :
Ce qu’on vient de faire est une décomposition du problème selon une approche descendante : on a pris un problème complexe et on l’a divisé en plus petits problèmes. Chaque petit problème est plus facile à résoudre que le problème global.
En programmation, on peut utiliser des méthodes pour résoudre chaque petit problème.
Un projet modulaire
On peut appliquer la même approche à la planification d’un projet dans n’importe quelle domaine.
Par exemple, un projet de recherche qui commence comme ceci :

Peut être décomposé en étapes comme ceci :
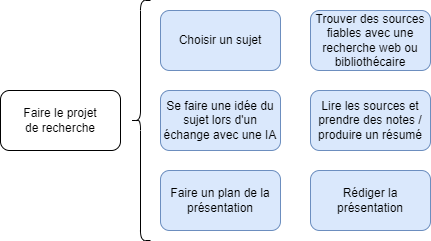
Voyant les étapes exposées comme ça, on peut mieux prévoir le temps nécessaire ou mieux s’organiser en équipe pour répartir les tâches.
Diagramme de dépendances
Certaines étapes ou modules d’un projet ne peuvent pas se faire sans que d’autres ne soient complétées. Un diagramme de dépendances illustre ces relations entre les modules.
On a déjà vu un diagramme de flux (qui montre la séquence des étapes) dans une leçon précédente. Un diagramme de dépendances est différent sur plusieurs points :
- Il ne montre pas ce qui se passe dans les détails mais identifie seulement les “modules” ou les “étapes” du projet.
- Il ne montre pas l’ordre d’exécution mais plutôt quelle étape dépend de quelle autre étape.
Le projet de recherche
Ici on compare les deux types de diagrammes pour le projet de recherche :
Diagramme de flux :

Diagramme de dépendances :

Avez-vous remarqué que la direction des flèches est inversée entre les deux diagrammes? C’est parce que le diagramme de dépendances commence avec le projet complet et regarde ce qui est nécessaire pour le rendre… réponse : que le projet soit rédigé. Et pour rédiger le projet, on a besoin de quoi?… réponse : les notes de recherche. Et pour faire les notes, on a besoin de quoi?… réponse : les sources d’information, etc. Ici les flèches indiquent les dépendances. Si on a une flèche de A vers B, ça veut dire que A dépend de B.
Dans le diagramme de flux, c’est l’opposé : on commence avec la première étape à réaliser. Ensuite, on regarde ce qui doit se passer après. Et après, et après, jusqu’à la fin du projet. Si on a une flèche de A vers B, ça veut dire que B est l’étape qui suit A.
C’est naturel que les flèches soient inversées entre les deux diagrammes. Si A dépend de B, alors A doit attendre que B soit fait. Cela nous donne :
- flèche de dépendance de A vers B
- flèche de séquence de B vers A
Le programme modulaire
Maintenant on fait le même exercice pour le programme modulaire :
Diagramme de flux :
Les modules se suivent dans un ordre logique.
Diagramme de dépendances :
Le programme dépend des modules Accueil, Actions et Au revoir qui sont indépendants entre eux (aucune flèche). Il y a aussi Actions qui dépend des modules Tâche 1, Tâche 2, … qui sont aussi montrés comme indépendants entre eux.
Ici la relation entre les deux types de diagrammes n’est pas aussi claire. Entre autres, on ne peut pas regarder le diagramme de flux et savoir, avec certitude, si une étape dépend de l’étape précédante ou non. De l’autre côté, il n’y a aucun lien direct entre les “modules” Accueil, Actions et Au revoir dans le diagramme de dépendances alors rien ne suggère une séquence sauf notre expérience qu’un accueil vient avant un au revoir.
En général, on produit chaque type de diagramme indépendamment en appliquant les concepts de chacun :
- le diagramme de flux montre toujours la séquence d’exécution des étapes;
- le diagramme de dépendances montre les dépendances entre les différents modules.
Chaînes d’appels
Dans les diagrammes de dépendances, les modules sont liées dans des chaînes de dépendance. Les modules en programmation sont souvent des méthodes. Dans ce contexte on parle de chaînes d’appels, parce qu’une méthode doit appeller les autres méthodes qu’elle a besoin d’utiliser.
Si une méthode à plusieurs dépendances, il y a des branches qui se forment dans le diagramme, créant autant de chaînes d’appels que de branches. Notre exemple de programme modulaire a donc ces cinq chaînes d’appels car la méthode Actions dépend de trois méthodes, triplant le nombre de chaînes passant par elle :
Au début d’une chaîne d’appels (le bloc avec aucune flèche entrante), on a la méthode dépendante d’une autre. À la fin d’une chaîne d’appels, on a une méthode qui n’a pas de dépendances (aucune flèche sortante), qui est indépendante.
Si on veut profiter pleinement de la décomposition (plusieurs problèmes plus simples au lieu d’un grand problème), on ne peut pas commencer par écrire les instructions pour les méthodes dépendantes car il faudra aussi immédiatement écrire les instructions pour toutes les autres méthodes plus bas dans la chaîne d’appels (la première méthode dépend d’eux)… on n’a pas vraiment simplifié notre tâche! Par contre, si on commence avec une des méthodes indépendantes, on peut écrire le code juste pour cette méthode et la tester. On a juste un petit problème à résoudre. Ensuite, on peut soit choisir une autre méthode indépendante à faire ou bien la prochaine méthode plus haut dans la chaîne d’appels. Dans chaque cas, on reste avec juste un petit problème à résoudre dans l’immédiat. Mais peu à peu, tous les modules du projet se réalisent.
Refactoriser - quand on a déjà tout écrit
Parfois on n’a pas prévu découper notre programme en plus petites méthodes, mais la taille du programme ou sa complexité ou le besoin de réutiliser plusieurs fois le même code nous pousse à le faire. Réorganiser le code sans changer son comportement s’appelle refactoriser. Il n’y a pas de planification, juste un besoin pressant pour la décomposition, pour la création de modules.
La plupart du temps, surtout en commençant à programmer, c’est dur de savoir quand quelque chose sera trop complexe avant de l’avoir écrit, alors la refactorisation est souvent ce qui motive les premières expériences avec le code modulaire.
Exercices
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices
Assurez-vous d’avoir installé l’extension “Draw.io Integration” pour VS Code pour éditer les fichiers .drawio.
- Pour la grande tâche de “préparer un repas” avec les modules “préparer la table”, “cuisiner”, “servir le mets principal”, “servir le dessert”, “remplir les breuvages” et “nettoyer”, dans votre dossier
diagrammes:- Créez un diagramme de dépendances pour ces modules nommé
modules_repas-dependancy.drawio - Créez un diagramme de flux pour ces modules nommé
modules_repas-flux.drawio.
- Créez un diagramme de dépendances pour ces modules nommé
Accueil > Programmer avec Java >
Séquence d’exécution avec le code modulaire
Survol et attentes
Définitions
- Diagramme de séquence d’exécution
- Un diagramme qui identifie les numéros de lignes des instructions selon l’ordre réelle d’exécution (et non l’ordre de déclaration). Les appels de méthode sont indiqués par une flèche de la ligne de l’appel vers la ligne de la signature de la méthode appelée. Le retour (fin) de la méthode est indiqué par une flèche de la ligne de la dernière instruction de la méthode vers la ligne de l’appel.
- Appel de procédure
- Dans un diagramme de flux : un rectangle avec des lignes de côté doublées qui contient le nom de la méthode. Cette forme représente l’appel de la méthode.
- Définition de procédure
- Dans un diagramme de flux : commence par un ovale qui contient le nom de la méthode (au lieu de “début”), continue avec les instructions de la méthode et finit par un autre ovale qui contient “fin de [nom de la méthode]” ou “retour”.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Suivre l’exécution d’un programme qui contient des appels de méthodes que nous avons définies et le documenter dans un diagramme de séquence d’exécution.
- Identifier des appels et des définitions de méthodes dans un diagramme de flux, un diagramme de séquence d’appels et un programme Java.
- Produire un diagramme de flux pour un algorithme simple qui contient des procédures.
Critères de succès
- Je peux suivre l’exécution d’un programme qui contient des méthodes et le documenter avec un diagramme de séquence d’exécution.
- Je peux lire des diagrammes de flux qui contiennent des procédures.
Le code modulaire
Commençons avec un exemple simple1 d’un programme décomposé, d’un programme modulaire.
Fichier :
MainClass.java
void main() {
welcome();
doStuff();
bye();
}
void welcome() {
System.out.println("Bienvenue dans mon programme!");
}
void doStuff() {
System.out.println("On fait des choses utiles ici...");
}
void bye() {
System.out.println("Bye!");
}
Dans ce programme, comme dans tout programme Java, le programme principal est dans la méthode main. Dans ce cas-ci, le programme principal est très simple. Il appelle trois autres méthodes, welcome, doStuff et bye. On comprend très bien la structure globale du programme. Par la suite, tous les détails du programme se trouvent dans les méthodes individuelles appelées par main. Même si ces détails devenaient plus complexes, la méthode main resterait simple et facile à lire.
Le diagramme de flux
Le même programme est représenté ci-dessous dans un diagramme de flux.
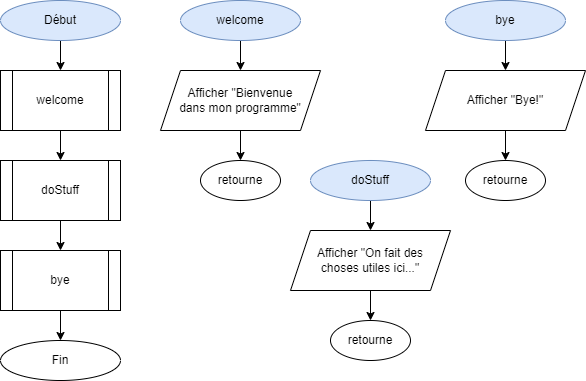
Notez qu’il y a plusieurs séquences d’instructions distinctes dans le diagramme de flux : une pour chaque méthode.
L’algorithme commence toujours avec l’ovale “Début” et se termine avec l’ovale “Fin”. Par contre, on a maintenant un nouveau type de bloc dans le diagramme - un appel de procédure :

Ce bloc envoie l’exécution du programme à la séquence d’instructions qui commence par le nom inscrit dans le bloc. Quand la séquence d’instructions de la méthode appelée est terminée, l’exécution est retournée au point de l’appel et continue le long des flèches.
On voit aussi que les ovales de début et de fin sont légèrement différents pour les procédures :
- le mot “Début” est remplacé par le nom de la méthode
- le mot “Fin” est remplacé par “Fin de [nom de la méthode]” ou “Retourne”
Tracer la séquence d’exécution programme
Chaque appel d’une méthode envoie l’exécution du programme à la signature de la méthode appelée et à travers ses instructions. Quand la méthode appelée se termine, l’exécution est retournée au point de l’appel pour continuer avec le reste du programme.
On peut le voir et le représenter comme suit.
À partir du code
On peut utiliser l’outil Python Tutor pour visualiser l’exécution du programme étape par étape afin de mieux comprendre la mécanique d’appel et de retour de méthodes.
Notez que le code est logiquement identique à celui ci-dessus mais que la version de Java disponible (Java 8) ne permet pas les simplifications de la syntaxe qu’on a avec Java 22. On a donc la déclaration explicite d’une classe et les mots clés
staticetpublicpour les méthodes.
Sans un tel outil, on peut tracer manuellement l’éxecution avec un diagramme de séquence d’exécution, soit :
- une liste des numéros de ligne exécutés dans l’ordre d’exécution;
- on indente vers la droite avec une flèche pour indiquer un appel de méthode et
- on revient à gauche avec une autre flèche pour indiquer le retour de la méthode.
Pour notre version de MainClass.java (avec la syntaxe simplifiée), le diagramme de séquence d’exécution serait :
1
2 -> 7
8
2 <- 9
3 -> 11
12
3 <- 13
4 -> 15
16
4 <- 17
5
Les lignes suivantes représentent des appels de méthodes :
Appel de welcome :
2 -> 7
Appel de doStuff :
3 -> 11
Appel de bye :
4 -> 15
Les lignes suivantes représentent les retours de méthodes :
Retour de welcome :
2 <- 9
Retour de doStuff :
3 <- 13
Retour de bye :
4 <- 17
Notez que l’appel et le retour reviennent à la même ligne dans le diagramme de séquence, soit 2 appel welcome et welcome retourne à 2, etc.
Dans Python Tutor, on sautait les lignes de signature durant l’appel et la ligne appelante lors du retour. C’est parce que nos procédures n’ont pas de paramètres et ne retournent pas de valeur en se terminant alors il n’y avait rien à visualiser pour ces lignes. On voit les paramètres et les valeurs de retour dans une prochaine leçon.
Notez aussi que durant l’exécution des méthodes appelées, les numéros de ligne sont identées au même niveau que la signature de la méthode afin de distinguer ces instructions des instructions de la méthode appelante.
À partir du diagramme de flux
On peut aussi tracer la séquence d’exécution à partir du diagramme de flux. On y ajoute manuellement plus de flèches!
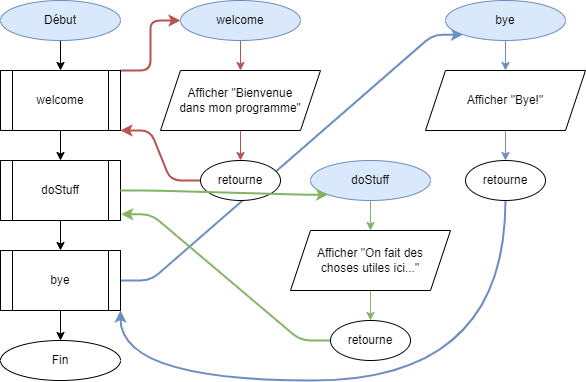
Encore une fois, comme avec le diagramme de séquence d’exécution, l’appel et le retour se font à partir du même bloc dans le diagramme de flux.
Exercices
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices
- Pour le programme ci-dessous dans un fichier nommé
ModularSequence.java:- Créez le diagramme de séquence d’exécution dans un commentaire de bloc à la fin du programme.
- Ajoutez un astérisque (
*) à la fin de chaque ligne du diagramme de séquence d’exécution où il y a une instruction d’affichage. - Dans un deuxième commentaire de bloc à la fin du programme, documentez ce que le programme affiche à la console durant l’exécution. Comparez cette sortie avec le diagramme de séquence d’exécution et l’ordre des lignes avec des astérisques. Est-ce que c’est cohérent? Si non, revoyez votre diagramme de séquence d’exécution pour trouver où vous avez fait une erreur.
- Créez le diagramme de flux dans le dossier
diagrammesdans un fichier nommémodular-flux.drawio. - Créez le diagramme de dépendances (voir la leçon précédente) dans un fichier nommé
modular-dependancy.drawio. Utilisezmaincomme le bloc de départ.
ModularSequence.java
void main() {
System.out.println("Bienvenue!");
a();
b();
}
void a() {
c();
System.out.println("bleu");
}
void b() {
System.out.println("blanc");
a();
}
void c() {
System.out.println("rouge");
}
-
Exemple applicant les classes implicites et le main d’instance de JEP 463 (pleinement intégré aux outils Java22+) ↩
Accueil > Programmer avec Java >
Méthodes donnant une valeur de retour
Survol et attentes
Définitions
- Implémenter
- En programmation, ce terme veut dire “écrire le code selon le plan pour le programme”. Avec les programmes modulaire, l’implémentation se fait une méthode à la fois afin de tester que chaque morceau fonctionne correctement avant de passer au suivant.
- Déclaration de méthode
- signature spécifiant le type de retour, le nom, les paramètres et le bloc de code d’une fonction.
- Corps de méthode
- tout entre les accolades
{}qui suivent directement la signatures de la méthode. Les méthodes implémentées doivent toujours avoir un corps; la signature n’est jamais terminée avec un;. - Appel de méthode
- instruction qui utilise le nom de la méthode suivi par des parenthèses. Si la méthode retourne une valeur, on l’assigne souvent à une variable ou on l’utilise directement dans le reste de l’instruction, comme un calcul ou un affichage. Si la méthode reçoit aussi de l’information, on passe ces valeurs entre les parenthèses.
- Valeur de retour
- valeur produit par une méthode et renvoyée au programme. L’appel de méthode représente essentiellement cette valeur dans l’expression où l’appel est insérée, p. ex. un calcul ou une assignation. Dans Java, le type de retour est spécifié dans la déclaration de la méthode devant le nom de la méthode. Les méthodes qui ne retournent rien ont le type de retour
void. Les autres ont un type de retour comme les variables et incluent une instructionreturn [valeur];à la fin du bloc de code de la méthode.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Distinguer les méthodes qui retournent par défaut de celles qui retournent explicitement.
- Décrire ce qui se passe quand une méthode retourne, tant pour la méthode que pour le programme appelant, notamment quand la méthode retourne une valeur.
- Lire et tracer un diagramme de séquence d’exécution pour un programme qui inclut des méthodes avec valeur de retour.
Critères de succès
- Je peux implémenter des méthodes avec valeur de retour dans mes programmes et reconnaître celles que j’utilise déjà.
Exemples connus de méthodes avec valeur de retour
Vous connaissez déjà quelques méthodes avec valeur de retour :
- celles pour la classe
Scanner- commenextInt(),nextDouble(),nextLine() - celles pour la classe
Math- commeMath.pow()etMath.sqrt() - celles pour la classe
String- commelength()ettoUpperCase()
Qu'est-ce que ces exemples ont tous en commun?
Réponse
Il y a quelques indices que ces méthodes retournent une valeur au programme appelant :
- On assigne souvent une variable du type approprié pour recevoir la valeur retournée, p. ex.
String name = scanner.nextLine(); - Les info-bulles de notre éditeur nous montrent le type de retour de la méthode dans l’en-tête et décrivent la nature de la valeur retournée, p. ex. :

Exemples connus de méthodes sans valeur de retour
Les méthodes sans valeur de retour ont le type de retour void. Elles sont souvent utilisées pour des actions qui modifient directement l’état de la mémoire du programme ou qui font des sorties (comme afficher à l’écran ou enregistrer dans un fichier).
Ceux que vous connaissez le mieux sont les méthodes :
main- qui ne retourne rien au système d’exploitation : sa fin est la fin du programmeprintln,printetprintfdeSystem.out- qui affichent des messages à la console
Il y a quelques indices que ces méthodes ne retournent pas de valeur :
- On ne déclare aucune variable pour recevoir la valeur retourné (car il n’y en a pas)
- Le mot-clé
voidprécède immédiatment le nom de la méthode dans la déclaration, p. ex.void main()ou sa version plus standardpublic static void main(String[] args)
Écrire nos propres méthodes avec valeur de retour
Avec la décomposition, on a vu que c’est souvent utile de diviser un programme complet et plus petits sous-problèmes. Chacun serait une (ou plusieurs) méthode(s). Il faut alors savoir comment les déclarer dans nos programmes.
Signature de méthode
L’exemple de la leçon précédente, dans MainClass.java, montre comment déclarer les méthodes sans valeur de retour - comme void main() et void welcome(). C’est la même chose pour les méthodes avec valeur de retour, sauf qu’on remplace void par le type de retour désiré. Le format général est alors :
[type de retour] [nom de la méthode]() {
// bloc de code
}
Corps de méthode
Les corps de méthode, les blocs de code entre les accolades {}, seront différents selon si le type est void (pas de valeur de retour) ou non.
Sans valeur de retour
Type : void
void [nom de la méthode]() {
// instructions
} // retour implicite à l'accolade fermante
ou
void [nom de la méthode]() {
// autres instructions
return; // retour explicite sans valeur de retour
}
Avec valeur de retour
Type : int, double, String, etc.
[type de retour] [nom de la méthode]() {
// autres instructions
return [valeur]; // retour explicite où valeur est du type de retour
}
Deux exemples
Le programme ci-dessous montre un exemple très simple (et banal) de deux méthodes avec valeur de retour.
Fichier :
BasicReturn.java
String getName() {
return "Dave3000";
}
int getMeaningOfLife() {
return 42;
}
void main() {
String name = getName();
System.out.println("Bonjour, je m'appelle " + name);
System.out.println("J'ai aussi un chiffre très important pour vous : " + getMeaningOfLife());
}
Remarquez qu’on a placé la méthode main à la fin du fichier. C’est possible de le faire, et souvent très naturel de le faire si vous avez planifié les différents modules de votre programme avant de commencer. Les développeurs tendent à mettre la méthode main soit au début, soit à la fin du fichier pour faciliter la lecture du programme.
String getName()
- Type de retour :
String: retourne"Dave3000", unStringlittéral - Quand on l’appelle dans
main(ligne 10), on assigne la valeur retournée à la variablename, qu’on affiche ensuite à la ligne 11.
int getMeaningOfLife()
- Type de retour :
int: retourne42, unintlittéral - Quand on l’appelle dans
main(ligne 12), on affiche directement la valeur retournée sur cette même ligne. Notez que le nom de la méthode est tout de même suivi de parenthèses.
void main()
- Type de retour :
void: ne retourne rien - retourne implicitement à la fin de la méthode (sans instruction
return)
Diagramme de flux pour une méthode avec valeur de retour
Ce qu’on a déjà appris sur les diagrammes de flux pour les méthodes s’applique, mais il faut maintenant :
- Indiquer dans la définition de la méthode ce qui sera retourné
- Utiliser dans l’algorithme principal ce qui est retourné suite à l’appel de la méthode
Voici le diagramme de flux pour le programme BasicReturn.java :
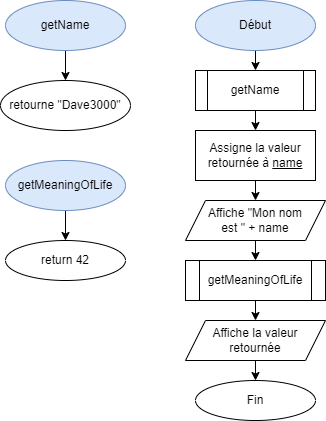
Le diagramme de flux nous aide à mieux voir la mécanique appel-retour. On voit quelque chose là qui n’est pas aussi apparent dans le code. Dans l’algorithme principal du diagramme de flux nous devons utiliser au moins deux instructions, soit :
- une pour l’appel de la méthode et
- une pour utiliser la valeur de retour.
Dans le code, tout ça se fait normalement sur la même ligne de code, en combinant plusieurs expressions (p. ex. : assignation et appel, affichage et appel) dans une seule instruction.
Notez aussi que l’appel précède toujours l’autre instruction dans le diagramme (comme durant l’exécution réelle du programme). Dans le code, ce n’est pas évident que ce soit le cas, car l’appel se trouve plus à gauche que l’autre instruction.
Structure générale pour l’utilisation d’une méthode avec valeur de retour


Tracer la séquence d’exécution
Peu importe si main se trouve au début ou à la fin du fichier, on commence toujours le programme à main. À part le déplacement de main, il n’y a rien de nouveau dans le diagramme de séquence d’exécution, sauf que :
- le fait de retourner à la même ligne que l’appel devrait faire plus de sens;
- on n’arrive pas à la ligne de l’accolade fermante s’il y a une instruction
return; l’accolade fermante est unreturnimplicite dans les autres cas.
9
10 -> 1
10 <- 2
11
12 -> 5
12 <- 6
13
Pour getName
10 -> 1
est l’appel
10 <- 2
est l’assignation de la valeur de retour à name
Pour getMeaningOfLife
12 -> 5
est l’appel
12 <- 6
est l’affichage de la valeur de retour
Diagramme de dépendances
Encore, pour ce diagramme on doit commencer à main et regarder quelles méthodes il appelle.
La nouveauté est qu’avec des valeurs de retour, on inclut le type de retour dans le bloc de la méthode. Plusieurs styles sont possibles, mais deux qui sont cohérents avec ce que nous voyons sont :
[nom de la méthode]() -> [type de retour]… la flèche est semblable à ce qu’on utilise dans le diagramme de séquence d’exécution[nom de la méthode]() : [type de retour]… ce format ressemble à ce que vous voyez si vous ouvrez la panneauStructure(Outlineen anglais) de VS Code.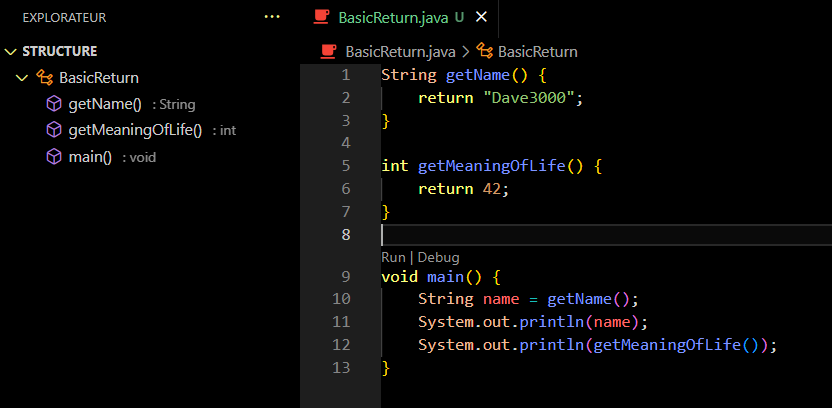
Voici donc une version possible de ce diagramme. L’ajout des valeurs de retour nous indique que main dépend des valeurs String et int produites par les deux méthodes qu’il appelle.
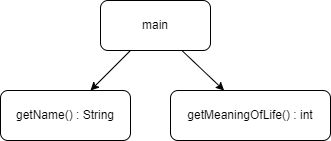
Exercices
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices
- Créer un fichier
DeclaringMethods.javaqui respecte le diagramme de dépendances ci-dessous ainsi que les détails d’implémentation suivants :showTheNumberaffiche la valeur retournée degetTheNumberet ne retourne rien àmainmakeItCapsretourne une valeur en majuscules du texte retournée pargetTheWords. Cette valeur sera affichée parmain. Indice: utiliser la méthodetoUpperCase()pour changer la casse de lettres.
- Prendre une capture d’écran de la section
Structurede VS Code. Quelle est le type de retour des méthodesshowTheNumberetmainqui ne retournent rien au programme? Conservez la capture comme./captures/declaringMethods_structure.png - Lancer le programme et prendre une capture d’écran de la session à la console. Nomme-la
./captures/declaringMethods.png. - Créer un diagramme de flux nommé
./diagrams/declaringMethods.drawiopour le programme. - Tracer l’exécution avec un diagramme de séquence d’exécution que vous écrivez dans le commentaire d’en-tête du code source.

Accueil > Programmer avec Java >
Méthodes recevant des arguments
Survol et attentes
Définitions
- Argument
- valeur passé à une méthode lors de l’appel. Cette valeur initialise le paramètre correspondant dans la déclaration de la méthode.
- Paramètre
- variable déclarée dans la signature d’une méthode qui reçoit une valeur lors de l’appel de la méthode. Cette variable est utilisée dans le bloc de code de la méthode et est détruite quand la méthode se termine.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Distinguer les méthodes qui n’ont pas de paramètres de celles qui en ont.
- Décrire ce qui se passe quand on appelle une méthode en lui passant des arguments.
- Lire et tracer un diagramme de séquence d’exécution pour un programme qui inclut des méthodes avec des paramètres.
Critères de succès
- Je peux implémenter des méthodes avec des paramètres dans mes programmes et reconnaître celles que j’utilise déjà.
Rôle des paramètres
Les paramètres rendent les méthodes plus flexibles. Leur code peut fonctionner avec différentes informations comme entrées, alors au lieu d’écrire une méthode pour chaque entrée possible, on a la possibilité de fournir cette information durant l’appel.
C’est un concept très puissant.
En mathématiques, vous avez quelque chose de similaire avec les fonctions, p. ex. : f(x) = x^2. Cette fonction nous donne le carré de x. x est donc un paramètre de f. En passant différentes valeur de x à la fonction f(x) on obtient différents résultats.
Exemples connus de méthodes avec paramètres
Vous connaissez déjà quelques méthodes avec des paramètres :
- toutes les formes de print“ :
System.out.print("Votre réponse > ")System.out.println("Bonjour " + name + "!")System.out.printf("%S\n", "david")
- créer un nouveau
Scanneravec :new Scanner(System.in) - spécifier le format de nombres sur un objet
Scanner:.useLocale(Locale.CANADA_FRENCH) - faire des calculs avec la classe
Math:Math.pow(2, 3),Math.sqrt(9),Math.abs(-5) - certaines opérations sur des objets
String: comme.charAt(0)
Qu'est-ce que ces exemples ont tous en commun?
Réponse
Il y a quelques indices que ces méthodes prennent des paramètres :
- Il y a toujours quelque chose entre les parenthèses quand on les appelle.
- Les info-bulles de notre éditeur nous montrent la liste des paramètres et les décrivent quand on passe la souris sur le nom de la méthode.
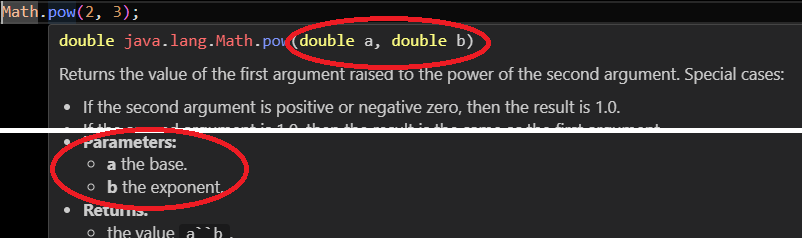
Exemples connus de méthodes sans paramètres
Les méthodes sans paramètres sont appelées avec des parenthèses vides.
Ceux que vous connaissez le mieux sont les méthodes de Scanner :
.next(),.nextLine(),.close()
On a aussi vu quelques méthodes de traitement des String :
.length(),.toUpperCase()
Notez que ces méthodes commencent avec un point . car ils s’appelent suite au nom d’un objet. Elles utilisent l’information qui est déjà dans l’objet (le Scanner, le String) pour faire ce qu’ils ont à faire et n’ont donc pas besoin de paramètres.
Écrire nos propres méthodes avec paramètres
On a déjà vus la structure générale de la déclaration d’une méthode. Ici on ajoute un dernier détail : la liste de paramètres.
Signature de méthode
Voici le gabarit complet pour la déclaration d’une méthode, incluant maintenant les paramètres :
[type de retour] [nom de la méthode] ( [liste de paramètres] ) {
// bloc de code,
// avec instruction `return` au besoin
}
La liste de paramètres a le format suivant, soit une liste de déclarations de variables :
type1 nom1, type2 nom2, type3 nom3, ...
où les types sont ceux qu’on connaît (int, double, String, Scanner, etc.) et les noms sont un nom de variable selon les règles et les conventions qu’on utilise déjà.
Corps de méthode
Le but de déclarer des paramètres est d’avoir des informations qu’on peut manipuler dans le code de la méthode. On ne connaît pas encore la valeur de ces informations, mais on connaît leur type (à cause de la signature). On peut alors travailler librement avec ces variables dans le code comme on le ferait avec n’importe quel autre variable du même type.
Appeller des méthodes avec paramètres
Quand on appelle une méthode qui a déclaré des paramètres dans sa signature, nous devons fournir des informations du type approprié entre les parenthèses. Sinon le programme nous signale une erreur de syntaxe.
Les informations passées durant l’appel s’appellent des arguments.
Par exemple, si nous avons déclaré cette méthode en déclarant un paramètre String name :
void greetWithName(String name) {
System.out.println("Bonjour " + name + "!");
}
Il faut absolument placer une valeur de type String entre les parenthèses durant l’appel, p. ex. :
void main(){
greetWithName("Jean");
greetWithName("Lucie");
greetWithName(); // erreur de syntaxe à cette ligne
}
Différences entre paramètres et arguments
Paramètres
- Une déclaration fixe
- Déclarés dans la signature de la méthode
- Le nom du paramètre est exclusif à la méthode et prend priorité à l’intérieur de la méthode si d’autres variables utilisent le même nom à l’extérieur de la méthode1
Arguments
- Les valeurs peuvent être différentes à chaque appel
- Spécifiées durant l’appel de la méthode
- Si on utilise une variable comme argument, la méthode copie sa valeur pour son exécution et ne change pas la valeur de notre variable
Comment ça marche? Le diagramme de flux
Comme le mécanisme appel-retour était plus explicite dans le diagramme de flux que dans le code, le mécanisme argument-appel l’est aussi.
Regardons donc le diagramme de flux pour l’exemple greetWithName ci-dessus.
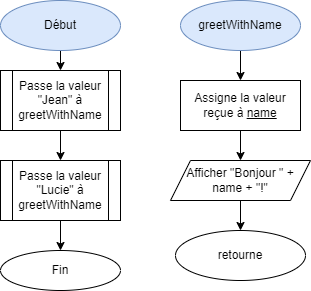
Le diagramme de flux nous aide à mieux voir la mécanique argument-paramètre. On voit quelque chose là qui n’est pas aussi apparent dans le code.
Dans l’algorithme pour la méthode :
- la première instruction assigne la valeur reçue à une variable (dans cette exemple,
name), ce qui correspond au paramètre de la méthode - le reste du code est définie selon ce nom de variable
Dans l’algorithme principal du diagramme :
- l’instruction d’appel inclut une information à passer à la méthode, ce qui correspond à l’argument
Dans le code Java pour la méthode greetWithName, l’assignation de la valeur reçue est masquée / implicite.
Dans le diagramme de flux, on doit le mentionner explicitement.
Structure générale pour l’utilisation d’une méthode avec paramètre


{kind=link}
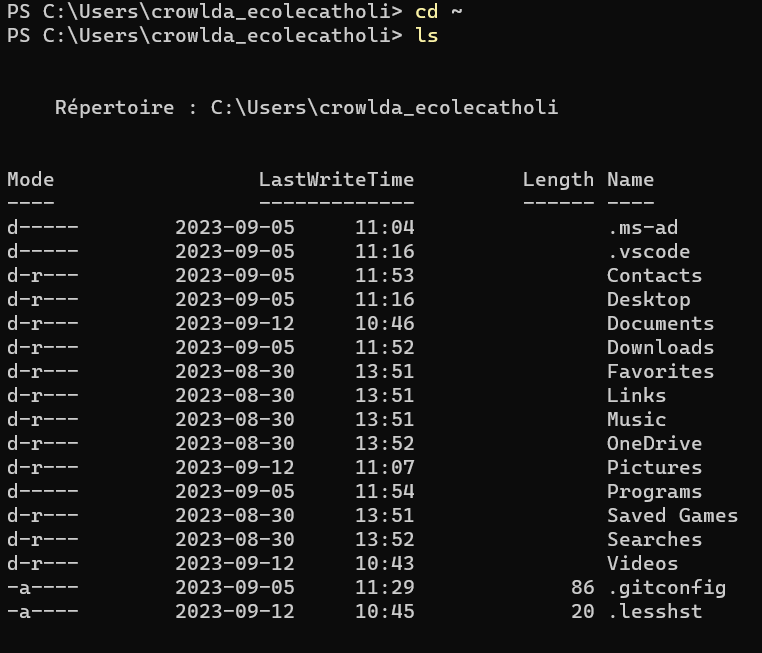{kind=link}
{kind=link}
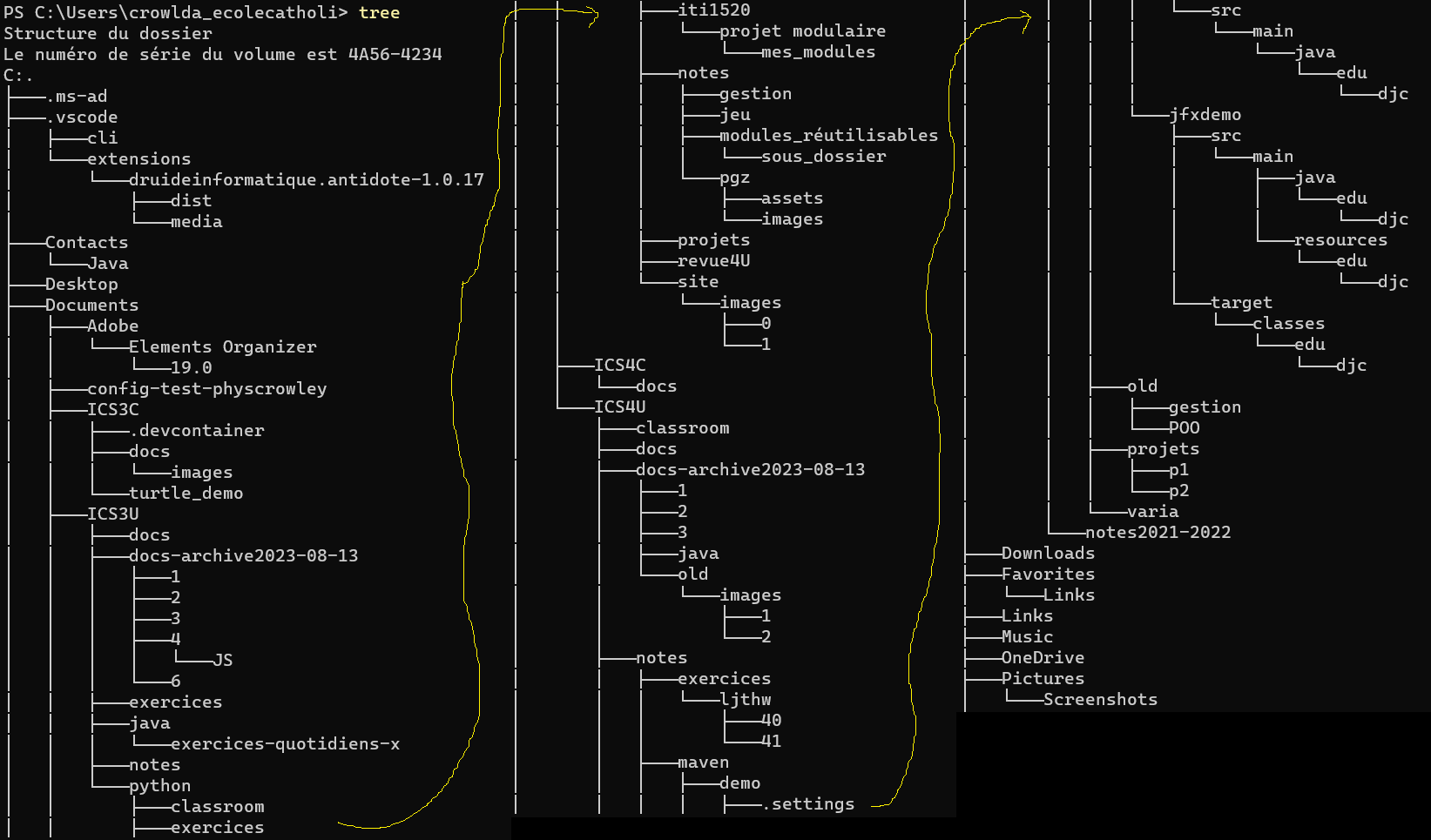{kind=link}
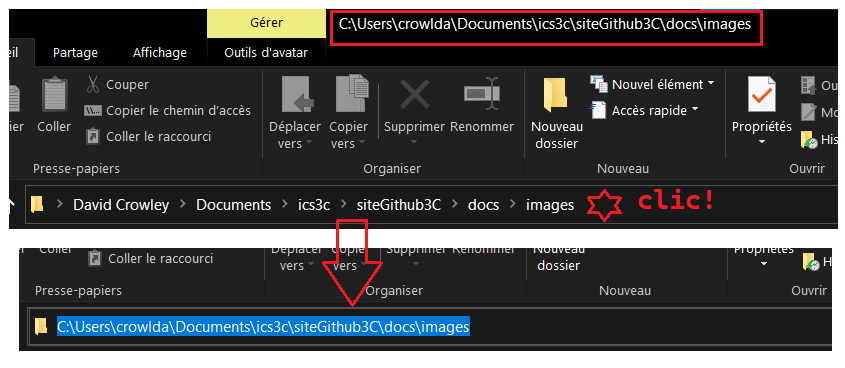{kind=link}
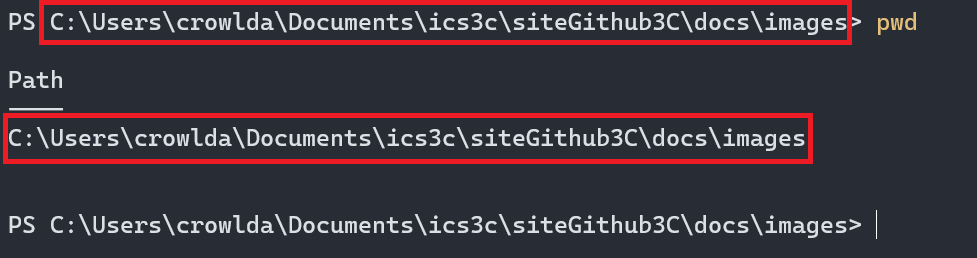{kind=link}
Deux exemples
Le programme ci-dessous montre un exemple simple (et banal) de deux méthodes avec des paramètres.
Fichier :
BasicParam.java
void greetWithName(String name) {
System.out.println("Bonjour " + name + "!");
}
int product(int a, int b) {
return a * b;
}
void main() {
String david = "David";
int x = 3;
int b = 5;
greetWithName(david);
System.out.println(product(x, b));
}
Remarquez qu’on a encore placé la méthode main à la fin du fichier.
void greetWithName(String name)
int product(int a, int b)
- Paramètres
int a, int b- s’attend à recevoir deux nombres entiers nommés a et b- Corps
- utilise les variables
aetbdans un calcul - Retour
- retourne le résultat du calcul, un type
int - Appel
- dans
mainavec les variablesx(contient3) etb(contient5); le paramètreaprend la valeur3et le paramètrebprend la valeur5; la valeur de retour est utilisée directement dans une instruction d’affichage
void main()
Ne prend aucun paramètre
Tracer la séquence d’exécution
On commence toujours le programme à main. Le diagramme de séquence d’appel pour le programme dans BasicParam.java serait :
9
10
11
12
13 -> 1
2
13 <- 3
14 -> 5
14 <- 6
15
Pour greetWithName
13 -> 1
est l’appel.
Parce qu’il y a des paramètres, c’est ici qu’on assigne au paramètre name la valeur de l’argument.
13 <- 3
est le retour à l’accolade fermante (retour implicite)
Pour product
14 -> 5
est l’appel.
Parce qu’il y a des paramètres, c’est ici qu’on assigne à a et b les valeurs des arguments.
14 <- 6
affichage dans main de la valeur de retour (retour explicite avec return)
Diagramme de dépendances
On commence à main et regarde quelles méthodes il appelle.
La nouveauté est qu’avec les paramètres, on inclut le type des chaque paramètre dans le bloc de la méthode entre des parenthèses. On peut trouvez cette information dans la signature de chaque méthode mais aussi dans la structure du document.
-
[nom de la méthode]( [liste des types de paramètres] ) : [type de retour]
Voici donc une version possible de ce diagramme. L’ajout des types des paramètres nous indique que chaque méthode dépend sur main pour leur fournir les valeurs String et int pour leurs paramètres. On voit aussi que main devra géré la valeur int retournée par la méthode product.
Exercices
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices
- Ajouter le fichier
BasicParam.javaà votre dossier de pratique. - Changer le nom de la variable
davidà un nom de votre choix. - Modifier le programme afin d’utiliser un Scanner dans
mainafin d’ajouter de l’interaction pour obtenir les valeurs d’un nom et des deux nombres. - Changer le type de nombre dans la méthode
productà desdouble. - Créer une nouvelle méthode
double add(double, doubl)en complétant sa signature. Il devrait ajouter la valeurs des deux paramètres et retourner le résultat au programme. - Mettre à jour de diagramme de dépendance (vous pouvez télécharger l’exemple dans les notes avec un clic droit > enregistrer sous) et l’ajouter à votre dossier
diagrammes. - Enrichissement : créer une nouvelle méthode
double linear(double, double, double)qui utilisera les méthodesaddetproductpour calculer le résultat dey = mx + b. Les trois paramètres sont utilisés pourm,xetbrepectivement. La méthode retourne la valeur dey. Tester cette méthode dansmainMettre à jour le diagramme de dépendances.
-
On étudie ce type de priorité en plus de détails dans la prochaine leçon ↩
Accueil > Programmer avec Java > Décomposition et modularité >
📚 Portée des variables
Survol et attentes
Définitions
- Portée d’une variable
- l’étendue du code source où le nom de variable est reconnue, se limitant aux accolades
{}du bloc qui le contiennent. Intentionnellement, la portée des variables est limitée pour mieux contrôler l’accès aux informations et pour permettre la réutilisation des mêmes noms de variables dans différentes parties du code source sans créer des conflits de noms. - Variable globale
- une variable déclarée en dehors de toutes les méthodes. Toutes les méthodes dans le fichier peuvent accéder directement à ces variables.
- Variable locale
- une variable déclarée dans une méthode ou, à l’intérieur des méthodes, dans une structure de contrôle (incluant leurs déclarations). C’est pourquoi les méthodes doivent recevoir des arguments et retourner des valeurs pour passer de l’information aux autres méthodes.
- Constante globale
- une variable globale qui est déclarée
finalpour indiquer qu’elle ne peut pas être modifiée. Les constantes globales sont utilisées pour des valeurs qui ne changent pas dans le programme et qui sont utilisées dans plusieurs méthodes. Par exemples : une référence au Scanner de la console, des valeurs de référence, des codes de couleur ANSI, des constantes mathématiques. Nommant ce type de valeur dans une constante globale rend le code plus lisible que d’inclure la valeur littérale partout où elle est utilisée.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Décrire la différence entre une portée globale et une portée locale.
- Savoir quelle variable, entre deux variables de même nom, sera préférée en considérant sa portée.
- Identifier si une variable spécifique est accessible ou non dans un endroit donné du code source.
- Décrire des raisons de préférer l’utilisation de variables locales à l’utilisation de variables globales.
Critères de succès
- Je minimise la visibilité des variables en leur donnant la plus petite portée nécessaire, ce qui veut dire utiliser une majorité de variables locales.
- J’utilise les variables globales dans mon code lorsque cela rend le code plus lisible et plus facile à maintenir.
- J’utilise des constantes globales pour les valeurs qui ne changent pas dans mon programme et qui sont utilisées dans plusieurs méthodes.
Portée des variables
La portée d’une variable est synonyme de sa visibilité : jusqu’à quels endroits dans le code est-ce qu’on peut “voir” cette variable (la nommer sans erreur de syntaxe)?
Les variables globales sont visibles partout dans un programme1. Elles sont déclarées à l’extérieur des méthodes et on peut les lire et les modifier dans toutes les méthodes du programme.
C’est un avantage parce qu’on a pas besoin d’échanger cette information entre les méthodes via des paramètres ou des valeurs de retour.
C’est un désavantage parce n’importe quelle partie de notre code peut modifier cette information, ce qui peut rendre le code difficile à corriger, briser la modularité du code (les sous-problèmes sont maintenant fusionnés autour de l’information partagée) ou introduire des problèmes de sécurité (modifications possibles au-delà des intentions originales).
Les variables locales sont seulement visibles dans la méthode où elles sont définies. Les paramètres et les variables définies dans le corps d’une méthode sont des variables locales. Jusqu’à présent, nous avons seulement utilisé des variables locales dans nos programmes.
Les avantages des variables locales sont que : l’information existe seulement à l’endroit où elle sera directement utile et plusieurs variables dans un programme peuvent avoir le même nom sans interférence parce que leurs portées ne se croisent pas.
Le désavantage est que pour partager l’information locale à une autre méthode, il faut “passer des messages” avec des arguments/paramètres et des valeurs de retour. Cela peut parfois rendre la liste des paramètres assez longue que c’est difficile à se rappeler quel paramètre va à quelle position.
---------------fichier------------------
déclaration de variable globale
méthode() {
déclaration de variable locale
}
méthode( les paramètres sont des variable locales ) {
}
----------------------------------------
Variables globales
C’est rarement une bonne idée d’utiliser des variables globales parce que le code devient beaucoup plus dur à déboguer. Mais il y a quelques cas où c’est une solution bien adaptée :
La valeur est constante et requise par plusieurs méthodes
On peut alors déclarer une constante globale en le préfixant avec le mot-clé final et en appliquant la convention du nom en majuscules. Les Scanner pour la console, les codes de couleur ANSI et les structures de données (à venir dans une prochaine section du cours) sont des exemples de bons candidats de constantes globales.
Dans ce cas, le fait que la valeur soit constante élimine la possibilité de modification inappropriée et la portée globale peut réduire la complexité et la répétitivité des déclarations et appels de méthodes.
La variable représente un état du programme que plusieurs méthodes doivent consulter ou peuvent modifier
Plusieurs informations dans un jeu tombent dans cette catégorie. Si ces variables n’étaient pas globales, la liste des paramètres pour la plupart des méthodes deviendrait ingérable. De plus, la restriction avec Java d’une seule valeur de retour rend l’exportation de plus qu’une modification à ces valeurs, si pas impossible, du moins très complexe. Cette complexité additionnelle rendrait le code plus dur à lire, à déboguer et à modifier. Les risques liés aux variables globales sont alors moindre que les risques avec l’autre approche.
Exemples de constantes globales
Fichier GlobalScanner.java
import java.util.*;
final Scanner CONSOLE = new Scanner(System.in); // visible globalement
void main() {
// final Scanner CONSOLE = new Scanner(System.in); // ne serait pas visible dans getName ni getInteger
String name = getName();
int age = getInteger("age");
System.out.printf("%s a %d ans.\n", name, age);
}
String getName() {
System.out.print("Quel est votre nom? > ");
return CONSOLE.nextLine();
}
int getInteger(String what) {
System.out.printf("Entrez un nombre entier pour votre %s > ", what);
int result = CONSOLE.nextInt(); // pour consommer la valeur
CONSOLE.nextLine(); // pour consommer le retour de ligne aussi
return result;
}
Ici le Scanner pour la console est utilisée dans plusieurs méthodes et ne change pas de valeur (réfère toujours à System.in), alors c’est un bon candidat de constant globale.
Notez que la déclaration commence avec final disant à Java que cette valeur ne peut jamais changer durant l’exécution. Notez aussi qu’on a écrit le nom en majuscules afin de mieux le repérer comme constante.
Fichier GlobalColorCodes.java
import java.util.*;
final String RED = "\033[0;31m";
final String GREEN = "\033[0;32m";
final String YELLOW = "\033[0;33m";
final String RESET = "\033[0m";
void printRed(String text) {
System.out.println(RED + text + RESET);
}
void printGreen(String text) {
System.out.println(GREEN + text + RESET);
}
void printYellow(String text) {
System.out.println(YELLOW + text + RESET);
}
void main() {
printRed("Ceci est un message d'erreur!");
printGreen("Ceci est un message de succès!");
printYellow("Ceci est un avertissement");
System.out.printf("%sCe texte%s est en %ssurbrillance%s%s!!!%s",
GREEN, RESET, YELLOW, RESET, RED, RESET);
}
Ici on a plusieurs constantes globales pour les différents codes de couleur pour le texte à la console. Ces constantes sont utilisées dans les différentes méthodes, incluant main qui fait un usage sur mesure pour la dernière phrase.
Variables globales d’état
Voici un exemple banal pour quelques variables globales pour un jeu.
Fichier : GlobalGameState.java
int lives = 3;
int xp = 0;
boolean hasWeapon = true;
boolean hasHorse = true;
void diedInBattle() {
xp += 5;
lives--;
hasWeapon = false;
System.out.println("Vous êtes mort au combat et avez perdu votre arme!");
}
void diedWhileRiding() {
xp += 2;
lives--;
hasHorse = false;
System.out.println("Vous êtes mort en tombant de votre cheval!");
}
void showStats() {
System.out.println("Vies : " + lives);
System.out.println("Points d'expérience : " + xp);
System.out.println("Vous avez une arme : " + hasWeapon);
System.out.println("Vous avez un cheval : " + hasHorse);
}
void main() {
showStats();
diedInBattle();
showStats();
diedWhileRiding();
showStats();
}
Priorité de nom selon la portée
Une des caractéristiques d’un programme avec différentes portées de variables est que le même nom peut être déclaré à plusieurs endroits sans conflits en autant que leurs portées soient différentes.
S’il y a deux variables du même type et du même nom, mais une est globale est l’autre est locale, la version locale sera toujours utilisée en priorité.
Voici quelques exemples courts pour illustrer la chose.
/* Globale versus locale */
String name = "Steve";
void main() {
String name = "Angelica";
name = "Naomi";
System.out.println(name);
}
Quelle variable est modifiée à la ligne 7? locale ou globale?
La variable locale, déclarée à la ligne 6, car elle a priorité sur la variable globale.
Quel nom s'affiche? Naomi ou Steve?
Naomi. La variable locale dans main masque la variable globale (qui n’est plus accessible dans main à cause de ce masquage).
/* Locale versus locale */
void main() {
String name = "Angelica";
System.out.println(rename(name));
System.out.println(name);
}
String rename(String name) {
name = "Demonica";
return name;
}
Qu'est-ce qui s'affiche à la ligne 5?
Demonica. C’est la valeur de retour de rename.
Qu'est-ce qui s'affiche à la ligne 6?
Angelica. Le paramètre name est locale à la méthode rename. Cette variable récoit la valeur de la variable dans main comme argument. Par contre, ce paramètre (locale à rename) n’existe plus après le retour de la méthode. rename retourne la nouvelle valeur, mais la variable name dans main ne la reçoit pas. La valeur de retour passe plutôt directement dans un print. Alors la variable locale dans main n’a subit aucune modification du début jusqu’à la fin.
Quelques exemples d’erreur (de conflit) de portée
Variable inaccessible
void isolated() {
int answer = 7;
}
void main() {
System.out.println(answer); // erreur "cannot find symbol"
}
Ici, answer est locale à la méthode isolated, alors il n’est pas visible dans main, contrairement à si cette variable avait été déclarée globalement, à l’extérieure d’une méthode.
int answer = 7; // déclaration globale
void main() {
System.out.println(answer); // answer est visible
}
Déclaration dupliquée
String thing(String t) {
String t = t + "2"; // erreur "duplicate local variable"
return t;
}
void main() {
System.out.println(thing("thing"));
}
Ici, dans la méthode thing on déclare déjà un paramètre String t. Alors quand on déclare une autre variable locale du même nom à la ligne 2, Java nous indique une erreur. Si l’intention était de simplement modifier la valeur reçue dans le paramètre alors on peut réécrire la ligne 2 comme ceci :
String thing(String t) {
t = t + "2"; // référence valide au paramètre t déjà déclarée
return t;
}
void main() {
System.out.println(thing("thing"));
}
La différence est que la ligne 2 n’est plus une déclaration d’une nouvelle variable. Elle est désormais une référence à la variable déjà déclarée dans la liste de paramètres.
Exercices
📚 Tester la compréhension
Faire les deux questions de choix multiples au début de la page ici pour vérifier votre compréhension de la portée des variables. Ne faites pas les problèmes de programmation car ils intègrent d’autres concepts que nous ne verrons pas dans ce cours.
La raison que les exercices de programmation sur la page sont déconseillés est qu’ils sollicitent des concepts de la programmation orientée objet que nous n’avons pas appris. Ce sont plutôt des concepts du cours ICS4U.
Je vous suggère plutôt les exercices pratiques suivants qui sont mieux adaptés à notre contexte.
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices.
Cette pratique vise à démontrer les différences entre une approche de variables globales et une approche de variables locales dans un cas où les deux sont des choix valides.
Le contexte est l’utilisation d’un symbole spécifique comme indicateur d’invite de réponses chaque fois qu’on pose une question à l’utilisateur. On veut que ce symbole soit facile à changer si on veut utiliser un autre symbole. On veut aussi que le symbole soit utilisé dans plusieurs méthodes.
Approche avec variable globale
Avec cette approche, on déclare une variable globale pour le symbole. Par la suite nous concatenons ce symbole à la fin de chaque question posée à l’utilisateur. Pour montrer l’utilité à travers plusieurs méthodes, chaque question se trouve dans sa propre méthode.
Le Scanner de la console est également déclaré comme variable globale pour un accès direct pour toutes les méthodes.

Fichier
GlobalVar.java
import java.util.*;
final Scanner CONSOLE = new Scanner(System.in);
final String PROMPT = " > ";
void main() {
String name = getName();
int age = getAge();
System.out.println("Votre nom est " + name + " et vous avez " + age + " ans.");
}
String getName(){
System.out.print("Quel est votre prénom?" + PROMPT);
String name = CONSOLE.next();
CONSOLE.nextLine(); //vider le reste de la ligne
return name;
}
int getAge() {
System.out.print("Quel est votre âge?" + PROMPT);
int age = CONSOLE.nextInt();
CONSOLE.nextLine();
return age;
}
- Copiez ce code dans un fichier
GlobalVar.javaet l’exécuter pour voir comment il fonctionne. - Ajouter un commentaire après chaque déclaration de variable pour indiquer s’il s’agit d’une variable locale ou globale. Les variables sont
CONSOLE,PROMPT;name,age;name;age. - Modifiez la valeur de
PROMPTpour utiliser un autre symbole que>. Lancez le programme de nouveau pour voir le changement. - Renommez les variables dans
mainet lancez le programme pour voir si ça change le fonctionnement. Selon vos observations, est-ce que la variable nomméenamedansmainest le même objet en mémoire que la variable nomméenamedansgetName?
Approche avec variables locales seulement
Avec cette approche, les variables à partager sont déclarées localement dans main et partagé via le mécanisme argument-paramètre. De plus, au lieu de créer une variable pour le symbole prompt, on crée une méthode. Parce que chaque méthode est visible par les autres dans le fichier, toutes les autres méthodes peuvent l’appeler.
Fichier
LocalVar.java
import java.util.*;
void main() {
Scanner console = new Scanner(System.in);
String name = getName(console);
int age = getAge(console);
System.out.println("Votre nom est " + name + " et vous avez " + age + " ans.");
}
void prompt(String question) {
System.out.print(question + " > ");
}
String getName(Scanner in) {
prompt("Quel est votre nom?");
String name = in.next();
in.nextLine(); // vider le reste de la ligne
return name;
}
int getAge(Scanner in) {
prompt("Quel est votre âge?");
int age = in.nextInt();
in.nextLine();
return age;
}
- Copiez ce code dans un fichier
LocalVar.javaet l’exécuter pour voir comment il fonctionne. Confirmez qu’il fonctionne - du point de vue de l’utilisateur - de manière identique àGlobalVar. - Modifiez le programme pour changer le symbole d’invite de commande dans
prompt(). Est-ce que c’était plus facile ou difficile ou équivalent à ce qu’il fallait faire la dernière fois? - Énumérer les éléments que vous avez préférez de la version
GlobalVaret les éléments que vous avez préférez dansLocalVar. Énumérer aussi des éléments que vous n’avez pas aimé dans les deux versions. Ajoutez ces listes dans un commentaire d’en-tête dans un troisième fichierPreferredVar.java. Combiner vos éléments préférés de chaque version dans cette troisième version ou apporter des modifications pour créer votre propre approche. Résoudre les erreurs de fusion et lancer ce troisième programme pour vérifier qu’à la console l’expérience reste identique pour l’utilisateur malgré les changements.
-
Il y a des nuances à “partout dans un programme”, mais ces nuances ne sont pas importants dans ce cours. Pour votre curiosité, voici quand même un bref survol. Nos programmes tiennent dans un seul fichier .java, alors partout dans le fichier serait plus apte. Les fichiers .java représentent implicitement une classe Java. Alors partout dans la classe serait aussi plus précis. Mais les variables Java peuvent être qualifiées de publiques ou privées. Les variables privées sont seulement “globales” dans la classe, tandis que les variables publiques sont “globales” pour tout un package de classes (à l’extérieur de la classe elle-même). Ce concept s’étend à la portée des classes (publiques ou privées) dans les packages et la portée des packages (exportées ou non) dans des modules. ↩
Accueil > Programmer avec Java >
🛠️ Tests unitaires
- Cas de test
- Approche naïve pour les tests unitaires
- JUnit - framework Java pour les tests unitaires
- Exemple de test unitaire avec JUnit
Survol et attentes
Dans un programme décomposé, c’est important de tester chaque méthode avant de l’intégrer dans une méthode appelante. Ainsi, si une erreur se produit, on limite la recherche de l’erreur à une seule méthode.
Définitions
- Test unitaire
- vérifier si une méthode produit le résultat attendu pour un ensemble d’entrées spécifiques. Un test unitaire évalue une seule méthode, d’où le terme “unitaire”.
- Cas de test
- un scénario (une entrée spécifique) qui doit être testé pour une méthode. Chaque cas de test fait le lien entre les entrées et les sorties attendus. Un test unitaire inclut généralement tous les cas de test identifiées pour une méthode.
- JUnit
- un framework de test unitaire pour Java. Nous utiliserons la suite d’outils Java dans VS Code pour installer et exécuter les tests JUnit. De plus, ces outils créent automatiquement les fichiers de test et les signatures des méthodes pour chaque test unitaire.
- Framework
- un ensemble d’outils et de conventions qui facilitent le développement de logiciels. Un framework est plus vaste qu’un package ou une module de code, et la plupart des applications logicielles sont bâtis à l’aide de frameworks. JUnit est un framework pour les tests unitaires.
- Test d’entrée/sortie
- test unitaire qui doit tenir compte des valeurs normalement saisies via l’entrée standard et affichées à la console. Ces tests sont plus difficiles à automatiser parce qu’il faut temporairement rediriger l’entrée et/ou la sortie standard vers des sources de texte écrites à l’avance dans le test.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- décrire c’est quoi un test unitaire et pourquoi on les utilise.
- savoir comment choisir des cas de test pour une méthode donnée.
- savoir comment utiliser les outils dans VS Code pour créer et exécuter des tests unitaires pour des programmes Java.
Critères de succès
Évalués sommativement dans ce cours :
- Je suis capable de rédiger une liste de cas de test pour une méthode donnée et d’intégrer ces cas dans le test unitaire.
- Je suis capable d’adapter le gabarit de test d’égalité pour mes méthodes.
Aspirationnels - on n’a pas assez de temps dans ce cours pour devenir vraiment bons à ces compétences, mais on peut les explorer :
- Je suis capable de créer un fichier de test et les méthodes de test pour mes programmes en utilisant les outils de JUnit dans VS Code.
- Je suis capable d’adapter le gabarit de test d’entrée et de test de sortie pour mes méthodes.
Pourquoi faire des tests unitaires?
Un programme devient très rapidement large et complexe. On utilise déjà la décomposition pour gérer la complexité et la taille du programme : elle nous permet de résoudre une série de petits problèmes.
Par contre, l’avantage de la décomposition est largement gaspillé si on ne vérifie pas le bon fonctionnement de chaque méthode - chaque morceau du problème décomposé - avant de l’intégrer dans la méthode plus haut dans la chaîne d’appels. La raison est la suivante : s’il y a une erreur dans une méthode qu’on n’a pas testé mais on l’intègre sans connaissance dans une autre méthode, lorsque on exécute éventuellement le programme, on ne sait pas si l’erreur vient de la méthode appelante ou de la méthode appelée. Ce problème explose avec le nombre d’intégrations de méthodes qu’on fait avant de tester.
Avec les tests unitaires, on peut isoler les erreurs à une seule méthode, limitant la quantité de code à vérifier pour corriger l’erreur. Le but est de tester chaque méthode et de s’assurer de son fonctionnement avant de l’intégrer dans une autre méthode. Ainsi, si une erreur se produit, on sait qu’elle vient du plus récent code qu’on a écrit et non des autres méthodes qui existent déjà.
Un autre avantage des tests unitaires formelles, comme ceux avec le framework JUnit, est que si on modifie le programme, on peut relancer tous les tests que nous avons déjà écrits pour s’assurer que les modifications n’ont pas cassé quelque chose qui fonctionnait déjà.
Cas de tests
En faisant un test unitaire, on doit savoir quel comportement est attendu de notre méthode, soit qu’est-ce qui constitue un résultat acceptable. Les cas de tests sont simplement la description de ces comportements attendus pour une méthode donnée. C’est, en fait, la partie la plus importante de l’écriture des tests unitaires. Si on ne sait pas ce qu’on attend de notre méthode, on ne peut pas écrire de tests pour vérifier si la méthode fonctionne correctement.
Déterminer quels sont les cas de test importants est un art. Il faut trouver un équilibre entre tester tous les cas possibles et tester seulement les cas les plus importants. Voici quelques pistes pour déterminer les cas de test pour une méthode :
- Cas de test limites : les cas de test qui couvrent les valeurs aux limites de ce qui serait normalement attendu. Par exemple, si on doit donner une note entre 0 et 100, on devrait tester avec 0 et 100. De même, si dans la zone des valeurs acceptés, il y a des limites pour différentes catégories, on devrait tester ces limites aussi. Par exemple, si la note de passage est de 50, on devrait tester avec 49 et 50.
- Cas de test invalides : si notre programme doit gérer la qualité des entrées, il faut aussi prévoir les cas de test qui couvrent les valeurs qui ne devraient pas être acceptées. Par exemple, si on doit donner une note entre 0 et 100, on devrait tester avec -1, 101, et des lettres.
Tableau de cas tests
Pour l’exemple précédent, soit d’une méthode qui calcule la moyenne de deux notes et retourne le résultat comme valeur de retour, on peut préparer le tableau de cas de test suivant :
| Intention | Entrée | Sortie attendue |
|---|---|---|
| deux notes int valides | 80, 90 | 85.0 |
| deux notes double valides | 80.0, 90.0 | 85.0 |
| notes limites | 0, 100 | 50.0 |
| notes limites | 0, 0 | 0.0 |
| notes limites | 100, 100 | 100.0 |
| note négative | -1, 90 | -1.0 // une valeur drapeau pour signaler un résultat invalide |
| note supérieur à 100 | 80, 101 | -1.0 // une valeur drapeau pour signaler un résultat invalide |
On peut représenter ce même tableau comme commentaire de bloc ou comme javadoc dans la méthode de test unitaire, comme ceci :
/*
* Test la méthode `average` pour les cas suivants :
* - deux notes int valides : 80, 90 => 85.0
* - deux notes double valides : 80.0, 90.0 => 85.0
* - notes limites : 0, 100 => 50.0
* - notes limites : 0, 0 => 0.0
* - notes limites : 100, 100 => 100.0
* - note négative : -1, 90 => -1.0 // une valeur drapeau pour signaler un résultat invalide
* - note supérieur à 100 : 80, 101 => -1.0 // une valeur drapeau pour signaler un résultat invalide
*/
Approche naïve pour les tests unitaires
Sans utiliser des outils spécialisés, nous pouvons simplement lancer manuellement le programme après avoir ajouté une nouvelle méthode. Naturellement, on aura probablement appelé la méthode dans la logique globale du programme pour voir si elle fonctionne. Ça marche pour des programmes très simples mais c’est limité même dans ces cas :
- S’il y a plusieur cas de test, on doit les exécuter un par un et comparer les résultats manuellement, possiblement en insérant des
System.out.println()pour afficher les résultats qu’on aura à retirer plus tard. Cela est une tâche lourde et sujette à des erreurs. - Si plusieurs parties du programme doivent s’exécuter avant d’arriver à l’appel de la nouvelle méthode à tester, on doit passer à travers tout le programme pour chaque test. Cela est une perte de temps et d’énergie qui fait en sorte qu’on évite souvent de tester rigoureusement les méthodes.
Mieux mais sans les outils de test unitaire
Pour faire mieux que l’approche décrite ci-dessus, on peut tenter d’écrire des tests unitaires sans l’appui des outils, notamment parce que l’installation des outils peut être complexe et parce que ça nous évite d’apprendre comment utiliser les outils. En écrivant nos propres tests, on peut définitivement pallier aux deux problèmes soulevés ci-dessus :
- on peut inclure les cas de test dans notre code de test
- on peut inclure les comparaisons automatiques avec les résultats attendus dans notre code de test
- on peut exécuter les tests unitaires sans passer par la logique globale du programme
Par contre, tout ça exige la rédaction de beaucoup de code additionnel (avec l’introduction presque garantie de nouvelles erreurs). Et tout ce nouveau code est probablement mieux écrit et définitivement déjà validé dans les outils de test unitaire.
De plus, le code de test “maison” est le plus facile à écrire et à lancer dans la même classe que les méthodes à tester. Cela rend le code dans cette classe plus difficile à lire, sans parler de la méthode main qui peut commencer à ressembler à quelque chose comme ceci :
Fichier:
MyGreatProgram.java
void main() {
// tests unitaires
// testMethod1(); // masqué derrière un commentaire pour ne pas l'exécuter
// testMethod2();
testMethod3();
// logique globale du programme
// ...
}
void method1() {
// ... code qu'on veut utiliser dans le programme
}
void testMethod1() {
// ... code pour tester la méthode qu'on veut utiliser dans le programme
}
// ... reste des méthodes de la classe
Approche standard pour les tests unitaires avec JUnit 4
En se servant des outils existants, comme JUnit :
- notre classe peut être écrite exactement comme on l’a décrit avec la décomposition du problème sans code additionnel,
- les tests peuvent être écrits plus succinctement avec le code fourni par JUnit,
- le lancement des tests est entièrement indépendant du lancement de notre programme et
- nous n’avons pas besoin de programmer comment afficher les résultats des tests parce que JUnit le fait pour nous.
L’utilisation de JUnit nous impose pour la première fois une structure de projet Java qui dépasse un seul fichier :
- le fichier pour notre code et
- un autre fichier pour les tests unitaires.
La section suivante décrit la modification qu’il faut apporter à nos programmes pour les tester avec JUnit.
Structure de projet pour les tests unitaires
On a vu dans une leçon sur les bases de Java que ce langage est utilisé pour d’énormes projets logiciels et que le code peut être divisé en plusieurs types d’unités autonomes du plus grand (les logiciels et les frameworks) aux unités intermédiaires (les modules et les packages) et finalement aux unités atomiques (les classes).
Parce que tous nos programmes jusqu’à présent tenaient dans une seule classe, le compilateur Java nous permettait d’omettre une déclaration de classe et de simplement écrire des déclarations pour nos méthodes et nos variables globales.1 De plus, on n’avait pas à se préoccuper des mots-clés qui sont utilisés pour gérer la visibilité des éléments de notre classe (public, private) ni de comment les méthodes sont appelées (static ou non). On ne travaillera pas avec ces concepts dans ce cours (ils sont couverts dans le cours de 12e année), mais on doit quand même ajouter une chose à notre code pour le tester avec JUnit : une déclaration de classe.
La déclaration de classe donne un nom à notre code et permet au code dans la classe test d’y référer pour utiliser nos méthodes.
Ainsi, si on a un fichier Calculator.java avec le contenu suivant :
int add(int a, int b) {
return a + b;
}
void main() {
System.out.println(add(1, 2));
}
et on veut tester la méthode add, on doit ajouter une déclaration de classe autour de notre code pour le tester avec JUnit :
class Calculator {
int add(int a, int b) {
return a + b;
}
void main() {
System.out.println(add(1, 2));
}
}
- Utiliser l’outil “Mettre le document en forme” dans VS Code pour rétablir une bonne indentation après avoir ajouté la déclaration de classe (n’oubliez pas son accolade fermante à la fin du code).
- Le nom de la classe doit être le même que le nom du fichier et on devrait respecter les conventions Java pour les noms de classe/fichier : commencer par une majuscule et utiliser la casse chameau pour les noms composés.
Pour renommer le fichier, au besoin, utiliser l’outil “Renommer le fichier” dans VS Code parce qu’il renommera automatiquement le nom de la classe et toutes les références à cette classe à travers le projet.
Maintenant, le code dans la classe de test pourra créer un objet de type Calculator pour tester la méthode add(), comme on ajoute des objets de type Scanner pour utiliser ses méthodes next*().
Travailler avec JUnit dans VS Code et l'Extension Pack for Java
On va utiliser pour la première fois l’option “Source Actions” dans VS Code pour créer des tests unitaires. Cette section vous montre comment le faire étape par étape.
ÉTAPE 1 : Créez votre fichier dans un projet Java et écrire au moins une de ses méthodes. Pour cet exemple, on peut utiliser le fichier Calculator.java avec le contenu suivant :
class Calculator {
int add(int a, int b) {
return a + b;
}
void main() {
System.out.println(add(1, 2));
}
}
- ÉTAPE 2
-
Ouvrir le fichier dans VS Code et attendre une minute afin de laisser les outils Java s’activer.
- ÉTAPE 3
-
Faites un clic droit n’importe où dans le fichier et choisissez “Source Action…”. Vous devriez voir une option pour
Generate Tests. Cliquez dessus. |
| 
- ÉTAPE 4
-
Si c’est la première fois qu’on fait ces étapes dans un projet, VS Code vous donnera une erreur et un bouton
Enable tests. Cliquez dessus et choisir le frameworkJUnit. VS Code installera automatiquement les dépendances nécessaires pour JUnit dans votre projet, dans le sous-dossierlib. |
|  |
| 
Note : vous aurez à faire cette étape une seule fois par projet, mais vous aurez à la refaire si vous créez un nouveau projet.
- ÉTAPE 5
-
Tapez
Enterpour acceptez le nom proposé pour la classe de test, généralement[nom de ma classe]Test. Dans notre exemple, ce seraitCalculatorTest. - ÉTAPE 6
-
Sélectionnez la méthode que vous voulez tester. Dans notre exemple, on veut tester
add. Cliquez surEnterpour accepter. La classe sera créée avec la signature de la méthode de test pouradd. Cochez seulement la plus récente méthode, celle qui n’a pas encore de test unitaire. |
| 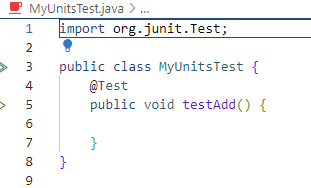
Notez qu’on ne doit pas tester
mainparce qu’il contient la logique globale du programme.mainn’est pas une “unité” mais plutôt “l’intégration” ultime de toutes les unités de notre programme. Ça ne fait pas de sens de préparer des tests unitaires pour cette méthode. - ÉTAPE 7
-
Écrivez les tests unitaires pour les méthodes choisies. C’est à cet étape qu’on doit considérer les cas de test et les implémenter.
Les sections suivantes donnent des gabarits de tests unitaires que vous pouvez utiliser pour écrire vos tests.
- ÉTAPE 8
-
Exécutez les tests unitaires en cliquant sur le bouton
Run Testà côté de la méthode de test ou en cliquant sur le boutonRun All Testsen haut de la classe de test.
Notez que s’il y a une seule classe dans votre projet qui contient des erreurs de syntaxe, vous recevrez un message d’erreur avant le lancement des tests parce que les outils Java compilent tout votre projet. Si l’erreur n’est pas dans la classe à tester ni dans la classe avec les tests, vous pouvez simplement cliquer sur le bouton
Continuepour ignorer ces erreurs et lancer les tests.
- ÉTAPE 9
-
Analysez les résultats des tests dans la fenêtre de sortie de JUnit. Si les tests sont tous réussis, rien ne s’affichera et vous devrez vous rendre à l’onglet “Test Results” pour voir la sortie. Si un test échoue, vous verrez un message d’erreur dans la fenêtre de sortie.
Notez que la sortie texte dans la partie gauche ne dit pas grand-chose d’utile. C’est plutôt la partie droite qui donne l’état de chacun des tests. Le crochet vert est pour un test réussi, le point rouge est pour un test échoué. Vous pouvez cliquer sur le résultat de chaque test pour plus de détails ou pour les lancer de nouveau.
ÉTAPE 10 : Corrigez les erreurs dans votre code et réexécutez les tests jusqu’à ce qu’ils passent tous. Les erreurs peuvent se trouver dans le test unitaire ou dans la méthode que vous testez… mais pas ailleurs! C’est l’avantage de faire des tests unitaires pour chaque méthode qu’on finit d’écrire.
ÉTAPE 11 : Répétez les étapes 3 à 10 pour chaque nouvelle méthode que vous écrivez dans la classe principale du projet.
Gabarits - code de démarrage pour vos tests unitaires avec JUnit
Votre responsabilité principale en lien avec les tests unitaires est la définition des cas de tests pour chaque méthode que vous écrivez.
Par contre, vous pouvez aussi apprendre comment implémenter les tests unitaires qui appliquent ces cas de test à vos méthodes. Pour vous aider, les exemples de tests unitaires ci-dessous vous donnent du bon code de démarrage pour quatre cas communs :
- un test d’égalité,
- un test d’entrée (avec un Scanner global),
- un test d’entrée (avec un Scanner local) et
- un test de sortie.
Selon la structure de vos méthodes, vous aurez probablement à combiner le code de tests différents, p. ex. d’égalité et d’entrée ou d’éntrée et de sortie pour avoir la bonne structure de test pour vos méthodes.
Structure de la classe de test
Voici un gabarit de base pour une classe de test unitaire où vous remplacerez “MyClassname” par le nom de la classe que vous testez. Vous pouvez ajouter autant de méthodes de test que nécessaire dans cette classe.
import static org.junit.Assert.*; // pour les méthodes de comparaison
import org.junit.Test; // pour l'annotation @Test et les outils associés
public class MyClassnameTest {
// déclaration d'un objet de la classe à tester
// p. ex. Calculator calc = new Calculator();
@Test
// déclaration d'une' méthode de test pour une méthode dans votre code
@Test
// déclaration d'une méthode de test pour une autre méthode dans votre code
}
Test d’égalité
Les tests d’égalité sont pour des méthodes qui retournent une valeur. On compare la valeur retournée par la méthode avec la valeur attendue.
Exemple de base
Considérant notre méthode add dans la classe Calculator :
class Calculator {
// ... reste du code de la classe
int add(int a, int b) {
return a + b;
}
}
La classe de test produit par les outils de JUnit dans VS Code serait le suivant, avec quelques lignes additionnelles :
import static org.junit.Assert.*; // ajoutez cette ligne pour les méthodes de comparaison
import org.junit.Test;
public class CalculatorTest {
Calculator calc = new Calculator(); // ajoutez cette ligne pour faire référence à votre code
@Test
public void testAdd() {
}
}
On peut écrire le test unitaire testAdd dans la classe CalculatorTestcomme suit à l’intérieur de la classe de test :
@Test
public void testAdd() {
/*
* Cas de tests pour int add(int, int)
*
* Descr. Entrées Sortie attendue
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* base 1, 2 3
*/
assertEquals(3, calc.add(1,2));
}
Deux points qui peuvent faire planter ce code :
- La méthode
assertEquals()ne sera pas reconnue si vous n’avez pas ajouté l’imporation static d’Assertau début du fichier de test. Voir le gabarit pour la classe de test ci-dessus. - La méthode
add()ne sera pas reconnue si vous n’avez pas créé une variablecalcde typeCalculatordans la classe de test. Voir le gabarit pour la classe de test ci-dessus.
Notez que assertEquals est une méthode de JUnit qui compare le premier argument avec le deuxième argument et lève une exception si les deux arguments ne sont pas égaux. C’est la méthode la plus courante pour tester des valeurs de retour.
Il y a plusieurs autres détails à noter dans ce code :
- L’annotation
@Testet la signature de la méthode ont peut-être été créées automatiquement si vous avez suivi les étapes ci-dessus. L’annotation@Testdevient un point de lancement du code de test pour JUnit. - On écrit les cas de test dans un commentaire de bloc au début de la méthode de test. Dans l’exemple, on a simplement inclut un cas de test, mais vous devrez considérer l’ensemble des cas à tester dans la méthode.
- On utilise la méthode
assertEqualspour implémenter le cas de test, soit comparer le résultat attendu avec la valeur de retour de la méthode testée. Il devrait y avoir un appel àassertEqualspour chaque cas de test.
Exemple pour comparer des 'double'
L’exemple de base fonctionne pour tous les types sauf les valeurs à virgule flottante (comme les double).
Avec les double, dû à la conversion inexacte entre le binaire (dans la machine) et le décimal (dans la représentation du nombre), il y a toujours - ou presque - des erreurs d’arrondissement. Ainsi on ne peut jamais évaluer l’égalité entre deux double directement comme on le fait avec les autres types de données.
L’algorithme à utiliser se résume à :
valeur 1 = valeur 2 ± une marge d'erreur acceptableouvaleur absolue de (valeur 1 - valeur 2) <= une marge d'erreur acceptable(la valeur absolue ignore le signe du résultat)
Par exemple, pour des notes de cours à une décimale près on pourrait note1 = note2 ± 0.1 ou note1 = note2 ± 0.05, selon votre préférence.
Pour les double, JUnit fournit une méthode assertEquals qui prend un troisième argument, la marge d’erreur acceptable. Par exemple, pour une méthode average qui retourne la moyenne de deux nombres à une décimale près, on pourrait écrire le test unitaire comme suit :
@Test
public void testAverage() {
/*
* Cas de tests pour double average(double, double) :
*
* Descr. Entrées Sortie attendue
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* base 80.0, 90.0 85.0
*/
assertEquals(85.0, calc.average(80.0, 90.0), 0.1);
}
Notez que nous fournissons la valeur attendue et la valeur de retour de la méthode testée comme avec l’exemple. Cependant, on ajoute aussi un troisième argument, la marge d’erreur acceptable. Dans cet exemple, on accepte une différence de 0.1 entre la valeur attendue et la valeur de retour.
Le choix de la marge acceptable dépend de la précision requise par votre programme. Comme règle de base, on devrait choisir une marge d’erreur qui est plus petite que la précision finale que nous voulons parce que les erreurs d’arrondissment s’accumulent à chaque opération.
Donc la marge de 0.1 si on veut des résultats à une place décimale est trop généreuse et on perd beaucoup de précision. Règle de base : utiliser une marge d’erreur au moins 3 chiffres de plus que la précision finale désirée. P. ex., si on veut une précision finale de 0.1 on devrait choisir une marge d’erreur d’au maximum 0.0001. le test ci-dessus serait modifié à :
assertEquals(85.0, calc.average(80.0, 90.0), 0.0001);
Test d’entrée
Pour tester une méthode qui sollicite des entrées de l’utilisateur via la console, on a deux options selon la façon dont le Scanner de la console est géré dans la classe du programme :
Scanner static et global | Scanner passé comme paramètre (Scanner local) |
|---|---|
 |  |
Dans le cas d’un Scanner global, parce que la vie de la variable est plus longue que la vie de la méthode, on doit s’assurer de rétablir sa valeur originale avant de quitter le test. Pour le faire, on doit s’assurer de copier sa valeur originale au début du test.
Pour le Scanner local, ces étapes sont éliminées, mais on doit s’assurer de passer le Scanner comme argument à la méthode à tester.
Exemple avec un Scanner global
Si on a la méthode getNameUsingGlobalScanner dans la classe Calculator :
import java.util.Scanner;
class Calculator {
/** Scanner global pour toutes les méthodes de la classe */
Scanner console = new Scanner(System.in);
// ... reste du code de la classe
String getNameUsingGlobalScanner() {
System.out.print("Entrez votre prénom > ");
String name = console.next(); // utilise le Scanner global
console.nextLine(); // jeter tout après le premier mot
return name;
}
}
On peut écrire le test unitaire testGetNameUsingGlobalScanner dans la classe CalculatorTest comme suit :
@Test
public void testGetNameUsingGlobalScanner() {
/*
* Cas de test pour String getName() qui utilise un
* Scanner déclaré globalement
*
* Descr. Entrée Sortie attendue
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* normal "david" "david"
* un caractère "A" "A"
* plusieurs mots "David Crowley" "David"
*/
/* PRÉPARATION */
// garder une référence au Scanner original de calc
Scanner original = calc.console;
// définir les cas de test
String testInput = "david\n" +
"A\n" +
"David Crowley\n"; // les \n sont les `Entrée` de l'utilisateur
// créer une source d'entrées qui contient nos cas de tests
InputStream testStream = new ByteArrayInputStream(testInput.getBytes());
// passer la nouvelle source d'entrées au Scanner de calc
calc.console = new Scanner(testStream);
/* TESTS */
assertEquals("david", calc.getNameUsingGlobalScanner());
assertEquals("A", calc.getNameUsingGlobalScanner());
assertEquals("David", calc.getNameUsingGlobalScanner());
/* NETTOYAGE */
// rediriger le Scanner global de calc à lire sa source originale
calc.console = original;
}
Note : avec l’ajout des InputStream et du Scanner, on doit ajouter import java.io.*; et import java.util.*; au début du fichier de test, p. ex. :
import static org.junit.Assert.*;
import java.io.*; // ici
import java.util.*; // et ici
import org.junit.Test;
public class CalculatorTest {
// ... reste du code de la classe
}
Si on oublie, parfois les outils d’autocomplétion dans VS Code peuvent ajouter ces déclarations automatiquement, mais c’est quelque chose à vérifier si vous avez des messages d’erreurs sur ces variables.
Exemple avec un Scanner local (passé en argument)
Une autre façon d’utiliser un Scanner dans un programme est de le déclarer localement, par exemple avec la méthode getName dans la classe Calculator :
import java.util.Scanner;
class Calculator {
String getName(Scanner in) {
System.out.print("Entrez votre prénom > ");
String name = in.next(); // fait référence au Scanner passé en paramètre
in.nextLine(); // jeter tout après le premier mot
return name;
}
void main() {
Scanner console = new Scanner(System.in); // déclarer un Scanner local
//... autre code
String name = getName(console); // passer le Scanner local comme argument
//... autre code
}
}
Le test unitaire testGetName dans CalculatorTest serait alors :
@Test
public void testGetName() {
/*
* Cas de test pour String getName(Scanner)
*
* Descr. Entrée Sortie attendue
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* normal "david" "david"
* un caractère "A" "A"
* plusieurs mots "David Crowley" "David"
*/
/* PRÉPARATION */
// définir les cas de test
String testInput = "david\n" +
"A\n" +
"David Crowley\n"; // les \n sont les `Entrée` de l'utilisateur
// créer un Scanner qui lit nos entrées de test au lieu de l'entrée standard
InputStream testStream = new ByteArrayInputStream(testInput.getBytes());
Scanner testScanner = new Scanner(testStream);
/* TESTS */
assertEquals("david", calc.getName(testScanner));
assertEquals("A", calc.getName(testScanner));
assertEquals("David", calc.getName(testScanner));
/* NETTOYAGE */
// Le nouveau Scanner est détruit automatiquement à la fin de cette méthode
}
Note : avec l’ajout des InputStream et du Scanner, on doit ajouter import java.io.*; et import java.util.*; au début du fichier de test, p. ex. :
import static org.junit.Assert.*;
import java.io.*; // ici
import java.util.*; // et ici
import org.junit.Test;
public class CalculatorTest {
// ... reste du code de la classe
}
Si on oublie, parfois les outils d’autocomplétion dans VS Code peuvent ajouter ces déclarations automatiquement, mais c’est quelque chose à vérifier si vous avez des messages d’erreurs sur ces variables.
Test de sortie
Les tests de sortie sont utiles pour les méthodes void qui passent leurs résultats à la console. On peut utiliser la redirection de la sortie standard pour capturer les messages affichés par la méthode et les comparer avec les messages attendus.
Exemple de redirection de System.out pour les tests
Considérant la méthode sayName dans la classe Calculator :
void sayName(String name) {
System.out.println("Bonjour " + name);
}
On peut écrire le test unitaire testSayName dans la classe CalculatorTest comme suit :
@Test
public void testSayName() {
/*
* Cas de test pour void sayName(String)
*
* Descr. Entrée Sortie attendue
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* normal "David" "Bonjour David"
* un caractère "A" "Bonjour A"
* plusieurs mots "David Crowley" "Bonjour David Crowley"
*
*/
/* PRÉPARATION */
// garder une référence à la sortie standard originale
PrintStream original = System.out;
// rediriger la sortie standard vers un flux de sortie temporaire
OutputStream outContent = new ByteArrayOutputStream();
System.setOut(new PrintStream(outContent));
/* TESTS */
calc.sayName("David");
calc.sayName("A");
calc.sayName("David Crowley");
String expectedOutput = "Bonjour David\nBonjour A\nBonjour David Crowley\n";
assertEquals(expectedOutput, outContent.toString().replace("\r\n", "\n")); // le replace() est nécessaire sur Windows (encodage de fin de ligne différent)
/* NETTOYAGE */
// rétablir la sortie standard originale
System.setOut(original);
}
Note : on applique la méthode de traitement de texte
.replace("\r\n", "\n")sur la sortie pour s’assurer que les différents types de retour de ligne ne causent pas un échec de la comparaison. Windows utilise\r\npour le retour de ligne, alors que Linux, MacOS et nos propres instructions Java utilisent seulement\n.
Note : avec l’ajout du PrintStream et des OutputStream, on doit ajouter import java.io.*; au début du fichier de test, p. ex. :
import static org.junit.Assert.*;
import java.io.*; // ici
import org.junit.Test;
public class CalculatorTest {
// ... reste du code de la classe
}
Si on oublie, parfois les outils d’autocomplétion dans VS Code peuvent ajouter ces déclarations automatiquement, mais c’est quelque chose à vérifier si vous avez des messages d’erreurs sur ces variables.
Les exemples complets
Vous pouvez voir le code complet pour les classes Calculator et CalculatorTest dans les fichiers Calculator.java et CalculatorTest.java.
Exercices
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices
-
Créez un fichier texte nommé
Cas-de-tests.txtdans votre réprtoire de travail.- Écrivez le tableau de cas de test pour une méthode qui retourne
truesi un nombre est pair etfalsesinon. La signature de cette méthode estboolean isEven(int number). Quels sont les cas normaux? Est-ce qu’il y a des cas limites ou invalides pour cette méthode? - Écrivez le tableau de cas de test pour une méthode qui retourne une note en lettres pour une note numérique. La signature de cette méthode est
char letterGrade(double average). Les lettres sontF(moins de 50),D(50 à 59),C(60 à 69),B(70 à 79) etA(80 à 100). Quels sont les cas normaux? Quels sont les cas limites pour cette méthode, se rappelant que la moyenne est une valeur décimale (il y en a beaucoup!)? Quels sont les cas invalides?
- Écrivez le tableau de cas de test pour une méthode qui retourne
-
Voici une implémentation de la logique de la méthode
isEvendécrit dans le premier exemple.class NumberUtils { boolean isEven(int number) { return number % 2 == 0; } }- Créez une copie de ce fichier et nommez-le
NumberUtils.java. - Utilisez les outils de VS Code pour créer la classe de test et la squelette de test unitaire pour cette méthode.
- Ajoutez une déclaration globale (dans la classe
NumberUtilsTest) pour un objet NumberUtils :NumberUtils utils = new NumberUtils(); - Vous devrez traduire votre tableau de cas de test (écrit plus haut) en commentaire de bloc à l’intérieur de votre méthode de test.
- Implémenter des tests d’égalité pour cette méthode, un test par cas de test identifié. Servez vous du gabarit comme point de départ.
- Exécutez les tests.
- Prenez une capture d’écran de l’onglet “Test Results” pour montrer que vos tests ont passé. L’enregistrez comme
4-unit-test.pngdans le dossier “captures”.
- Créez une copie de ce fichier et nommez-le
-
Depuis JEP 463 (pleinement intégré aux outils Java22+) ↩
Accueil > Programmer avec Java > Structures de contrôle >
Écrire des conditions
Survol et attentes
Un programme peut prendre des décisions et, ainsi, devenir plus intelligent. Comme tout dans un ordinateur, ces décisions sont à base binaire, c’est-à-dire qu’elles sont basées sur des conditions qui sont soit vraies, soit fausses. Dans cette leçon, nous allons apprendre à écrire des conditions en Java. Nous allons aussi apprendre à utiliser des opérateurs logiques pour combiner des conditions.
Définitions
Les conditions sont utilisées pour sélectionner une branche d’instructions parmi un choix de branches. Elles sont aussi utilisées pour déterminer si une boucle doit se répéter ou se terminer. Il y a d’autres utilisations, comme décider si une méthode se termine ou non, mais toutes ces applications seront vues dans des leçons séparées.
- Condition
- une expression booléenne, soit une expression qui s’évalue à
trueoufalse. On peut penser à des conditions comme une façon formelle de poser une question oui/non à un ordinateur. boolean- type de valeur Java qui stocke la valeur
trueoufalse. On peut utiliser ce type de valeur dans des variables qui indiquent l’état de différentes choses dans le programme. - Opérateur de comparaison
- un opérateur qui compare deux valeurs et retourne un booléen. Les opérateurs de comparaison sont
==,!=,<,<=,>,>=. - Méthodes de comparaison
- des méthodes qui comparent des objets et retournent un booléen. Par exemple,
.equalspour les String et.hasNextIntpour un Scanner. - Opérateurs logiques
- des opérateurs qui combinent des conditions. Les opérateurs logiques sont
&&(ET),||(OU) et!(PAS).
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Décrire les trois types d’expressions booléennes de base : valeur booléenne, opération de comparaison et méthode de comparaison.
- Reconnaître les différents opérateurs de comparaison :
==,!=,<,<=,>et>=. - Décrire les trois opérateurs logiques :
&&,||et!.
Critères de succès
- Dans mes programmes Java, je peux écrire des expressions booléennes simples qui utilisent des valeurs booléennes, des valeurs numériques et des Strings comme base de comparaison.
Variables booléennes (type boolean)
L’expression booléenne la plus simple est une valeur littérale booléenne : soit true (vrai), soit false (faux). On peut utiliser ces valeurs littérales directement ou assignées à des variables, par exemple, boolean repeat = true;.
Une variable booléenne est pratique pour représenter l’état de quelque chose, par exemples : repeat ci-dessus qui peut indiqur s’il faut répéter une action ou non ou boolean isOn = true; qui peut représenter si une fonctionnalité est activée ou non. Ce type d’usage des valeurs booléennes s’appelle un drapeau. On peut regarder son état dans des conditions ou modifier son état dans le code, par exemple isOn = false; pour éteindre l’ampoule.
Opérations de comparaison
Un autre type d’expression booléenne est une opération de comparaison. Une opération de comparaison compare deux valeurs et retourne une valeur booléenne. Par exemple, x == y est une expression de comparaison qui retourne true si x est égal à y et false sinon. Les opérateurs de comparaison sont :
==(égal),!=(différent/pas égal),<(inférieur),<=(inférieur ou égal),>(supérieur)- et
>=(supérieur ou égal).
Voici quelques exemples à tester dans une session jshell :
5 == 5; // notez : comparer l'égalité utilise deux "=", soit "=="
5 != 5;
5 < 5;
5 <= 5;
5 > 5;
5 >= 5;
int x = 4; // notez : assigner utilise un seul "="
int y = 5;
x == y;
x != y;
x < y;
x <= y;
x > y;
x >= y;
Quel sera le résultat de la comparaison suivante? 5 >= 6
false. L’opérateur de comparaison représente “plus grand ou égale à”
Considérant les valeurs de x et y ci-dessus cette comparaison donne quoi? (x + y) < (2 * x)
false. On évalue les parenthèses en premier, donnant 9 < 8 qui est faux.
Méthodes de comparaison
Il y a aussi des méthodes de comparaison, généralement utilisées pour comparer différents objets du même type. On doit utiliser une méthode de comparaison pour comparer des objets de type String. Par exemple, "abc".equals("abc") retourne true et "abc".equals("def") retourne false. Il y a quatre méthodes de comparaison pour les String :
equals(égal), par exemple"abc".equals("abc")equalsIgnoreCase(égal, sans tenir compte de la casse), par exemple"abc".equalsIgnoreCase("ABC")retournetruecompareTo(inférieur, égal ou supérieur), qui retourne une valeur négative si la première valeur est inférieur, zéro si les deux valeurs sont égales et une valeur positive si la première valeur est supérieure. Par exemple"abc".compareTo("def")retourne une valeur négative (-3).compareToIgnoreCase(inférieur, égal ou supérieur, sans tenir compte de la casse)
La raison pourquoi la comparaison directe d’objets comme des String ne fonctionne pas est expliquée dans le cours ICS4U. C’est en lien avec la représentation de ces valeurs en mémoire versus la façon dont les valeurs primitives (comme des
int) sont représentées en mémoire.
Voici quelques exemples de comparaisons de String à tester dans une session jshell :
"abc".equals("abc");
"abc".equals("def");
"abc".equals("ABC");
"abc".equalsIgnoreCase("ABC");
"abc".compareTo("def"); // donne un chiffre
"abc".compareTo("def") == 0; // tester l'égalité (donne un booléen)
"abc".compareTo("def") < 0; // tester si "abc" est inférieur à "def"
"abc".compareTo("def") > 0; // tester si "abc" est supérieur à "def"
// La comparaison se fait à la base de la valeur Unicode des caractères
// et les majuscules sont AVANT les minuscules dans la table Unicode
"abc".compareTo("ABC"); // donne un chiffre positif
"abc".compareTo("ABC") > 0; // tester la supériorité (donne un booléen)
"abc".compareToIgnoreCase("ABC"); // donne un chiffre
"abc".compareToIgnoreCase("ABC") == 0; // tester l'égalité (donne un booléen)
Notez que pour utiliser les méthodes compareTo comme conditions, il faut utiliser le chiffre retourné par la méthode dans une expression de comparaison afin d’obtenir un résultat true ou false.
Quelle lettre est plus "grande" du point de vu d'un ordinateur, 'a' ou 'A'?
C’est 'a'! Sa valeur ASCII de 97 est 32 de plus que la valeur ASCII de 'A' (65). Et oui, les minuscules sont “plus grandes que” les majuscules dans le tableau ASCII.
Quel est le résultat de "oui"e.equals("Oui") ?
false. Les minuscules et les majuscules sont des caractères distinctes pour un ordinateur.
Quel est le résultat de "oui".equalsIgnoreCase("Oui") ?
true. La méthode spéciale .equalsIgnoreCase ignore les différences de case des lettres.
Opérateurs logiques - combiner des conditions
On peut combiner le résultat d’expressions booléennes avec les opérateurs logiques ET (&&) et OU (||). On peut aussi inverser le résultat d’une expression booléenne en le précédant avec l’opérateur PAS (!).
Comme avec d’autres opérateurs, il y a un ordre de priorité. L’opérateur PAS a la priorité la plus élevée, suivi de ET et, finalement, OU. On peut utiliser des parenthèses pour changer l’ordre d’évaluation.
Voici quelques exemples à tester dans une session jshell :
// exemples pour voir les opérateurs
true && true; // ET
true && false;
false && true;
false && false;
false || true; // OU
!true; // PAS
!false;
!true && true;
!(true && true); // effet des parenthèses
// exemples plus réalistes
int x = 5;
(x > 0) && (x < 10); // entre 0 et 10
(x < 0) || (x > 10); // en dehors de 0 à 10
// déterminer si je mange au restaurant utilisant deux variables booléennes
amHungry && restaurantOpen;
// l'équivalent de != pour la méthode de comparaison .equals()
!"abc".equals("def");
Quel est le résultat de l'opération !true ?
false. ! est l’opérateur “non” ou “inverse”, donnant toujours le contraire de la valeur qui le suit.
Quel est le résultat de l'opération "false || false || false || true" ?
- tldr;
true. L’opérateur||signifie “ou”. Seulement une valeur dans la chaîne doit être vraie pour que tout soit vrai.- détails de l’évaluation
- Parce que toutes les opérations sont les mêmes (
||) l’évaluation progresse simplement de gauche à droite donnant :(false) || false || trueensuite(false) || trueet finalement(true).
Quel est le résultat de l'opération "!false && false && true || false" sachant que l'ordre des opérations est : ! avant && avant || ?
false. L’opérateur && signifie “et” et donne vrai seulement si les deux valeurs sont vraies.
Voici l’ordre d’évaluation de l’expression :
!falsedevienttrue- Parce que
&&précède||, on continue avec le premier&&:(true) && falsequi donnefalse - Le deuxième
&&:(false) && truequi donne encorefalse - Finalement le
||(ou) :(false) || falsedonne aussifalse.
Exercices
📚 Tester la compréhension
Répondre aux questions insérées dans les notes après les exemples.
🛠️ Pratique
A. Exemples à développer
Écrire des conditions appropriées pour donner true dans les situations suivantes. Utilisez des noms de variables appropriées si la valeur n’est pas fournie explicitement.
- Le choix de l’utilisateur est
"a"(String). - Le choix de l’utilisateur est
'a'(char). Indice 1 : on peut obtenir le premier caractère d’une réponse (p. ex.:pick) avecpick.charAt(0).Indice 2 : uncharest un type primitif commeint. - Il est tard mais je ne suis pas fatigué. Utilisez l’opérateur
!dans l’expression. - Le nombre de points est plus grand que
21. - Le nombre de vies est moins que
1. - Je suis en vie et j’ai l’objet magique et j’ai battu le grand boss.
- Je veux écouter un texte de méditation et le son des vagues mais pas le son des oiseaux.
B. Problèmes de logique sur le site CodingBat (Enrichissement)
Démarrer sur ce site
Codinbat est un site qui offre des problèmes de logique à résoudre avec Java ou Python. C’est donc excellent pour pratiquer les conditions.
- Vous rendre sur le site codingbat.com/java
- En haut à droite, cliquer le lien pour créez un compte. Utiliser un courriel de votre choix et un mot de passe. Votre courriel est votre nom d’utilisateur et sert à la récupération du mot de passe. Aucune autre information personnelle n’est requise.
- Dans la section
prefssous “Teacher Share” ajoutez mon adresse courriel. Vous pouvez le trouver dans le Classroom ou dans votre Gmail de l’école dans la liste des contacts. Je pourrai alors voir vos progrès. - Pour traduire la page, utilisez les outils de Chrome. MISE EN GARDE : à utiliser seulement pour comprendre la description du problème car la traduction affecte aussi le code de démarrage, brisant la syntaxe Java. Assurez-vous de changer la langue de traduction à “English” après avoir lu la description.
Astuces pour travailler dans CodingBat :
- Votre solution pour chaque problème est une valeur de retour du type spécifié dans l’explication du problème et dans la signature de la méthode. Ça prend alors toujours une expression avec
returndans votre code. - Les entrées de chaque problème sont les paramètres de la méthode et sont déjà déclarés pour vous. Vous devez utiliser ces paramètres dans vos conditions et autres opérations.
- Vous testez votre solution en cliquant sur le bouton
Goaprès avoir écrit votre code. Plusieurs cas de tests seront exécutés pour vérifier si votre solution est correcte et vous verrez exactement quels cas ont été réussis et lesquels ont échoués. Vous pouvez tester votre solution autant de fois que vous voulez. - Chaque problème dans cette séquence initiale de problèmes inclut une solution que vous pouvez consulter. Après les premiers problèmes, le bouton pour la solution est seulement accessible après avoir essayé le problème une fois.
- Il y a des tutoriels accessible via des liens au bas de la page qui expliquent certaines des caractéristiques des données (String, tableaux, dictionnaires) et des méthodes communes pour les utiliser dans ces problèmes. Les tutoriels sur les String seront particulièrement utiles avec les problèmes de démarrage.
Exercices avec les conditions
C’est fort possible que vous ayez de la difficulté avec plusieurs de ces casse-têtes. C’est normal! Si vous avez de la difficulté, essayez de comprendre la solution fournie et de la réécrire vous-même. Le but est de vous familiariser avec les conditions et les opérateurs logiques afin que vous puissiez les utiliser dans des contextes de votre choix pas dans le contexte de problèmes de logique.
- Faire les problèmes suivants : les solutions à ces problèmes utilisent uniquement des comparaisons et des opérateurs de logique (
&&,||,!), en plus de quelques opérations mathématiques ou sur les String à l’occasion. Les problèmes à tenter sont dans la section Warmup-1 :- sleepIn
- monkeyTrouble
- makes10
- nearHundred (utilise aussi la méthode
Math.abs) - missingChar (utilise aussi la méthode
substring) - backAround (utilise aussi les méthodes
charAtetsubstring) - or35 (utilise l’opérateur modulo
%pour trouver le reste de la division par 3 ou 5) - startHi (attention! la condition est assez complexe ici; utilise les méthodes
lengthetsubstring) - icyHot (utilise aussi les méthodes
Math.minetMath.max) - in1020
- hasTeen (la condition est longue ici, avec plusieurs opérateurs logiques)
- mixStart (utilise aussi les méthodes
length,substringetequals) - lastDigit (utilise aussi l’opérateur modulo
%pour trouver le reste de la division par 10)
Certaines solutions officielles à ces problèmes utilisent la sélection avec
ifetelsepour résoudre les problèmes, mais si le problème est dans la liste ci-dessus, vous êtes capable de remplacer cet embranchement en utilisant les opérateurs logiques ET&&et OU||pour produire une seule expression équivalente.
Accueil > Programmer avec Java > Structures de contrôle >
📚 Sélection
Survol et attentes
La sélection est un concept fondamental de la programmation. Elle permet au programme d’adapter son comportement selon l’état de différentes conditions. Bref, le programme devient plus intelligent. Dans cette leçon, nous allons voir comment utiliser la sélection en Java.
Définitions
- Séléction
- concept de programmation qui permet d’exécuter du code seulement si une condition est vraie. Cela crée plusieurs embranchements dans le code au lieu d’une seule séquence.
ifetelse- mots-clés utilisés pour la sélection en Java. Le bloc
ifdéclare une condition et exécute son code si cette condition est vraie. Le blocelsesuit un bloc if et exécute son code seulement si la condition duifétait fausse. - Losange
- forme utilisée pour représenter une condition dans un diagramme de flux. Son étiquette représente une question avec une réponse oui/non ou
true/false, et il y a deux flèches qui quittent le bloc, une pour chaque réponse possible. Cela donne la représentation visuelle claire de l’embranchement.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Reconnaître la syntaxe de la sélection en Java avec les blocs
if,else ifetelse. - Lire et produire des diagrammes de flux incorporant des conditions et de l’embranchement.
Critères de succès
- Je peux appliquer les conditions à différentes situations de sélection dans mes programmes Java.
- Je peux créer une cascade de conditions mutuellement exclusives.
- Je peux créer une suite de conditions indépendantes.
Sélection conditionnelle avec if et else
La sélection permet d’exécuter du code seulement si une condition est vraie. La condition est n’importe quelle expression booléenne, soit une expression qui s’évalue à true ou false :
if (condition) {
// code à exécuter si la condition est vraie
}
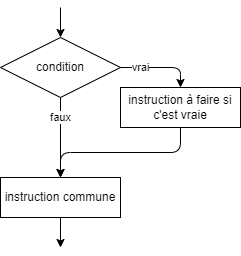
On a aussi l’option d’exécuter du code si la condition est fausse en ajoutant un bloc else immédiatement après le bloc if :
if (condition) {
// code à exécuter si la condition est vraie
} else {
// code à exécuter si la condition est fausse
}
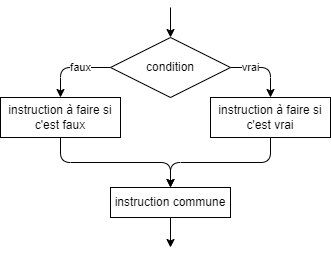
Plusieurs cas exclusifs avec else if
Si on a plusieurs cas exclusifs (des cas où seulement un cas peut être est vrai) à vérifier, on peut immédiatement déclarer un bloc if suivant le mot-clé else afin de poser la prochaine condition :
if (condition1) {
// code à exécuter si la condition1 est vraie
} else if (condition2) {
// code à exécuter si la condition2 est vraie
} else if (condition3) {
// code à exécuter si la condition3 est vraie
} else {
// code à exécuter si aucune des conditions précédentes n'est vraie
}
Chaque else représente ce qui se passe si le if précédant est faux. On peut enchaîner autant de blocs else if que nécessaire. Le bloc else final est optionnel, mais est souvent utile pour définir un cas par défaut, comme un message d’erreur.
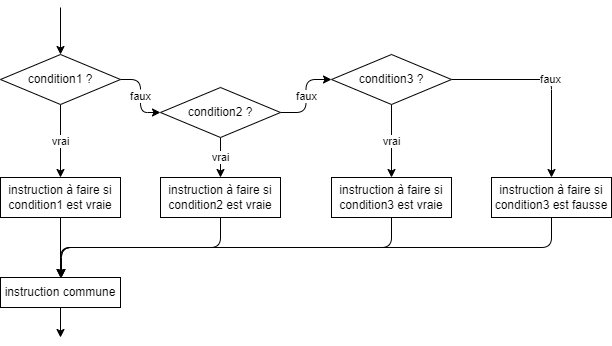
Cette façon d’enchaîner les conditions assure que seulement un bloc sera exécuté. Il faut donc faire attention de bien écrire les conditions afin de représenter tous les cas possibles et de ne pas en oublier. C’est un bon exemple de situation où faire des tests pour chaque cas, notamment les cas limites, est important.
Voici un exemple de code qui utilise plusieurs cas exclusifs dans le fichier LinkedConditions.java :
import java.util.*;
void main() {
Scanner console = new Scanner(System.in);
System.out.println("Quel est votre âge? ");
int age = console.nextInt();
if (age < 4) {
System.out.println("Enfant préscolaire");
} else if (age <= 11) {
System.out.println("Enfant d'école élémentaire");
} else if (age <= 14) {
System.out.println("Adolescent d'école intermédiaire.");
} else if (age <= 18) {
System.out.println("Adolescent d'école secondaire.");
} else {
System.out.println("Adulte.");
}
}
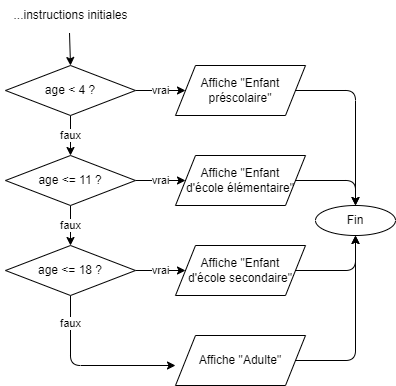
Quelle sera la sortie si l'utilisateur saisit la valeur 8?
À part l’invite de réponse, ce sera :
Enfant d'école élémentaire
La variable age prendra la valeur 8, donc la première condition (age < 4) sera fausse. On passe donc au else qui le suit qui déclare immédiatement une autre condition (age <= 11) qui est vraie. On entre alors dans ce bloc de code et affiche son message.
C'est quoi le diagramme de séquence d'exécution (suite des numéros de lignes exécutées) si l'utilisateur saisit la valeur 17?
On fait les 6 premières lignes en séquence pour ensuite arriver à ceci :
...
6
7
8
10
12
14
15
16
19
- Notez surtout qu’on saute des lignes (les lignes 9, 11, et 13) : celles qui correspondent aux autres branches avec des conditions fausses
- Notez aussi qu’on doit évaluer chacune de ces conditions (les lignes 8, 10 et 12) pour savoir sur quelle branche continuer (le côté
falsedans ce cas) … - Jusqu’à ce qu’on passe par le côté
trued’une branche (la ligne 15). Son bloc se termine avec l’accolade fermante à la ligne 16 mais le reste de cette ligne et de la “cascade” est ignorée. - Le code se termine avec l’accolade fermante de
main.
Plusieurs cas indépendants
Si on a plusieurs cas indépendants (des cas où plusieurs cas peuvent être vrais), on peut utiliser plusieurs blocs if :
if (condition1) {
// code à exécuter si la condition1 est vraie
}
if (condition2) {
// code à exécuter si la condition2 est vraie
}
if (condition3) {
// code à exécuter si la condition3 est vraie
}
Chaque bloc if est indépendant des autres et un, plusieurs ou aucun bloc if peut être exécuté selon les conditions.
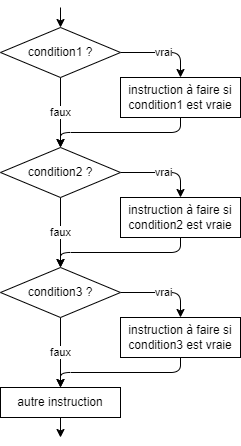
Voici un exemple de code qui utilise plusieurs cas indépendants dans le fichier IndependantConditions.java :
String input(String prompt) {
System.out.print(prompt + " > ");
return System.console().readLine();
// plus simple mais moins puissante qu'un Scanner
}
void main() {
String favColour = input("Couleur préférée");
String favSeason = input("Saison préférée");
int favNumber = Integer.parseInt(input("Nombre entier préférée"));
// on converti le String en int dans une 2ème opération
if (favColour.equals("bleu")) {
System.out.println("Le bleu est ma couleur préférée aussi!");
}
if (favSeason.equals("été")) {
System.out.println("L'été est ma saison préférée aussi!");
}
if (favNumber == 7) {
System.out.println("7 est mon nombre préféré aussi!");
}
}
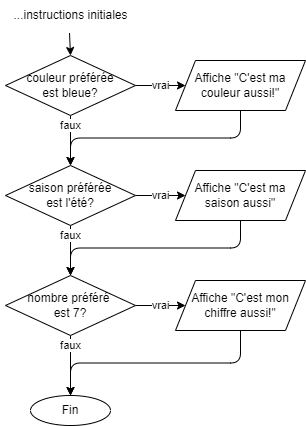
Si la condition est vraie à la ligne 13 (comparer les couleurs) est-ce qu'on continue avec les lignes de 16 à 20 ou est-ce qu'on les ignore?
On les fait quand même! Si le premier if est vrai ou faux on passe sur ces lignes tout de même parce qu’elles ne sont pas sur une branche else.
Exercices
📚 Tester la compréhension
Répondre aux questions insérées dans les notes après les exemples.
🛠️ Pratique
A. Exemples à développer
Structure du fichier et code de démarrage dans un nouveau fichier :
Selection.java
import java.util.*;
final Scanner IN = new Scanner(System.in);
void calc() {
// #1 : à développer
}
void dice() {
// #2 : à développer
}
void main() {
// appeler les autres méthodes pour les tester
}
-
calc(): Demander deux valeurs de typedoubleà l’utilisateur. Ensuite lui demander quelle opération qu’elle veut faire ("+","-","*", ou"/"). Utiliser la sélection (if,else ifetelse) pour afficher le résultat du calcul approprié.- Bonus : si l’utilisateur choisit
"/"faire une sélection additionnelle (if) pour vérifier si le deuxième nombre est0et afficher un message d’erreur au lieu de faire le calcul.
- Bonus : si l’utilisateur choisit
-
dice(): Utiliser l’opération(int)(Math.random() * 6 + 1)pour générer des valeurs aléatoires entre1et6(les valeurs d’une dé). Stocker trois de ces valeurs dans des variables de typeint.- Utiliser la sélection pour vérifier si chaque valeur individeulle est un
6(3if). Pour chaque dé, afficher un message dans ce cas, mais ne faites rien dans le cas contraire. - Ensuite, utiliser une seule sélection pour voir si un nombre se répète (deux valeurs sont identiques) au moins une fois (1
ifavec opérations logiques) et afficher un message approprié dans ce cas. - Finalement, vérifier si les trois valeurs sont identiques (1
ifavec opérations logiques) et afficher un message approprié dans ce cas.
- Utiliser la sélection pour vérifier si chaque valeur individeulle est un
B. Problèmes de logique sur le site CodingBat (Enrichissement)
Comme avec la leçon précédente, c’est fort possible que vous ayez de la difficulté avec plusieurs de ces casse-têtes. Si un problème vous cause trop d’ennuis, vous pouvez passer à un autre. Il y en a beaucoup! Rappelez-vous que le but est de vous familiariser avec la sélection if-else afin que vous puissiez l’utiliser dans des contextes de votre choix pas dans le contexte de problèmes de logique.
- Tenter le reste des problèmes de Warmup-1. Ces autres problèmes utilisent des conditions et opérateurs logiques comme la liste précédente mais doivent aussi utiliser la sélection avec
ifetelse. Les problèmes sont :- sumDouble
- diff21
- parrotTrouble
- posNeg
- notString
- frontBack
- front3
- front22
- loneTeen
- delDel
- startOz
- intMax
- close10
- in3050
- max1020
- stringE
- endUp
Le problème “everyNth” utilise aussi une boucle, ce qui sera vue dans la prochaine leçon.
Accueil > Programmer avec Java > Structures de contrôle >
📚 Boucles
Survol et attentes
Définitions
La répétition conditionnelle d’un bloc de code est un autre concept fondamental de la programmation. Elle permet aux programmes de devenir puissants en profitant de la vitesse d’exécution de l’ordinateur et prévient la répétition de code.
La boucle while est la plus polyvalente et peut servir à tous les contextes. La boucle for est plus spécialisée et est utilisée pour traiter une suite de nombres.
- boucle
- une structure de contrôle qui répète un bloc de code tant qu’une condition est vraie.
itération une seule exécution du bloc de code dans une boucle.
- mécanisme de mise à jour
- combinaison de variables et d’instructions qui ont l’objectif d’amener la condition de la boucle à
falseet prévenir les boucles infinies. - variable de contrôle
- une variable qui est utilisée pour contrôler la condition de la boucle.
- variable accumulateur
- variable qu’on déclare avant une boucle qui collecte des valeurs pendant les itérations de la boucle, comme une somme ou une liste de noms.
- drapeau booléen
- une variable booléenne utilisé pour représenter l’état de quelque chose. Dans ce contexte, un drapeau booléen peut remplacer la condition de la boucle et sa valeur peut être modifiée à l’intérieur du bloc de code.
break- mot-clé Java qui force la sortie d’une boucle, peu importe la condition ou la position dans le bloc de code.
continue- mot-clé Java qui force la boucle à passer à l’itération suivante, ignorant toutes les instructions restantes dans le bloc de code.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Décrire le rôle des trois éléments d’une boucle : condition, bloc de code, mise à jour.
- Décrire trois façons de formuler la condition d’une boucle : avec une variable de contrôle, avec une variable booléenne, avec la constante
true - Expliquer comment utiliser le mot-clé
breakpour sortir d’une boucle.
Critères de succès
- Je peux écrire différentes structures de boucles selon le contexte du problème.
- Je peux utiliser des variables booléennes pour éviter la répétition du code nécessaire pour valider une condition.
Boucle while
Voici la syntaxe de base pour une boucle while :
while (condition) {
// bloc de code
// mécanisme de mise à jour
}
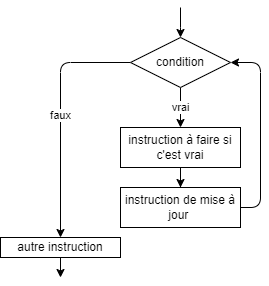
C’est important de noter que l’exécution des instructions ne continue pas après le bloc de code mais revient à la condition. C’est ça qui forme la boucle. Si la condition est true, le bloc de code est répété. Si la condition est false, l’exécution continue après la boucle. Ici, le diagramme de flux donne une meilleure représentation de l’exécution réelle de étapes.
Exemple : Traiter une suite de nombres
Pour traiter une suite de nombres, on définit d’abord une variable de contrôle qui représente la valeur initiale de la suite. Ensuite, on définit la condition de la boucle en fonction de cette variable de contrôle. Finalement, on met à jour la variable de contrôle à l’intérieur du bloc de code.
Placez le code suivant dans un fichier qui s’appelle
LoopExamples1.javaet exécutez-le pour voir les résultats.
Par exemple, pour afficher les nombres de 1 à 10 :
Avec while
void whileLoop() {
int i = 1; // initialiser la variable de contrôle
while (i <= 10) { // condition utilisant la variable de contrôle
System.out.println(i);
i++; // mise à jour de la variable de contrôle (incrémenter)
}
}
void main() {
whileLoop();
}
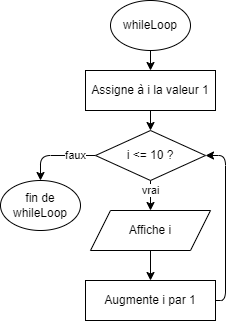
L'exécution du code précédent commence à quelle ligne?
La ligne 9, à la signature de main. La ligne 10 envoie ensuite l’exécution à la ligne 1 en appelant whileLoop().
Combien de fois est-ce que la ligne 2 sera-t-elle exécutée?
Une seule fois. Elle vient juste avant le début de la déclaration while.
Combien de fois est-ce que la ligne 4 sera-t-elle exécutée?
Dix fois : une pour chaque valeur de i qui donne un résultat true à i <= 10
Combien de fois est-ce que la ligne 3 sera-t-elle exécutée?
11 fois! Oui, on doit aussi visiter la condition pour la fois que la condition est fausse, quand i est égale à 11, brisant la boucle. La condition est donc évaluée une fois de plus que le nombre d’itération.
Quelle sera la sortie du code précédant?
La sortie est :
1
2
3
4
5
6
7
8
9
10
Avec for
La boucle for est spécialisée pour ce type de tâche. Elle inclut les trois éléments clés de la boucle directement dans sa déclaration. Sa syntaxe est la suivante :
for (initialisation; condition; mise à jour) {
// bloc de code
}
Par exemple, pour afficher les nombres de 1 à 10 avec une boucle for :
void forLoop() {
for (int i = 1; i <= 10; i++) { // les trois éléments séparés par des ;
System.out.println(i);
}
}
Si on appelle aussi cette méthode dans main, on aura exactement la même sortie qu’avec la version while. Ajoutez-le à votre fichier LoopExamples1.java pour le vérifier.
Défi
Pouvez vous trouver et afficher la somme de toutes les valeurs de 1 à 10 en modifiant une des boucles ci-dessus?
Indice : vous aurez besoin d’une variable accumulateur en plus de la variable de contrôle.
Exemple : Valider des données d’entrée
Un autre contexte pour une boucle est demander une réponse à l’utilisateur tant que la réponse n’est pas valide.
Une situation typique est lorsqu’on demande une confirmation oui/non à l’utilisateur. On peut utiliser une boucle while pour s’assurer que la réponse est valide.
Voici deux façons de le faire. Il en existe d’autres! Vous pouvez tester ces méthodes dans un nouveau fichier LoopExamples2.java.
Avec une variable de contrôle pour la condition de la boucle
import java.util.*;
final Scanner INPUT = new Scanner(System.in);
String again() {
String answer = ""; // variable : contrôle ET accumulateur
while (!(answer.equals("oui") || answer.equals("non"))) {
System.out.print("Voulez-vous continuer? (oui/non) > ");
answer = INPUT.next().toLowerCase();
// mise à jour avec une réponse en minuscules
}
return answer;
}
void main() {
while (again().equals("oui")) {
// code à répéter
}
System.out.println("Au revoir");
}
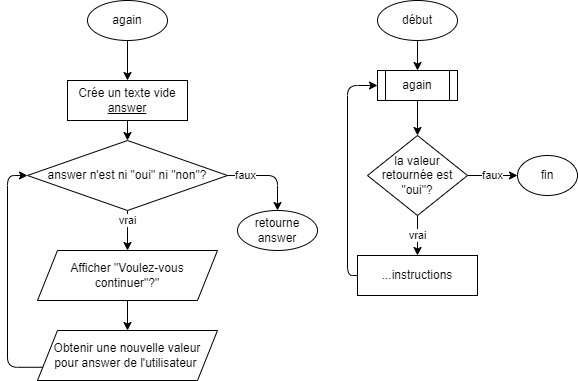
Il y a deux conditions dans ce code.
Le plus complexe est dans again() : !(answer.equals("oui") || answer.equals("non")) :
- Le
!au début indique qu’on veut inverser le résultat entre les parenthèses - c’est parce que ce qu’on décrit entre parenthèses correspond à ce que nous voulons, mais la boucle devrait se répéter dans le cas contraire - Le
||est l’opérateur “ou” qui sera vrai si l’une ou l’autre des conditions est vraie. - On utilise
.equals()pour comparer l’égalité parce qu’on compare deuxString.
Plaçant tout ça ensemble avec le mot-clé while, on devrait lire :
si la réponse EST "oui" OU "non", NE PAS répéter le bloc de code
La deuxième condition est dans main : again().equals("oui") :
againretourne un String au programme qui est directement utilisé dans la comparaison
Voici un exemple d’interaction avec l’utilisateur pour ce programme :
Voulez-vous continuer? (oui/non) > peut-être
Voulez-vous continuer? (oui/non) > n
Voulez-vous continuer? (oui/non) > Non
Au revoir
Combien des fois est-que la condition de la boucle dans la méthode again() est-elle évaluée durant l'intéraction ci-dessus?
4 fois : une au début avec la valeur initiale de "" et une pour chaque réponse de l’utilisateur
Pourquoi est-ce que la réponse "Non" a-t-elle été acceptée?
INPUT.next() nous donne "Non" ce qui ne serait pas equals à "non". Mais ce n’est pas ce qui se rend à la condition : on passe la réponse brute à la méthode toLowerCase() qui convertit tout en minuscules. Ainsi, answer contient la valeur "non" ce qui permet à la condition d’être vraie.
Défi
La condition pour évaluer si la réponse était invalide (alors répéter la boucle) est la suivante :
!(answer.equals("oui") || answer.equals("non")) = si la réponse EST "oui" OU "non", NE PAS répéter le bloc de code
On peut écrire cette même condition d’une autre façon.
Quelle condition serait équivalente à "répéter la boucle si la réponse n'EST PAS "oui" ET la réponse n'EST PAS "non"?
!answer.equals("oui") && !answer.equals("non")
Exemple : Répéter un programme jusqu’à ce que l’utilisateur décide de le quitter
Un autre contexte commun est une boucle de programme intentionellement infinie. Pour ces cas, la déclaration de la boucle est while (true). C’est ce qui se passe avec les fenêtres de vos applications : l’affichage est rafraîchi en permanence jusqu’à ce que vous fermiez la fenêtre.
Mais comment quitter une boucle où la condition de boucle est une constante? Réponse : on utilise une instruction break à l’intérieur du bloc de code. L’instruction break est insérée dans une sélection qui évalue si la condition de sortie est atteinte.
while (true) { // passe tout droit
// bloc de code
if (condition) {
break; // sortie de la boucle
}
}
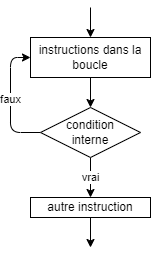
Notez que dans le diagramme pour une boucle while (true) la condition de boucle se trouve à l’intérieur et parfois à la fin des instructions de la boucle. Le “while (true)” n’est pas représenté directement parce que ça n’affecte pas le flux des étapes.
Notez que le mot-clé
whilen’apparaît jamais dans ces diagrammes, ni les autres mot-clés (p. ex.:if,else,true,break). Il s’agit simplement de conditions et d’embranchements dans les diagrammes. Dans les divers cas d’itération, une des branches forme une boucle. Sinon on parle de sélection / d’embranchement tout court.
Retour sur la validation de données
On pourrait remplacer la version de main dans LoopExamples2.java avec la version suivante :
void main() {
while (true) {
// code de la tâche
// code pour demander à l'utilisateur s'il veut continuer
if (again().equals("non")) {
break; // sortie de la boucle
} else {
// code pour réinitialiser les variables de la tâche
}
}
}
Pour d’autres tâches
Un autre exemple est pour faire la somme d’une série de nombres. On demande à l’utilisateur d’entrer un nombre à la fois. Si le nombre est -999, on quitte la boucle. Sinon, on ajoute le nombre à la somme.
Reprendre cet exemple dans un nouveau fichier LoopExamples3.java.
import java.util.*;
void main() {
Scanner input = new Scanner(System.in);
int sum = 0; // variable accumulateur
while (true) {
System.out.print(
"Entrez un nombre entier (-999 pour quitter) : "
);
int num = input.nextInt(); // variable de contrôle
if (num == -999) {
break; // mot-clé pour quitter la boucle
} else {
sum += num;
}
}
System.out.println("La somme est " + sum);
}
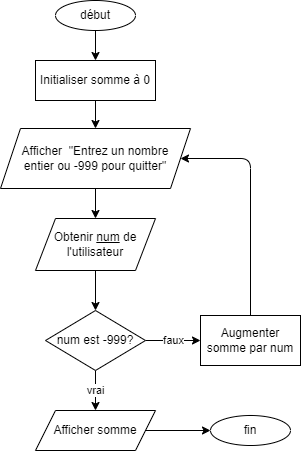
Et voici deux exemples d’interaction avec l’utilisateur :
Entrez un nombre entier (-999 pour quitter) : 5
Entrez un nombre entier (-999 pour quitter) : 10
Entrez un nombre entier (-999 pour quitter) : 15
Entrez un nombre entier (-999 pour quitter) : -999
La somme est 30
Entrez un nombre entier (-999 pour quitter) : -3
Entrez un nombre entier (-999 pour quitter) : 0
Entrez un nombre entier (-999 pour quitter) : 3
Entrez un nombre entier (-999 pour quitter) : 6
Entrez un nombre entier (-999 pour quitter) : -999
La somme est 6
Exercices
Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices.
Contexte
Voici un autre exemple qui nous donne la partie entière du logarithme d’une valeur x en base 2. On divise x jusqu’à ce que sa valeur soit inférieure à 1. Le nombre de divisions est le logarithme de x en base 2.
int x = 1024; // valeur à traiter; aussi la variable de contrôle
System.out.print("Le log2 de " + x + " est ");
int divCounter = 0;
while (x > 1) { // condition
divCounter++;
x = x/2; // mise à jour (divise par 2)
}
System.out.println(divCounter);
et sa sortie:
Le log2 de 1024 est 10
Problème à résoudre
Écrire une boucle while (ou for) qui utilise une mise à jour autre que l’incrémentation. Par exemple, on peut utiliser une décrémentation, une multiplication ou une division, ou n’importe quel calcul que vous souhaitez en autant que la variable de contrôle se rapproche de la condition false à chaque itération. L’exemple précédant pour le logarithme utilise une division.
Accueil > Programmer avec Java >
Gérer les exceptions avec try et catch
Survol et attentes
Définitions
- Entrée invalide
- une entrée qui ne correspond pas à une gamme de valeurs acceptables.
- Exception
- un événement imprévu qui cause le plantage d’un programme s’il n’est pas géré. Java inclut une classe
Exceptionqui permet de gérer ces événements en fournissant des informations sur l’erreur qui s’est produite. tryetcatch- blocs de code utilisés pour gérer les exceptions en Java. Le bloc
trycontient le code qui pourrait générer une exception, et le bloccatchcontient le code qui gère l’exception si elle se produit. throws- un mot-clé utilisé dans la signature d’une méthode pour indiquer qu’elle utilise du code qui peut générer une exception et ne le gère pas. La méthode passe ainsi la responsabilité de gérer l’exception à la méthode appelante.
- Responsabilité unique
- principe de conception de logiciel qui stipule qu’une classe ou une méthode devrait être responsable d’une seule tâche.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Identifier les exceptions les plus communes en Java.
- Savoir qu’elles entrées peuvent causer des exceptions et les distinguer de celles qui sont invalides pour d’autres raisons.
- Comprendre la structure d’un bloc
tryetcatchpour gérer les exceptions.
Critères de succès
- Je peux gérer des cas qui causeraient autrement un plantage du programme en utilisant des blocs
tryetcatch.
Responsabilité unique
En génie logicielle, il y a un principe qui s’appelle la responsabilité unique. Ce principe nous dit que chaque méthode doit être responsable d’une seule chose. C’est une des raisons pourquoi nous brisons nos algorithmes en méthodes plus petites : cela limite la responsabilité de main à l’organisation globale des opérations et permet à chaque méthode d’avoir un objectif clair.
Si on utilise du code qui peut générer une exception, on a deux choix :
- ajouter une déclaration
throws Exceptionà la signature de la méthode pour passer la gestion de l’exception à la méthode appelante, ou - utiliser un bloc
tryetcatchpour gérer l’exception dans la méthode directement.
La deuxième option est préférable selon le principe de responsabilité unique, car la méthode gère les problèmes potentiels avec le code qu’il utilise pour accomplir sa tâche, et les autres méthodes n’ont pas besoin de s’en soucier : elles peuvent se concentrer sur leur propre tâche.
Bloc try et catch pour des entrées invalides
Le bloc try contient le code qui peut lancer une exception, et le bloc catch contient le code à faire si une exception est lancée. Voici la structure de base d’un bloc try et catch :
try {
// code qui pourrait lancer une exception
} catch (Exception e) {
// code à exécuter si une exception est lancée
}
Voici un exemple de code1 qui lance une exception si l’utilisateur entre un texte qui ne peut pas être converti en un nombre entier. Dans cet exemple, on ne laisse pas le programme planter, mais on demande à l’utilisateur de réessayer :
Fichier:
ExceptionExample.java
import java.util.*;
Scanner input = new Scanner(System.in);
int getInt(String prompt) {
// tentatives infinies jusqu'à ce que tout dans le try fonctionne
while (true) {
try {
System.out.print(prompt);
int number = input.nextInt(); // peut planter
return number; // quitte la méthode si tout va bien
} catch (Exception e) { // si ça plante
System.out.println(" Entrée invalide");
input.next(); // vide l'entrée invalide du Scanner
}
}
}
void main() {
int age = getInt("Entrez votre âge : "); // pas besoin de savoir que ça peut planter
System.out.println("Vous avez soumis un âge de : " + age);
}
Notez que dans main on veut simplement obtenir un nombre entier et l’utiliser. Cela est possible parce que la méthode getInt gère les exceptions qui pourraient survenir lors de la conversion de l’entrée utilisateur en un nombre entier. Ainsi, chaque méthode s’occupe de sa propre responsabilité et n’a pas besoin de connaître les détails internes des autres méthodes. C’est un bon exemple de la responsabilité unique.
Voici une autre version de main 1 pour ce même problème, mais dans ce cas-ci, main gère une autre sorte d’entrée invalide : une entrée qui n’est pas un âge valide. Ce type d’erreur ne cause pas d’exception, mais pourrait causer des erreurs de logique dans le programme.
void main() {
int age = getInt("Entrez votre âge : ");
if (age < 0) { // gérer une valeur logiquement invalide
System.out.println("Âge invalide");
} else {
System.out.println("Vous avez soumis un âge de : " + age);
}
}
Bloc try et catch pour des ressources comme des fichiers
Nous étudions les fichiers en plus de détail dans la dernière section de cette unité
Si le programme génère une exception lors de l’utilisation d’une ressource comme un fichier, il est important de fermer la ressource avant de quitter le programme. Pour cela, on utilise une déclaration try avec une ressource. Dans cette version de la structure, la ressource est déclarée dans les parenthèses après le mot-clé try. La ressource est automatiquement fermée par Java à la fin du bloc try, même si une exception est lancée.
Voici la structure d’une déclaration try-catch quand le plantage est lié à la ressource utilisée :
try ( déclaration de la ressource qui peut planter ) {
// code à exécuter avec la ressource si ça ne plante pas
} catch (Exception e) {
// code à exécuter si ça plante
}
Voici un exemple où la ressource qui peut planter est un FileWriter pour écrire dans un fichier.
void writeMessageToFile(String message) {
try (FileWriter output = new FileWriter("./data/output.txt")) {
output.write(message);
} catch (Exception e) {
System.out.println("Chemin de fichier invalide");
}
}
Voici un deuxième exemple où la ressource qui peut planter est l’objet File qu’on passe au Scanner pour extraire son contenu.
String getFileContents(Locale decimalFormat) {
try (Scanner fileReader = new Scanner(new File("./data/input.txt"))) {
fileReader.useLocale(decimalFormat);
fileReader.useDelimiter("\\Z"); // next() s'arrête au caractère de fin de fichier
return fileReader.next();
} catch (Exception e) {
System.out.println("Fichier introuvable");
return null; // quittez la méthode avec une référence `null` pour le String
}
}
Notez que dans ces deux exemples, on doit déclarer et initialiser la ressource plantable entre des parenthèses après le mot-clé try.
Exceptions spécifiques
Pour ce cours, c’est tout à fait normal d’utiliser Exception - la plus générale de toutes les exceptions - comme type d’exception dans le bloc catch. Mais en situation de production logicielle, c’est important de déclarer l’exception spécifique qui peut survenir dans le bloc catch.
Par exemple :
- Dans le cas d’entrée invalide, le type d’exception qui est lancée est
InputMismatchException(avec les méthodes de Scanner nextInt et nextDouble) ouNumberFormatException(si on utilise plutôt Integer.parseInt(input.next()) ou Double.parseDouble(input.next())). Ce sont des exceptions pour les erreurs de conversion de chaînes de caractères en nombres. - Dans le cas de la lecture ou l’écriture de fichiers, l’exception est
IOException.
Utiliser une exception spécifique permet de gérer les exceptions de manière plus précise. En fait, cette structure nous permet de déclarer un bloc catch pour chaque type d’exception qui peut survenir. Le premier bloc catch qui correspond à l’exception lancée est celui qui est exécuté, comme une cascade if-else if, alors c’est important de les mettre dans l’ordre du plus spécifique (p. ex. IOException) au plus général (Exception).
Exercices
📚 Tester la compréhension
aucun quiz de vérification des concepts ici encore
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices
- Créez une copie de
ExceptionExample.javaet le tester. - Ajoutez une méthode
double getDouble(String prompt)qui fonctionne de la même manière quegetInt, mais pour les nombres à virgule flottante et ajouter une utilisation de cette méthode dansmain. - Remplacez
System.out.println("Entrée invalide");dans les blocs catch avece.printStackTrace();pour voir le message d’erreur complet sans toutefois faire planter le programme. Notez le type d’exception qui est lancée (celui qui s’affiche en premier dans le message d’erreur).
-
Exemple applicant les classes implicites et le main d’instance de JEP 463 (pleinement intégré aux outils Java22+) ↩ ↩2
Accueil > Programmer avec Java > Structures de données >
📚 Tableau
Survol et attentes
Définitions
- tableau
- une structure de données qui stocke une collection d’éléments de même type. En anglais, ça s’appelle un array. En Java, les tableaux sont de taille fixe. Il sont déclarés avec des crochets droits
[]après le type de données. P. ex.int[] tableau;pour un tableau d’entiers. - index
- un nombre entier qui identifie la position d’un élément dans un tableau. Les index dans Java, comme dans la majorité des langages, commencent à 0. On accède à un élément spécifique d’un tableau avec
tableau[index]. Si l’index fourni n’est pas valide (négatif ou >=length), Java génère une erreurArrayIndexOutOfBoundsException. length- un attribut d’un tableau qui indique le nombre d’éléments dans le tableau. Pour un tableau
tableau, on peut obtenir la longueur avectableau.length. Arrays- une classe Java qui fournit des méthodes pour manipuler des tableaux, comme pour les afficher ou les trier sans avoir à développer ces algorithmes nous-mêmes.
- traverser
- parcourir tous les éléments d’un tableau. Il existe plusieurs façons de le faire en Java, notamment avec une boucle
for, une bouclewhileou une bouclefor-each. C’est une technique de base pour un grand nombre d’algorithmes comme trouver des valeurs, compter des éléments, ou les trier. - variable accumulateur
- une variable utilisée pour combiner les valeurs inidividuelles d’un tableau avec une opération quelconque. P. ex. une variable pour la somme de tous les éléments d’un tableau.
- variable drapeau
- une variable utilisée pour indiquer l’état de quelque chose. Si l’état est juste vrai/faux, on peut utiliser un
boolean. Dans d’autre cas, l’état peut être une valeur numérique - comme la position dans un tableau - alors unintpeut être plus approprié. Exemple : un drapeau booléen peut indiquer si un élément est trouvé dans un tableau ou non. Dans le même contexte un drapeu numérique peut indiquer l’index de l’élément trouvé ou -1 s’il n’est pas trouvé.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Comprendre la structure d’un tableau, notamment l’utilisation des index
- Obtenir ou modifier un élément spécifique d’un tableau
- Traverser tous les éléments d’un tableau avec différents types de boucles
Critères de succès
- Je peux organiser mes données dans des tableaux et les intégrer dans la logique de mes programmes Java.
Structure d’un tableau en mémoire
Crédit : Mustapha Ejjaaouani, 2024
Créer et utiliser des tableaux en Java
Crédit : Hervice Ngouffo, 2024
Traverser un tableau - trois façons différentes
Pour traverser un tableau, on utilise une boucle.
Voir les notes sur les boucles pour vous rafraîchir la mémoire.
Dans les exemples ci-dessous, on traverse une boucle simplement pour afficher chaque valeur du tableau.
Boucle while - lire ou modifier les éléments du tableau
La boucle while peut servir pour n’importe quelle boucle.
int[] tableau = {1, 2, 3, 4, 5};
int i = 0;
while (i < tableau.length) {
System.out.println(tableau[i]);
i++;
}
Boucle for - lire ou modifier les éléments du tableau
La boucle for est particulièrement bien adaptée pour les tableaux car les trois opérations sur l’index du tableau dans la version while sont regroupées dans la déclaration de la boucle for.
int[] tableau = {1, 2, 3, 4, 5};
for (int i = 0; i < tableau.length; i++) {
System.out.println(tableau[i]);
}
Boucle for-each - lire seulement
La boucle for-each est une version spécialisée de la syntaxe for conçu spécifiquement pour traverser les collections, y compris les tableaux.
Dans cette boucle, on n’utilise pas les index du tableau - ils sont gérés automatiquement par Java. Plutôt, on utilise une variable temporaire pour chaque élément du tableau. Cette variable doit être du même type que les éléments du tableau.
int[] tableau = {1, 2, 3, 4, 5};
for (int element : tableau) {
System.out.println(element);
}
La ligne for (int element : tableau) se lit comme “pour chaque élément de type int dans le tableau”.
Arrays
La classe Arrays de Java fournit des méthodes pratiques pour manipuler des tableaux.
toString()
Pour afficher les éléments d’un tableau sans écrire un algorithme spécifique, vous pouvez utiliser la commande suivante :
Array.toString(tableau);
Comparez la sortie de cette commande avec la commande System.out.println(tableau); pour voir la différence.
sort()
Pour trier un tableau en ordre croissant, vous pouvez utiliser la commande suivante :
Arrays.sort(tableau);
Cette méthode modifie directement les éléments de tableau ce qu’on appelle un tri en place. Aucun nouveau tableau est généré.
binarySearch()
Contexte : la recherche linéaire
Pour utiliser une recherche linéaire sur un tableau, on peut simplement le traverser élément-par-élément, comme ceci :
int recherche = 3;
boolean found = false;
for (int i = 0; i < tableau.length; i++) {
if (tableau[i] == recherche) {
found = true;
break;
}
}
S’il n’y a jamais d’égalité entre la valeur cherchée et un élément du tableau, found restera false. Sinon, on change found à true et on sort de la boucle.
La plupart des méthodes de recherche retourne un index valide si l’élément est trouvé, ou un index négatif si l’élément n’est pas trouvé. L’algorithme pour ça est identique à l’algorithme précédent, mais on remplace le drapeau booléen avec un drapeau numérique :
int recherche = 3;
int found = -1;
for (int i = 0; i < tableau.length; i++) {
if (tableau[i] == recherche) {
found = i;
break;
}
}
Recherche binaire
Par contre, si on a beaucoup d’éléments à chercher, une méthode plus efficace est la recherche binaire. Il y a une précondition, par contre : pour utiliser la recherche binaire, le tableau doit être trié.
Voici comment on peut utiliser la recherche binaire avec Arrays :
int recherche = 3;
Arrays.sort(tableau);
int index = Arrays.binarySearch(tableau, recherche);
Pour plus de détails sur les algorithmes de recherche et l’efficacité algorithmique, voir le cours ICS4U!
Exemple complet - faire la moyenne des éléments d’un tableau
Crédit : Hervice Ngouffo, 2024
Exercices
📚 Tester la compréhension
Quiz de vérification sur les tableaux et leurs index
🛠️ Pratique
Vous rendre sur le site codingbat.com et vous créer un compte avec votre courriel écolecatholique.ca. Ajouter mon courriel dans la section Teacher Share afin de me montrer vos progrès.
- Travaillez d’abord 3-4 exercices dans la section “Warmup-1” pour vous familiariser avec le système :
- la formulation des problèmes
- les entrées sous forme de paramètres
- les sorties en tant que valeurs de retour
- les tests automatisés
- les exemples de solutions
- Faites 3-4 exercices dans la section “Array-1” pour vous familiariser avec la structure des tableaux (index et
length). - Faites 3-4 exerices dans la section “Array-2” pour vous familiariser à traverser des tableaux (incluant l’utilisation de
continueetbreak).
La section “Array-3” est plus avancée (matrices / tableaux de tableaux) et peut être considérée comme un défi pour ce cours.
Accueil > Programmer avec Java > Structures de données >
📚 Strings
Survol et attentes
Définitions
L’analyse de texte est une compétence essentielle pour les programmeurs parce que la plupart des entrées arrivent initialement sous forme de texte : via la console, un fichier, ou un formulaire web. Les méthodes de la classe String de Java sont essentielles pour manipuler et analyser les chaînes de caractères.
On a déjà vue d’autres méthodes pour manipuler les String et pour les comparer. Vous pouvez les réviser ici (manipulations) et ici (comparaisons).
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Analyser le contenu des String avec des méthodes comme
charAt,length,toCharArray,indexOf,lastIndexOf,substring,startsWith,endsWithetcontains. - Nettoyer les entrées texte en utilisant des méthodes comme
replace,stripetsplit. - Se familiariser avec les méthodes “parse” pour convertir des String en types primitifs, notamment
Integer.parseIntetDouble.parseDouble.
Critères de succès
- Je peux utiliser une variété d’entrées texte et extraire leurs informations avec confiance dans mes propres programmes.
Méthodes qui utilisent un drapeau booléen (donne une réponse vrai/faux)
Ces méthodes sont utiles pour sonder le contenu d’un texte, soit comme réponse en soi ou comme condition pour une prochaine étape de traitement. Par exemple, on peut vérifier si un texte commence ou finit avec une certaine lettre (ou séquence de lettres) ou s’il contient un mot spécifique.
Voici quelques exemples :
String s1 = "Hello, World!";
boolean b1 = s1.startsWith("Hello"); // true
boolean b2 = s1.endsWith("World!"); // true
boolean b3 = s1.contains(" "); // true
Méthodes qui utilisent la nature tableau des String (se basent sur des index)
La valeur de chaque String est un tableaux de bytes représentant chacun des caractères Unicode dans le texte. On peut alors accéder à chaque caractère individuellement en utilisant un index et une méthode appropriée. On peut aussi sonder le texte et recevoir un index en retour au lieu d’une valeur booléenne.
charAt, length et toCharArray
La méthode charAt est utile pour accéder à un caractère spécifique dans une chaîne de caractères. On utilise un index pour spécifier la position du caractère, en commençant à 0 pour le premier caractère. Si l’index est plus grand que la longueur de la chaîne, une exception StringIndexOutOfBoundsException sera lancée. On peut obtenir la longueur de la chaîne avec la méthode length(). On peut aussi convertir une chaîne de caractères en un tableau de caractères avec la méthode toCharArray.
String s1 = "Hello, World!";
char c1 = s1.charAt(0); // 'H'
char c2 = s1.charAt(7); // 'W'
char c3 = s1.charAt(s1.length() - 1); // '!'
for (char c : s1.toCharArray()) {
System.out.println((int)c); // affiche le code Unicode de chaque caractère
}
- Notez que la valeur de retour de
charAtest uncharet non unString. Ça peut être utile pour les comparaisons (avec==) ou pour obtenir la valeur Unicode, mais ça peut aussi causer des problèmes si on tente de le traiter comme un String.
indexOf et lastIndexOf
Ces méthodes sont utiles pour trouver la position d’un caractère ou d’une séquence de caractères dans une chaîne de caractères. La méthode indexOf retourne la position du premier caractère trouvé, tandis que lastIndexOf retourne la position du dernier caractère trouvé. Si le caractère ou la séquence n’est pas trouvé, -1 est retourné.
String s1 = "Hello, World!";
int i1 = s1.indexOf("o"); // 4
int i2 = s1.lastIndexOf("o"); // 8
int i3 = s1.indexOf("z"); // -1
La méthode indexOf peut prendre un deuxième argument pour spécifier la position de départ de la recherche. Ça peut être utile pour trouver des occurrences multiples d’un caractère ou d’une séquence.
String s1 = "Hello, World!";
int countOs = 0;
int i = 0;
while (i != -1 && i < s1.length()) {
i = s1.indexOf("o", i); // commencer la recherche à partir de la position i
if (i != -1) {
countOs++;
i++; // continuer la recherche après le dernier "o" trouvé
}
}
System.out.println("On a trouvé " + countOs " 'o' dans le texte.");
substring
Cette méthode est utile pour extraire une partie d’une chaîne de caractères. On spécifie la position de départ et la position de fin (exclusif) pour extraire la sous-chaîne. Si on ne spécifie pas la position de fin, la sous-chaîne sera extraite jusqu’à la fin de la chaîne.
String s1 = "Hello, World!";
String s2 = s1.substring(7); // "World!"
String s3 = s1.substring(7, 9); // "Wo"
Méthodes pour nettoyer les String
replace
Cette méthode est utile pour remplacer un caractère ou une séquence de caractères par un autre. Par exemple, si on veut remplacer tous les espaces par des tirets dans une chaîne de caractères, on peut utiliser la méthode replace. Même chose pour remplacer les virgules avec des points.
Voici un exemple :
String s1 = "Dé connecté";
String s2 = s1.replace(" ", "-"); // "Dé-connecté"
String s3 = s1.replace(" ","").replace("Dé","Re"); // "Reconnecté"
- Notez que le texte original n’est pas modifié. La méthode
replaceretourne une nouvelle chaîne de caractères avec les modifications. - Notez qu’on peut remplacer quelque chose avec le texte vide
""pour l’éliminer. - On peut aussi chaîner les appels de méthode pour effectuer plusieurs remplacements en une seule ligne. Ça marche parce que la méthode
replaceretourne une nouvelle chaîne de caractères qui devient le String utilisé pour la prochaine appel dereplace.
strip
Cette méthode est pratique pour éliminer les espaces blancs inutiles au début et à la fin d’une chaîne de caractères. Elle est surtout importante avant de comparer des String, parce que les espaces feront partie de la comparaison s’ils sont encore présents.
Voici un exemple :
" Hello, World! ".equals("Hello, World!"); // false
" Hello, World! ".strip().equals("Hello, World!"); // true; strip enlève les espaces initiaux et finaux
Il existe aussi la méthode
trimqui fait la même chose, mais elle ne reconnaît pas les espaces Unicode. La méthodestripest plus moderne et plus fiable.
split
Cette méthode est utile pour séparer une ligne de texte, obtenu notamment avec la méthode nextLine de Scanner, en plusieurs éléments. Par exemple, si on a une ligne de texte avec des mots séparés par des espaces, on peut les séparer en utilisant un espace " " comme délimiteur. Un format de fichier commun est le CSV (Comma Separated Values) où les valeurs sont séparées par des virgules ou des points-virgules. La méthode split est utile pour séparer ces valeurs en utilisant "," (ou ;) comme délimiteur.
Voici un exemple où on doit utiliser strip pour nettoyer les valeurs une fois qu’elles ont été séparées :
String s1 = "Hello, World!";
String[] words = s1.split(","); // ["Hello", " World!"]
for (int i = 0; i < words.length; i++) {
words[i] = words[i].strip();
} // ["Hello", "World!"]
Alternative : Scanner
Une autre façon de séparer les valeurs d’une ligne de texte est d’utiliser un objet Scanner. Voici un exemple :
Scanner sc = new Scanner("Hello, World!");
sc.useDelimiter(",");
while (sc.hasNext()) {
System.out.println(sc.next().strip());
}
sc.close();
- On utilise la méthode
useDelimiterpour spécifier le délimiteur entre les différents éléments du texte. - On utilise la méthode
hasNextpour vérifier s’il reste des éléments à traiter dans la boucle. - On peut immédiatement appliquer
stripsur chaque élément pour nettoyer les espaces blancs en le chaînant avecnext.
Et voici un autre exemple où on connaît le type des données à chaque position sur la ligne :
// un Scanner pour la source de données
Scanner sc = new Scanner("Alice, 25, 3.14\nBob, 30, 2.71\n");
while (sc.hasNextLine()) { // boucle pour traiter multiples lignes dans la source
String line = sc.nextLine();
Scanner lsc = new Scanner(line); // un autre Scanner pour chaque ligne
lsc.useDelimiter(",");
String name = lsc.next().strip();
int age = lsc.nextInt();
double rating = lsc.nextDouble();
lsc.close();
System.out.printf("%s a %d ans et une cote de %.2f\n", name, age, rating);
}
sc.close();
La sortie de ce code sera :
Alice a 25 ans et une cote de 3.14
Bob a 30 ans et une cote de 2.71
- On utilise un
Scannerpour traiter chaque ligne de texte. - Rappel : le caractère
\nest le caractère pour indiquer une nouvelle ligne. - Connaissant le format des données, on peut utiliser la méthode
next,nextIntetnextDoubleaux endroits appropriés.
Les méthodes “parse”
Ces méthodes sont utiles pour convertir des chaînes de caractères en types primitifs. Par exemple, si on veut convertir une chaîne de caractères en un entier, on peut utiliser la méthode Integer.parseInt.
Prenons le dernier exemple de l’alternative avec le Scanner. Si on utilise split sur chaque ligne au lieu d’un Scanner, on n’aura pas accès aux méthodes nextInt et nextDouble pour convertir les valeurs en entiers et en doubles. On doit alors utiliser les méthodes “parse” pour convertir les chaînes de caractères en types primitifs.
Voici ce même exemple réécrit avec split et les méthodes “parse” appropriées:
Scanner sc = new Scanner("Alice, 25, 3.14\nBob, 30, 2.71\n");
while (sc.hasNextLine()) { // boucle pour traiter multiples lignes dans la source
String line = sc.nextLine();
String[] values = line.split(",");
String name = values[0].strip();
int age = Integer.parseInt(values[1].strip());
double rating = Double.parseDouble(values[2].strip());
System.out.printf("%s a %d ans et une cote de %.2f\n", name, age, rating);
}
sc.close();
- Notez qu’on réfère aux valeurs du tableau
valuesavec leurs index - Notez aussi qu’il faut utiliser
strippour nettoyer les valeurs avant de les convertir en entiers ou en doubles, contrairement aux méthodesnextIntetnextDoublequi font ça automatiquement.
Exercices
🛠️ Pratique
Vous rendre sur le site codingbat.com pour les exercices suivants.
- Travaillez dans la section “String-1” pour vous familiariser avec les méthodes de la classe
String. - Travaillez dans la section “String-2” pour ajouter des boucles à vos analyses des entrées texte.
Accueil > Programmer avec Java >
🛠️ Lire et écrire des fichiers
Survol et attentes
Définitions
File : une classe Java qui permet de manipuler des fichiers et des répertoires. On importe cette classe avec import java.io.File;. File nous permet de créer, supprimer, renommer, etc. des fichiers et des répertoires. Au plus simple, on utilise un objet de type File comme source pour un Scanner.
- Par exemple,
Scanner fileReader = new Scanner(new File("nomDuFichier.txt")).
FileWriter : une classe Java qui permet d’écrire des données dans un fichier texte avec la méthode write(). On importe cette classe avec import java.io.*;. On a plusieurs options pour le créer un objet de ce type mais les deux les plus communs sont :
new FileWriter("nomDuFichier.txt")-> En créant ce FileWriter, le contenu existant du fichier sera remplacé par les appels dewrite.new FileWriter("nomDuFichier.txt", true)-> En créant ce FileWriter et en assignanttrueau 2e paramètre, on ajoute du contenu à la fin du fichier avec les nouveaux appels dewrite.
objet anonyme : un objet qui n’a pas de nom, donc qui est utilisable seulement à l’endroit où il est déclaré. On peut créer un objet anonyme directement dans un appel de méthode.
- Par exemple,
new Scanner(new File("nomDuFichier.txt"))crée un objet Scanner qui lit le nouvel objet anonymeFile. - Cette approche remplace la déclaration d’une variable pour l’objet, p. ex.
File inputFile = new File("./data/input.txt");suivie deScanner fileReader = new Scanner(inputFile);.
chemin de fichier : séquence de dossiers à partir d’un point de référence, se terminant avec le nom complet du fichier, soit son nom et son extension.
- Pour un projet Java, le point de référence est le dossier du projet, donc le chemin commence par
./. - Par exemple,
./data/input.txtpour un fichier texteinput.txtqui se trouve dans un dossierdataà la racine du projet.
références de dossier spéciales : On peut inclure certaines références spéciales au début d’un chemin comme :
..pour le dossier parent,.pour le dossier actuel,~pour le dossier utilisateur et/pour le dossier racine.
classe de données : une classe qui ne contient que des variables pour stocker des données. On l’utilise pour organiser des données lues d’un fichier texte, notamment en créent un tableau d’objets de cette classe.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- Reconnaître les ressemblances entre lire et écrire à la console et lire et écrire dans des fichiers texte.
- Appliquer les techniques de Scanner pour lire des fichiers directement ou pour lire un String.
- Utiliser les classes File et FileWriter pour manipuler des fichiers texte.
Critères de succès
- Je peux intégrer la lecture de fichiers texte ou l’écriture de fichiers texte dans mes programmes Java.
Gérer les exceptions
Parce qu’on essaie d’accéder à une ressource - un fichier - qui n’existe peut-être pas (si on l’a mal nommé ou si le chemin est mal formé ou si son dossier n’a pas été crée en premier), on utilise généralement un bloc try-catch avec ressources pour l’action de lire ou écrire dans un fichier. Le format général est :
try (déclarer et initialiser la ressource) {
// code pour lire ou écrire dans le fichier
/* retourner une valeur utile et/ou assigner les valeurs lues
à des variables déclarées à l'extérieur du bloc try-catch */
} catch (Exception e) {
// message d'erreur
// retourner/assigner une valeur par défaut
}
Un avantage majeur du bloc try-catch est que la ressource est automatiquement fermée à la fin du bloc, même si une exception est lancée. Cela évite les fuites de ressources et les erreurs de programmation.
Un autre avantage est qu’en cas de plantage, on a une valeur connue qu’on peut utiliser dans une condition pour éviter que le reste du programme ne plante. Par exemple, si on sait que la valeur d’un String lue revient null en cas d’erreur, on peut tester si la valeur est null comme pré-condition pour continuer le programme.
Il y a deux exemples de code dans la leçon sur les exceptions qui représentent des bons points de départ pour lire et écrire des fichiers :
D’autres exemples d’algorithmes incluant des exceptions sont fournis plus bas.
Connaître la structure du fichier
Pour bien lire un fichier, il faut avoir une idée de sa structure ou, mieux, connaître exactement sa structure.
Cela vous permet de développer un plan pour lire le fichier, notamment :
- Est-ce que la première ligne est spéciale, avec un chiffre indiquant le nombre de lignes de données, par exemple ? -> Cela vous permet de déclarer un tableau de taille appropriée pour les données et de fixer une limite ferme pour la boucle de lecture.
- Est-ce que les données sur une ligne sont séparées par des virgules, des espaces, des tabulations, etc. ? -> Cela vous permet de configurer le Scanner correctement avec
useDelimiter() - Quels types de données se trouvent à chaque position sur une ligne ? -> Cela vous permet de configurer la suite d’instructions
next*pour lire les données - Est-ce que les nombres décimaux utilisent un point ou une virgule pour le séparateur décimal ? -> Cela vous permet de configurer le Scanner correctement avec
useLocale()
Un objet sur mesure pour nos données
Connaissant la structure des données sur chaque ligne d’un fichier, vous pouvez vous casser la tête à savoir comment organiser toute l’information lue afin de pouvoir l’utiliser dans votre programme et pas seulement l’afficher à l’écran.
La solution est de créer une petite classe qui ne contient aucune méthode mais juste des variables pour stocker les données. On appelle cette classe une classe de données.1 2
Par exemple, plus loin on voit un exemple où on veut lire le mois (String), la température moyenne (double) et la précipitation (int) pour chaque mois de l’année. On pourrait créer une classe WeatherData avec les variables month, averageTemp et precipitation pour stocker ces données.
/** Définit notre propre structure de données */
class WeatherData {
String month;
double averageTemp;
int precipitation;
}
void main() {
// déclare un tableau qui contient des éléments de type WeatherData
WeatherData[] monthlyWeather = new WeatherData[12];
//... lire les données dans le tableau
}
Sans notre propre type de données on aurait dû utiliser des tableaux séparés de String, double et int pour stocker les données. Cela aurait été plus difficile à lire et à maintenir. Et dans Java, on ne peut retourner qu’une seule valeur d’une méthode, alors on n’aurait pas pu retourner les trois tableaux ensemble. On serait obligé de déclarer ces tableaux globalement (dans la classe).
Dans la boucle de lecture, on peut assigner les valeurs lues aux 3 variables d’instance de chacune des 12 objets de la classe WeatherData et ensuite retourner le tableau pour l’utiliser dans le reste du programme. Par exemple :
import java.io.*;
import java.util.*;
void main() {
Scanner fileReader = new Scanner(new File("weather_data2022.txt"));
WeatherData[] monthlyWeather = getWeatherData(fileReader);
filereader.close();
// ...code pour utiliser monthlyWeather
}
class WeatherData {
String month;
double averageTemp;
int precipitation;
}
WeatherData[] getWeatherData(Scanner fileReader) {
WeatherData[] weather = new WeatherData[12]; // créer un tableau de 12 objets
for (int i = 0; i < 12; i++) {
weather[i] = new WeatherData(); // initialiser chaque objet
// initialiser ses variables
weather[i].month = fileReader.next();
weather[i].averageTemp = fileReader.nextDouble();
weather[i].precipitation = fileReader.nextInt();
}
return weather; // retourner le tableau
}
Une classe comme WeatherData est le début de la programmation orientée-objet, le thème du cours ICS4U.
Lire un fichier texte avec un Scanner
Il y a plusieurs façons de lire un fichier texte avec un Scanner.
- Pour un fichier simple, on peut créer un seul objet Scanner (pour le fichier) et utiliser une séquence de
next*pour lire les données. - Pour un fichier qui contient des données structurées qui se répètent, soit un tableau de valeurs comme, p. ex., un fichier CSV, en plus du Scanner pour le fichier, on doit généralement créer une boucle pour lire les données ligne-par-ligne.
- Pour un fichier de texte non structurée (comme une histoire), on peut extraire le contenu du fichier au complet dans un String et utiliser un Scanner pour lire ce String mot-par-mot ou phrase-par-phrase ou utiliser d’autres méthodes String pour l’enquêter.
Il y a plusieurs autres approches possibles, alors ces trois-ci ne sont que des points de départ. Dans tous les cas, l’algorithme ressemble généralement à ceci :
- Déclarer des variables pour stocker les données lues.
- Extraire les données dans un bloc try-catch avec ressources (la déclaration du Scanner pour le fichier); définir des valeurs par défaut en cas d’erreur.
- Si la valeur lue est la valeur en cas d’erreur (clause de garde) :
- quitter le programme (ou éviter autrement l’utilisation du code qui dépend des valeurs lues).
- Sinon :
- utiliser les données lues dans le reste du programme.
Lire un fichier simple
Prenons l’exemple d’un fichier qui conserve le meilleur pointage obtenu en jouant votre jeu. Le fichier highscore.txt pourrait ressembler à ceci :
David 99
On sait qu’il contient juste un nom (de type String) et un pointage (de type int). On peut lire ce fichier avec le code suivant :
void main() {
String name; // variables déclarées à l'extérieur du bloc try-catch
int score;
try (Scanner fileReader = new Scanner(new File("./highscore.txt"))) {
name = fileReader.next(); // valeurs en cas de succès
score = fileReader.nextInt();
} catch (Exception e) {
System.out.println("Erreur de lecture du fichier.");
name = null; // valeurs en cas d'erreur
score = 0;
}
// précondition ("clause de garde")
if (name == null) {
System.out.println("Aucun pointage n'a été enregistré.");
// possiblement quitter le programme avec return;
}
// ...code pour utiliser name et score
}
Lire un fichier structuré
Prenons l’exemple d’un fichier qui conserve les températures moyennes pour chaque mois de l’année, incluant les valeurs maximum et minimum, et la quantité de précipitation en mm. Le fichier weather.txt pourrait ressembler à ceci :
Ottawa
Mois;Tmoy(C);Tmin(C);Tmax(C);Précip(mm)
Janvier;-9,1;-18,2;11,4;114
Février;-11,3;-22,4;10,2;98
Mars;-8,2;-12,3;17,3;140
...
Décembre;-12,3;-16,4;12,3;87
On voit :
- la première ligne donne juste le nom de la ville
- la deuxième ligne donne les noms des colonnes et les unités de mesure
- il y 12 lignes de données par la suite (1 pour chaque mois)
- les valeurs sont séparées par des points-virgules
- les nombres décimaux utilisent une virgule comme séparateur décimal
Si on s’intéresse juste aux valeurs des températures moyennes et de la précipation, on peut prévoir les étapes suivantes :
- configurer le Scanner pour lire les données avec
useDelimiter(";")etuseLocale(Locale.CANADA_FRENCH) - des commandes spéciales pour lire la ville et ignorer la ligne avec les noms de colonne
- une boucle qui fait 12 itérations pour lire les données mensuelles ligne-par-ligne : un
nextpour le mois, 1nextDoublepour la température, 2nextqu’on ignore et unnextIntpour les précipitations
Une implémentation possible utilisant la classe WeatherData décrite plus haut est la suivante :
void main() {
WeatherData[] weather; // variable déclarée à l'extérieur du bloc try-catch
String city;
try (Scanner fileReader = new Scanner(new File("./weather.txt"))) {
fileReader.useDelimiter(";");
fileReader.useLocale(Locale.CANADA_FRENCH);
city = fileReader.nextLine(); // première ligne
fileReader.nextLine(); // ignorer l'en-tête à la 2e ligne
weather = new WeatherData[12]; // pour les 12 lignes de données
for (int i = 0; i < 12; i++) {
weather[i] = new WeatherData(); // initialiser chaque objet
weather[i].month = fileReader.next(); // initialiser ses variables
weather[i].averageTemp = fileReader.nextDouble();
fileReader.next(); // ignorer la température minimale
fileReader.next(); // ignorer la température maximale
weather[i].precipitation = fileReader.nextInt();
}
} catch (Exception e) {
System.out.println("Erreur de lecture du fichier.");
weather = null; // valeurs en cas d'erreur
}
// précondition ("clause de garde")
if (weather == null) {
System.out.println("Aucune donnée météo n'a été enregistrée.");
// possiblement quitter le programme avec return;
}
// ...code pour utiliser weather
}
Lire un fichier non structuré
Prenons l’exemple d’un fichier qui contient une histoire. Le fichier story.txt pourrait ressembler à ceci :
Il était une fois, dans une galaxie lointaine, très lointaine...
Ici le but est juste d’extraire le texte au complet afin de l’analyser par la suite. Une technique efficace est d’utiliser le caractère spéciale \\Z qui désigne la fin d’un fichier comme délimiteur du Scanner. Lire le ficher revient alors à un seul appel de next :
void main(){
String story; // variable déclarée à l'extérieur du bloc try-catch
try (Scanner fileReader = new Scanner(new File("./story.txt"))) {
fileReader.useDelimiter("\\Z"); // configurer le Scanner
story = fileReader.next(); // lire le fichier au complet
} catch (Exception e) {
System.out.println("Erreur de lecture du fichier.");
story = null; // valeurs en cas d'erreur
}
// précondition ("clause de garde")
if (story == null) {
System.out.println("Aucune histoire n'a été enregistrée.");
// possiblement quitter le programme avec return;
}
// ...code pour utiliser story,
// incluant potentiellement d'autres Scanners
}
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices.
Lire un fichier simple
- Créez un fichier
FileReading1.javaet y ajouter sa méthode main. - Créez un fichier texte
moodJournal.txtqui contient la ligne suivante :2024-04-27 heureux. Implémentez un algorithme dansmainqui :- Lit le contenu du fichier
moodJournal.txtdans un bloc try-catch et affiche son contenu à la console. - Lit le contenu du fichier
moodJournal.txtdans un bloc try-catch et assigne les valeurs individuelles à des variables pour la date et l’humeur (deuxString). Préparer un message à l’extérieur du bloc try-catch qui affiche la date et l’humeur. - (DÉFI) Lit le contenu du fichier
moodJournal.txtdans un bloc try-catch et assigne les valeurs individuelles à des variables pour l’année, le mois, le jour (3int) et l’humeur (String).Trois pistes pour Scanner les parties de la date : (1) modifiez le délimiteur du Scanner (“-” et “ “), (2) utilisez d’abord
nextpour la date entière et déclare un Scanner sur ce texte avec un délimiteur de “-” pour saisir les int, (3) utilisersplit("-")sur la date entière etInteger.parseIntsur chaque élément du tableau.
- Lit le contenu du fichier
Lire un fichier structuré
- Créer un fichier
FileReading2.javaet y ajouter sa méthode main.
Écrire dans un fichier
- Créer un fichier
FileWriting.javaet y ajouter sa méthode main.
-
Java offre aussi une structure de données appelée
Recordqui est plus spécifique qu’une classe mais exactement pour ce genre de situation, mais qui masque les données, ce qui est un concept plus avancé qu’on voit seulement en 12e année. ↩ -
Les exemples de code ci-dessous appliquent le JEP 463 (classe abstraite, méthode
maind’instance), alors seulement la classe interne pour la structure de données est déclarée dans le code. ↩