Accueil > Programmer avec Java >
🛠️ Tests unitaires
- Cas de test
- Approche naïve pour les tests unitaires
- JUnit - framework Java pour les tests unitaires
- Exemple de test unitaire avec JUnit
Survol et attentes
Dans un programme décomposé, c’est important de tester chaque méthode avant de l’intégrer dans une méthode appelante. Ainsi, si une erreur se produit, on limite la recherche de l’erreur à une seule méthode.
Définitions
- Test unitaire
- vérifier si une méthode produit le résultat attendu pour un ensemble d’entrées spécifiques. Un test unitaire évalue une seule méthode, d’où le terme “unitaire”.
- Cas de test
- un scénario (une entrée spécifique) qui doit être testé pour une méthode. Chaque cas de test fait le lien entre les entrées et les sorties attendus. Un test unitaire inclut généralement tous les cas de test identifiées pour une méthode.
- JUnit
- un framework de test unitaire pour Java. Nous utiliserons la suite d’outils Java dans VS Code pour installer et exécuter les tests JUnit. De plus, ces outils créent automatiquement les fichiers de test et les signatures des méthodes pour chaque test unitaire.
- Framework
- un ensemble d’outils et de conventions qui facilitent le développement de logiciels. Un framework est plus vaste qu’un package ou une module de code, et la plupart des applications logicielles sont bâtis à l’aide de frameworks. JUnit est un framework pour les tests unitaires.
- Test d’entrée/sortie
- test unitaire qui doit tenir compte des valeurs normalement saisies via l’entrée standard et affichées à la console. Ces tests sont plus difficiles à automatiser parce qu’il faut temporairement rediriger l’entrée et/ou la sortie standard vers des sources de texte écrites à l’avance dans le test.
Objectifs d’apprentissage
À la fin de cette leçon vous devrez être en mesure de :
- décrire c’est quoi un test unitaire et pourquoi on les utilise.
- savoir comment choisir des cas de test pour une méthode donnée.
- savoir comment utiliser les outils dans VS Code pour créer et exécuter des tests unitaires pour des programmes Java.
Critères de succès
Évalués sommativement dans ce cours :
- Je suis capable de rédiger une liste de cas de test pour une méthode donnée et d’intégrer ces cas dans le test unitaire.
- Je suis capable d’adapter le gabarit de test d’égalité pour mes méthodes.
Aspirationnels - on n’a pas assez de temps dans ce cours pour devenir vraiment bons à ces compétences, mais on peut les explorer :
- Je suis capable de créer un fichier de test et les méthodes de test pour mes programmes en utilisant les outils de JUnit dans VS Code.
- Je suis capable d’adapter le gabarit de test d’entrée et de test de sortie pour mes méthodes.
Pourquoi faire des tests unitaires?
Un programme devient très rapidement large et complexe. On utilise déjà la décomposition pour gérer la complexité et la taille du programme : elle nous permet de résoudre une série de petits problèmes.
Par contre, l’avantage de la décomposition est largement gaspillé si on ne vérifie pas le bon fonctionnement de chaque méthode - chaque morceau du problème décomposé - avant de l’intégrer dans la méthode plus haut dans la chaîne d’appels. La raison est la suivante : s’il y a une erreur dans une méthode qu’on n’a pas testé mais on l’intègre sans connaissance dans une autre méthode, lorsque on exécute éventuellement le programme, on ne sait pas si l’erreur vient de la méthode appelante ou de la méthode appelée. Ce problème explose avec le nombre d’intégrations de méthodes qu’on fait avant de tester.
Avec les tests unitaires, on peut isoler les erreurs à une seule méthode, limitant la quantité de code à vérifier pour corriger l’erreur. Le but est de tester chaque méthode et de s’assurer de son fonctionnement avant de l’intégrer dans une autre méthode. Ainsi, si une erreur se produit, on sait qu’elle vient du plus récent code qu’on a écrit et non des autres méthodes qui existent déjà.
Un autre avantage des tests unitaires formelles, comme ceux avec le framework JUnit, est que si on modifie le programme, on peut relancer tous les tests que nous avons déjà écrits pour s’assurer que les modifications n’ont pas cassé quelque chose qui fonctionnait déjà.
Cas de tests
En faisant un test unitaire, on doit savoir quel comportement est attendu de notre méthode, soit qu’est-ce qui constitue un résultat acceptable. Les cas de tests sont simplement la description de ces comportements attendus pour une méthode donnée. C’est, en fait, la partie la plus importante de l’écriture des tests unitaires. Si on ne sait pas ce qu’on attend de notre méthode, on ne peut pas écrire de tests pour vérifier si la méthode fonctionne correctement.
Déterminer quels sont les cas de test importants est un art. Il faut trouver un équilibre entre tester tous les cas possibles et tester seulement les cas les plus importants. Voici quelques pistes pour déterminer les cas de test pour une méthode :
- Cas de test limites : les cas de test qui couvrent les valeurs aux limites de ce qui serait normalement attendu. Par exemple, si on doit donner une note entre 0 et 100, on devrait tester avec 0 et 100. De même, si dans la zone des valeurs acceptés, il y a des limites pour différentes catégories, on devrait tester ces limites aussi. Par exemple, si la note de passage est de 50, on devrait tester avec 49 et 50.
- Cas de test invalides : si notre programme doit gérer la qualité des entrées, il faut aussi prévoir les cas de test qui couvrent les valeurs qui ne devraient pas être acceptées. Par exemple, si on doit donner une note entre 0 et 100, on devrait tester avec -1, 101, et des lettres.
Tableau de cas tests
Pour l’exemple précédent, soit d’une méthode qui calcule la moyenne de deux notes et retourne le résultat comme valeur de retour, on peut préparer le tableau de cas de test suivant :
| Intention | Entrée | Sortie attendue |
|---|---|---|
| deux notes int valides | 80, 90 | 85.0 |
| deux notes double valides | 80.0, 90.0 | 85.0 |
| notes limites | 0, 100 | 50.0 |
| notes limites | 0, 0 | 0.0 |
| notes limites | 100, 100 | 100.0 |
| note négative | -1, 90 | -1.0 // une valeur drapeau pour signaler un résultat invalide |
| note supérieur à 100 | 80, 101 | -1.0 // une valeur drapeau pour signaler un résultat invalide |
On peut représenter ce même tableau comme commentaire de bloc ou comme javadoc dans la méthode de test unitaire, comme ceci :
/*
* Test la méthode `average` pour les cas suivants :
* - deux notes int valides : 80, 90 => 85.0
* - deux notes double valides : 80.0, 90.0 => 85.0
* - notes limites : 0, 100 => 50.0
* - notes limites : 0, 0 => 0.0
* - notes limites : 100, 100 => 100.0
* - note négative : -1, 90 => -1.0 // une valeur drapeau pour signaler un résultat invalide
* - note supérieur à 100 : 80, 101 => -1.0 // une valeur drapeau pour signaler un résultat invalide
*/
Approche naïve pour les tests unitaires
Sans utiliser des outils spécialisés, nous pouvons simplement lancer manuellement le programme après avoir ajouté une nouvelle méthode. Naturellement, on aura probablement appelé la méthode dans la logique globale du programme pour voir si elle fonctionne. Ça marche pour des programmes très simples mais c’est limité même dans ces cas :
- S’il y a plusieur cas de test, on doit les exécuter un par un et comparer les résultats manuellement, possiblement en insérant des
System.out.println()pour afficher les résultats qu’on aura à retirer plus tard. Cela est une tâche lourde et sujette à des erreurs. - Si plusieurs parties du programme doivent s’exécuter avant d’arriver à l’appel de la nouvelle méthode à tester, on doit passer à travers tout le programme pour chaque test. Cela est une perte de temps et d’énergie qui fait en sorte qu’on évite souvent de tester rigoureusement les méthodes.
Mieux mais sans les outils de test unitaire
Pour faire mieux que l’approche décrite ci-dessus, on peut tenter d’écrire des tests unitaires sans l’appui des outils, notamment parce que l’installation des outils peut être complexe et parce que ça nous évite d’apprendre comment utiliser les outils. En écrivant nos propres tests, on peut définitivement pallier aux deux problèmes soulevés ci-dessus :
- on peut inclure les cas de test dans notre code de test
- on peut inclure les comparaisons automatiques avec les résultats attendus dans notre code de test
- on peut exécuter les tests unitaires sans passer par la logique globale du programme
Par contre, tout ça exige la rédaction de beaucoup de code additionnel (avec l’introduction presque garantie de nouvelles erreurs). Et tout ce nouveau code est probablement mieux écrit et définitivement déjà validé dans les outils de test unitaire.
De plus, le code de test “maison” est le plus facile à écrire et à lancer dans la même classe que les méthodes à tester. Cela rend le code dans cette classe plus difficile à lire, sans parler de la méthode main qui peut commencer à ressembler à quelque chose comme ceci :
Fichier:
MyGreatProgram.java
void main() {
// tests unitaires
// testMethod1(); // masqué derrière un commentaire pour ne pas l'exécuter
// testMethod2();
testMethod3();
// logique globale du programme
// ...
}
void method1() {
// ... code qu'on veut utiliser dans le programme
}
void testMethod1() {
// ... code pour tester la méthode qu'on veut utiliser dans le programme
}
// ... reste des méthodes de la classe
Approche standard pour les tests unitaires avec JUnit 4
En se servant des outils existants, comme JUnit :
- notre classe peut être écrite exactement comme on l’a décrit avec la décomposition du problème sans code additionnel,
- les tests peuvent être écrits plus succinctement avec le code fourni par JUnit,
- le lancement des tests est entièrement indépendant du lancement de notre programme et
- nous n’avons pas besoin de programmer comment afficher les résultats des tests parce que JUnit le fait pour nous.
L’utilisation de JUnit nous impose pour la première fois une structure de projet Java qui dépasse un seul fichier :
- le fichier pour notre code et
- un autre fichier pour les tests unitaires.
La section suivante décrit la modification qu’il faut apporter à nos programmes pour les tester avec JUnit.
Structure de projet pour les tests unitaires
On a vu dans une leçon sur les bases de Java que ce langage est utilisé pour d’énormes projets logiciels et que le code peut être divisé en plusieurs types d’unités autonomes du plus grand (les logiciels et les frameworks) aux unités intermédiaires (les modules et les packages) et finalement aux unités atomiques (les classes).
Parce que tous nos programmes jusqu’à présent tenaient dans une seule classe, le compilateur Java nous permettait d’omettre une déclaration de classe et de simplement écrire des déclarations pour nos méthodes et nos variables globales.1 De plus, on n’avait pas à se préoccuper des mots-clés qui sont utilisés pour gérer la visibilité des éléments de notre classe (public, private) ni de comment les méthodes sont appelées (static ou non). On ne travaillera pas avec ces concepts dans ce cours (ils sont couverts dans le cours de 12e année), mais on doit quand même ajouter une chose à notre code pour le tester avec JUnit : une déclaration de classe.
La déclaration de classe donne un nom à notre code et permet au code dans la classe test d’y référer pour utiliser nos méthodes.
Ainsi, si on a un fichier Calculator.java avec le contenu suivant :
int add(int a, int b) {
return a + b;
}
void main() {
System.out.println(add(1, 2));
}
et on veut tester la méthode add, on doit ajouter une déclaration de classe autour de notre code pour le tester avec JUnit :
class Calculator {
int add(int a, int b) {
return a + b;
}
void main() {
System.out.println(add(1, 2));
}
}
- Utiliser l’outil “Mettre le document en forme” dans VS Code pour rétablir une bonne indentation après avoir ajouté la déclaration de classe (n’oubliez pas son accolade fermante à la fin du code).
- Le nom de la classe doit être le même que le nom du fichier et on devrait respecter les conventions Java pour les noms de classe/fichier : commencer par une majuscule et utiliser la casse chameau pour les noms composés.
Pour renommer le fichier, au besoin, utiliser l’outil “Renommer le fichier” dans VS Code parce qu’il renommera automatiquement le nom de la classe et toutes les références à cette classe à travers le projet.
Maintenant, le code dans la classe de test pourra créer un objet de type Calculator pour tester la méthode add(), comme on ajoute des objets de type Scanner pour utiliser ses méthodes next*().
Travailler avec JUnit dans VS Code et l'Extension Pack for Java
On va utiliser pour la première fois l’option “Source Actions” dans VS Code pour créer des tests unitaires. Cette section vous montre comment le faire étape par étape.
ÉTAPE 1 : Créez votre fichier dans un projet Java et écrire au moins une de ses méthodes. Pour cet exemple, on peut utiliser le fichier Calculator.java avec le contenu suivant :
class Calculator {
int add(int a, int b) {
return a + b;
}
void main() {
System.out.println(add(1, 2));
}
}
- ÉTAPE 2
-
Ouvrir le fichier dans VS Code et attendre une minute afin de laisser les outils Java s’activer.
- ÉTAPE 3
-
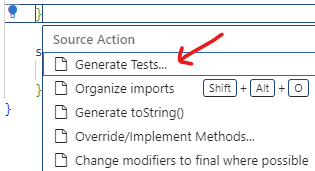
Faites un clic droit n’importe où dans le fichier et choisissez “Source Action…”. Vous devriez voir une option pour
Generate Tests. Cliquez dessus.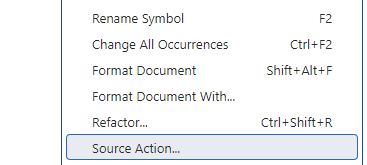 |
| 
- ÉTAPE 4
-
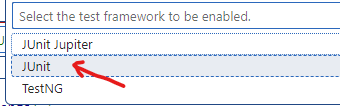
Si c’est la première fois qu’on fait ces étapes dans un projet, VS Code vous donnera une erreur et un bouton
Enable tests. Cliquez dessus et choisir le frameworkJUnit. VS Code installera automatiquement les dépendances nécessaires pour JUnit dans votre projet, dans le sous-dossierlib.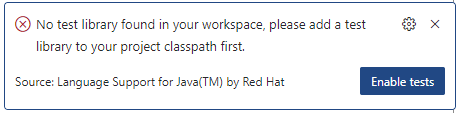 |
|  |
| 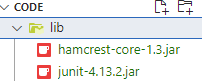
Note : vous aurez à faire cette étape une seule fois par projet, mais vous aurez à la refaire si vous créez un nouveau projet.
- ÉTAPE 5
-
Tapez
Enterpour acceptez le nom proposé pour la classe de test, généralement[nom de ma classe]Test. Dans notre exemple, ce seraitCalculatorTest. - ÉTAPE 6
-
Sélectionnez la méthode que vous voulez tester. Dans notre exemple, on veut tester
add. Cliquez surEnterpour accepter. La classe sera créée avec la signature de la méthode de test pouradd. Cochez seulement la plus récente méthode, celle qui n’a pas encore de test unitaire. |
| 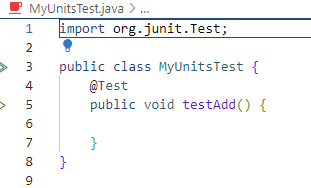
Notez qu’on ne doit pas tester
mainparce qu’il contient la logique globale du programme.mainn’est pas une “unité” mais plutôt “l’intégration” ultime de toutes les unités de notre programme. Ça ne fait pas de sens de préparer des tests unitaires pour cette méthode. - ÉTAPE 7
-
Écrivez les tests unitaires pour les méthodes choisies. C’est à cet étape qu’on doit considérer les cas de test et les implémenter.
Les sections suivantes donnent des gabarits de tests unitaires que vous pouvez utiliser pour écrire vos tests.
- ÉTAPE 8
-
Exécutez les tests unitaires en cliquant sur le bouton
Run Testà côté de la méthode de test ou en cliquant sur le boutonRun All Testsen haut de la classe de test.
Notez que s’il y a une seule classe dans votre projet qui contient des erreurs de syntaxe, vous recevrez un message d’erreur avant le lancement des tests parce que les outils Java compilent tout votre projet. Si l’erreur n’est pas dans la classe à tester ni dans la classe avec les tests, vous pouvez simplement cliquer sur le bouton
Continuepour ignorer ces erreurs et lancer les tests.
- ÉTAPE 9
-
Analysez les résultats des tests dans la fenêtre de sortie de JUnit. Si les tests sont tous réussis, rien ne s’affichera et vous devrez vous rendre à l’onglet “Test Results” pour voir la sortie. Si un test échoue, vous verrez un message d’erreur dans la fenêtre de sortie.
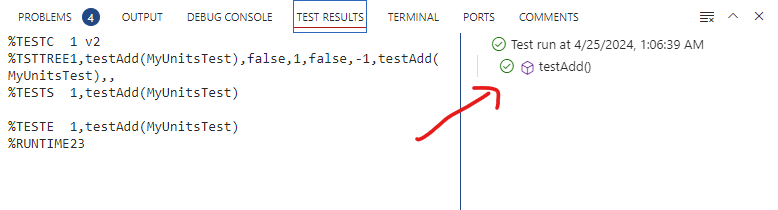
Notez que la sortie texte dans la partie gauche ne dit pas grand-chose d’utile. C’est plutôt la partie droite qui donne l’état de chacun des tests. Le crochet vert est pour un test réussi, le point rouge est pour un test échoué. Vous pouvez cliquer sur le résultat de chaque test pour plus de détails ou pour les lancer de nouveau.
ÉTAPE 10 : Corrigez les erreurs dans votre code et réexécutez les tests jusqu’à ce qu’ils passent tous. Les erreurs peuvent se trouver dans le test unitaire ou dans la méthode que vous testez… mais pas ailleurs! C’est l’avantage de faire des tests unitaires pour chaque méthode qu’on finit d’écrire.
ÉTAPE 11 : Répétez les étapes 3 à 10 pour chaque nouvelle méthode que vous écrivez dans la classe principale du projet.
Gabarits - code de démarrage pour vos tests unitaires avec JUnit
Votre responsabilité principale en lien avec les tests unitaires est la définition des cas de tests pour chaque méthode que vous écrivez.
Par contre, vous pouvez aussi apprendre comment implémenter les tests unitaires qui appliquent ces cas de test à vos méthodes. Pour vous aider, les exemples de tests unitaires ci-dessous vous donnent du bon code de démarrage pour quatre cas communs :
- un test d’égalité,
- un test d’entrée (avec un Scanner global),
- un test d’entrée (avec un Scanner local) et
- un test de sortie.
Selon la structure de vos méthodes, vous aurez probablement à combiner le code de tests différents, p. ex. d’égalité et d’entrée ou d’éntrée et de sortie pour avoir la bonne structure de test pour vos méthodes.
Structure de la classe de test
Voici un gabarit de base pour une classe de test unitaire où vous remplacerez “MyClassname” par le nom de la classe que vous testez. Vous pouvez ajouter autant de méthodes de test que nécessaire dans cette classe.
import static org.junit.Assert.*; // pour les méthodes de comparaison
import org.junit.Test; // pour l'annotation @Test et les outils associés
public class MyClassnameTest {
// déclaration d'un objet de la classe à tester
// p. ex. Calculator calc = new Calculator();
@Test
// déclaration d'une' méthode de test pour une méthode dans votre code
@Test
// déclaration d'une méthode de test pour une autre méthode dans votre code
}
Test d’égalité
Les tests d’égalité sont pour des méthodes qui retournent une valeur. On compare la valeur retournée par la méthode avec la valeur attendue.
Exemple de base
Considérant notre méthode add dans la classe Calculator :
class Calculator {
// ... reste du code de la classe
int add(int a, int b) {
return a + b;
}
}
La classe de test produit par les outils de JUnit dans VS Code serait le suivant, avec quelques lignes additionnelles :
import static org.junit.Assert.*; // ajoutez cette ligne pour les méthodes de comparaison
import org.junit.Test;
public class CalculatorTest {
Calculator calc = new Calculator(); // ajoutez cette ligne pour faire référence à votre code
@Test
public void testAdd() {
}
}
On peut écrire le test unitaire testAdd dans la classe CalculatorTestcomme suit à l’intérieur de la classe de test :
@Test
public void testAdd() {
/*
* Cas de tests pour int add(int, int)
*
* Descr. Entrées Sortie attendue
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* base 1, 2 3
*/
assertEquals(3, calc.add(1,2));
}
Deux points qui peuvent faire planter ce code :
- La méthode
assertEquals()ne sera pas reconnue si vous n’avez pas ajouté l’imporation static d’Assertau début du fichier de test. Voir le gabarit pour la classe de test ci-dessus. - La méthode
add()ne sera pas reconnue si vous n’avez pas créé une variablecalcde typeCalculatordans la classe de test. Voir le gabarit pour la classe de test ci-dessus.
Notez que assertEquals est une méthode de JUnit qui compare le premier argument avec le deuxième argument et lève une exception si les deux arguments ne sont pas égaux. C’est la méthode la plus courante pour tester des valeurs de retour.
Il y a plusieurs autres détails à noter dans ce code :
- L’annotation
@Testet la signature de la méthode ont peut-être été créées automatiquement si vous avez suivi les étapes ci-dessus. L’annotation@Testdevient un point de lancement du code de test pour JUnit. - On écrit les cas de test dans un commentaire de bloc au début de la méthode de test. Dans l’exemple, on a simplement inclut un cas de test, mais vous devrez considérer l’ensemble des cas à tester dans la méthode.
- On utilise la méthode
assertEqualspour implémenter le cas de test, soit comparer le résultat attendu avec la valeur de retour de la méthode testée. Il devrait y avoir un appel àassertEqualspour chaque cas de test.
Exemple pour comparer des 'double'
L’exemple de base fonctionne pour tous les types sauf les valeurs à virgule flottante (comme les double).
Avec les double, dû à la conversion inexacte entre le binaire (dans la machine) et le décimal (dans la représentation du nombre), il y a toujours - ou presque - des erreurs d’arrondissement. Ainsi on ne peut jamais évaluer l’égalité entre deux double directement comme on le fait avec les autres types de données.
L’algorithme à utiliser se résume à :
valeur 1 = valeur 2 ± une marge d'erreur acceptableouvaleur absolue de (valeur 1 - valeur 2) <= une marge d'erreur acceptable(la valeur absolue ignore le signe du résultat)
Par exemple, pour des notes de cours à une décimale près on pourrait note1 = note2 ± 0.1 ou note1 = note2 ± 0.05, selon votre préférence.
Pour les double, JUnit fournit une méthode assertEquals qui prend un troisième argument, la marge d’erreur acceptable. Par exemple, pour une méthode average qui retourne la moyenne de deux nombres à une décimale près, on pourrait écrire le test unitaire comme suit :
@Test
public void testAverage() {
/*
* Cas de tests pour double average(double, double) :
*
* Descr. Entrées Sortie attendue
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* base 80.0, 90.0 85.0
*/
assertEquals(85.0, calc.average(80.0, 90.0), 0.1);
}
Notez que nous fournissons la valeur attendue et la valeur de retour de la méthode testée comme avec l’exemple. Cependant, on ajoute aussi un troisième argument, la marge d’erreur acceptable. Dans cet exemple, on accepte une différence de 0.1 entre la valeur attendue et la valeur de retour.
Le choix de la marge acceptable dépend de la précision requise par votre programme. Comme règle de base, on devrait choisir une marge d’erreur qui est plus petite que la précision finale que nous voulons parce que les erreurs d’arrondissment s’accumulent à chaque opération.
Donc la marge de 0.1 si on veut des résultats à une place décimale est trop généreuse et on perd beaucoup de précision. Règle de base : utiliser une marge d’erreur au moins 3 chiffres de plus que la précision finale désirée. P. ex., si on veut une précision finale de 0.1 on devrait choisir une marge d’erreur d’au maximum 0.0001. le test ci-dessus serait modifié à :
assertEquals(85.0, calc.average(80.0, 90.0), 0.0001);
Test d’entrée
Pour tester une méthode qui sollicite des entrées de l’utilisateur via la console, on a deux options selon la façon dont le Scanner de la console est géré dans la classe du programme :
Scanner static et global | Scanner passé comme paramètre (Scanner local) |
|---|---|
 |  |
Dans le cas d’un Scanner global, parce que la vie de la variable est plus longue que la vie de la méthode, on doit s’assurer de rétablir sa valeur originale avant de quitter le test. Pour le faire, on doit s’assurer de copier sa valeur originale au début du test.
Pour le Scanner local, ces étapes sont éliminées, mais on doit s’assurer de passer le Scanner comme argument à la méthode à tester.
Exemple avec un Scanner global
Si on a la méthode getNameUsingGlobalScanner dans la classe Calculator :
import java.util.Scanner;
class Calculator {
/** Scanner global pour toutes les méthodes de la classe */
Scanner console = new Scanner(System.in);
// ... reste du code de la classe
String getNameUsingGlobalScanner() {
System.out.print("Entrez votre prénom > ");
String name = console.next(); // utilise le Scanner global
console.nextLine(); // jeter tout après le premier mot
return name;
}
}
On peut écrire le test unitaire testGetNameUsingGlobalScanner dans la classe CalculatorTest comme suit :
@Test
public void testGetNameUsingGlobalScanner() {
/*
* Cas de test pour String getName() qui utilise un
* Scanner déclaré globalement
*
* Descr. Entrée Sortie attendue
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* normal "david" "david"
* un caractère "A" "A"
* plusieurs mots "David Crowley" "David"
*/
/* PRÉPARATION */
// garder une référence au Scanner original de calc
Scanner original = calc.console;
// définir les cas de test
String testInput = "david\n" +
"A\n" +
"David Crowley\n"; // les \n sont les `Entrée` de l'utilisateur
// créer une source d'entrées qui contient nos cas de tests
InputStream testStream = new ByteArrayInputStream(testInput.getBytes());
// passer la nouvelle source d'entrées au Scanner de calc
calc.console = new Scanner(testStream);
/* TESTS */
assertEquals("david", calc.getNameUsingGlobalScanner());
assertEquals("A", calc.getNameUsingGlobalScanner());
assertEquals("David", calc.getNameUsingGlobalScanner());
/* NETTOYAGE */
// rediriger le Scanner global de calc à lire sa source originale
calc.console = original;
}
Note : avec l’ajout des InputStream et du Scanner, on doit ajouter import java.io.*; et import java.util.*; au début du fichier de test, p. ex. :
import static org.junit.Assert.*;
import java.io.*; // ici
import java.util.*; // et ici
import org.junit.Test;
public class CalculatorTest {
// ... reste du code de la classe
}
Si on oublie, parfois les outils d’autocomplétion dans VS Code peuvent ajouter ces déclarations automatiquement, mais c’est quelque chose à vérifier si vous avez des messages d’erreurs sur ces variables.
Exemple avec un Scanner local (passé en argument)
Une autre façon d’utiliser un Scanner dans un programme est de le déclarer localement, par exemple avec la méthode getName dans la classe Calculator :
import java.util.Scanner;
class Calculator {
String getName(Scanner in) {
System.out.print("Entrez votre prénom > ");
String name = in.next(); // fait référence au Scanner passé en paramètre
in.nextLine(); // jeter tout après le premier mot
return name;
}
void main() {
Scanner console = new Scanner(System.in); // déclarer un Scanner local
//... autre code
String name = getName(console); // passer le Scanner local comme argument
//... autre code
}
}
Le test unitaire testGetName dans CalculatorTest serait alors :
@Test
public void testGetName() {
/*
* Cas de test pour String getName(Scanner)
*
* Descr. Entrée Sortie attendue
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* normal "david" "david"
* un caractère "A" "A"
* plusieurs mots "David Crowley" "David"
*/
/* PRÉPARATION */
// définir les cas de test
String testInput = "david\n" +
"A\n" +
"David Crowley\n"; // les \n sont les `Entrée` de l'utilisateur
// créer un Scanner qui lit nos entrées de test au lieu de l'entrée standard
InputStream testStream = new ByteArrayInputStream(testInput.getBytes());
Scanner testScanner = new Scanner(testStream);
/* TESTS */
assertEquals("david", calc.getName(testScanner));
assertEquals("A", calc.getName(testScanner));
assertEquals("David", calc.getName(testScanner));
/* NETTOYAGE */
// Le nouveau Scanner est détruit automatiquement à la fin de cette méthode
}
Note : avec l’ajout des InputStream et du Scanner, on doit ajouter import java.io.*; et import java.util.*; au début du fichier de test, p. ex. :
import static org.junit.Assert.*;
import java.io.*; // ici
import java.util.*; // et ici
import org.junit.Test;
public class CalculatorTest {
// ... reste du code de la classe
}
Si on oublie, parfois les outils d’autocomplétion dans VS Code peuvent ajouter ces déclarations automatiquement, mais c’est quelque chose à vérifier si vous avez des messages d’erreurs sur ces variables.
Test de sortie
Les tests de sortie sont utiles pour les méthodes void qui passent leurs résultats à la console. On peut utiliser la redirection de la sortie standard pour capturer les messages affichés par la méthode et les comparer avec les messages attendus.
Exemple de redirection de System.out pour les tests
Considérant la méthode sayName dans la classe Calculator :
void sayName(String name) {
System.out.println("Bonjour " + name);
}
On peut écrire le test unitaire testSayName dans la classe CalculatorTest comme suit :
@Test
public void testSayName() {
/*
* Cas de test pour void sayName(String)
*
* Descr. Entrée Sortie attendue
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* normal "David" "Bonjour David"
* un caractère "A" "Bonjour A"
* plusieurs mots "David Crowley" "Bonjour David Crowley"
*
*/
/* PRÉPARATION */
// garder une référence à la sortie standard originale
PrintStream original = System.out;
// rediriger la sortie standard vers un flux de sortie temporaire
OutputStream outContent = new ByteArrayOutputStream();
System.setOut(new PrintStream(outContent));
/* TESTS */
calc.sayName("David");
calc.sayName("A");
calc.sayName("David Crowley");
String expectedOutput = "Bonjour David\nBonjour A\nBonjour David Crowley\n";
assertEquals(expectedOutput, outContent.toString().replace("\r\n", "\n")); // le replace() est nécessaire sur Windows (encodage de fin de ligne différent)
/* NETTOYAGE */
// rétablir la sortie standard originale
System.setOut(original);
}
Note : on applique la méthode de traitement de texte
.replace("\r\n", "\n")sur la sortie pour s’assurer que les différents types de retour de ligne ne causent pas un échec de la comparaison. Windows utilise\r\npour le retour de ligne, alors que Linux, MacOS et nos propres instructions Java utilisent seulement\n.
Note : avec l’ajout du PrintStream et des OutputStream, on doit ajouter import java.io.*; au début du fichier de test, p. ex. :
import static org.junit.Assert.*;
import java.io.*; // ici
import org.junit.Test;
public class CalculatorTest {
// ... reste du code de la classe
}
Si on oublie, parfois les outils d’autocomplétion dans VS Code peuvent ajouter ces déclarations automatiquement, mais c’est quelque chose à vérifier si vous avez des messages d’erreurs sur ces variables.
Les exemples complets
Vous pouvez voir le code complet pour les classes Calculator et CalculatorTest dans les fichiers Calculator.java et CalculatorTest.java.
Exercices
🛠️ Pratique
Travaillez dans le répertoire GitHub partagé par votre enseignant pour la pratique et les exercices
-
Créez un fichier texte nommé
Cas-de-tests.txtdans votre réprtoire de travail.- Écrivez le tableau de cas de test pour une méthode qui retourne
truesi un nombre est pair etfalsesinon. La signature de cette méthode estboolean isEven(int number). Quels sont les cas normaux? Est-ce qu’il y a des cas limites ou invalides pour cette méthode? - Écrivez le tableau de cas de test pour une méthode qui retourne une note en lettres pour une note numérique. La signature de cette méthode est
char letterGrade(double average). Les lettres sontF(moins de 50),D(50 à 59),C(60 à 69),B(70 à 79) etA(80 à 100). Quels sont les cas normaux? Quels sont les cas limites pour cette méthode, se rappelant que la moyenne est une valeur décimale (il y en a beaucoup!)? Quels sont les cas invalides?
- Écrivez le tableau de cas de test pour une méthode qui retourne
-
Voici une implémentation de la logique de la méthode
isEvendécrit dans le premier exemple.class NumberUtils { boolean isEven(int number) { return number % 2 == 0; } }- Créez une copie de ce fichier et nommez-le
NumberUtils.java. - Utilisez les outils de VS Code pour créer la classe de test et la squelette de test unitaire pour cette méthode.
- Ajoutez une déclaration globale (dans la classe
NumberUtilsTest) pour un objet NumberUtils :NumberUtils utils = new NumberUtils(); - Vous devrez traduire votre tableau de cas de test (écrit plus haut) en commentaire de bloc à l’intérieur de votre méthode de test.
- Implémenter des tests d’égalité pour cette méthode, un test par cas de test identifié. Servez vous du gabarit comme point de départ.
- Exécutez les tests.
- Prenez une capture d’écran de l’onglet “Test Results” pour montrer que vos tests ont passé. L’enregistrez comme
4-unit-test.pngdans le dossier “captures”.
- Créez une copie de ce fichier et nommez-le
-
Depuis JEP 463 (pleinement intégré aux outils Java22+) ↩